专栏:数据结构
个人主页:HaiFan.
专栏简介:开学数据结构,接下来会慢慢坑新数据结构的内容!!!!
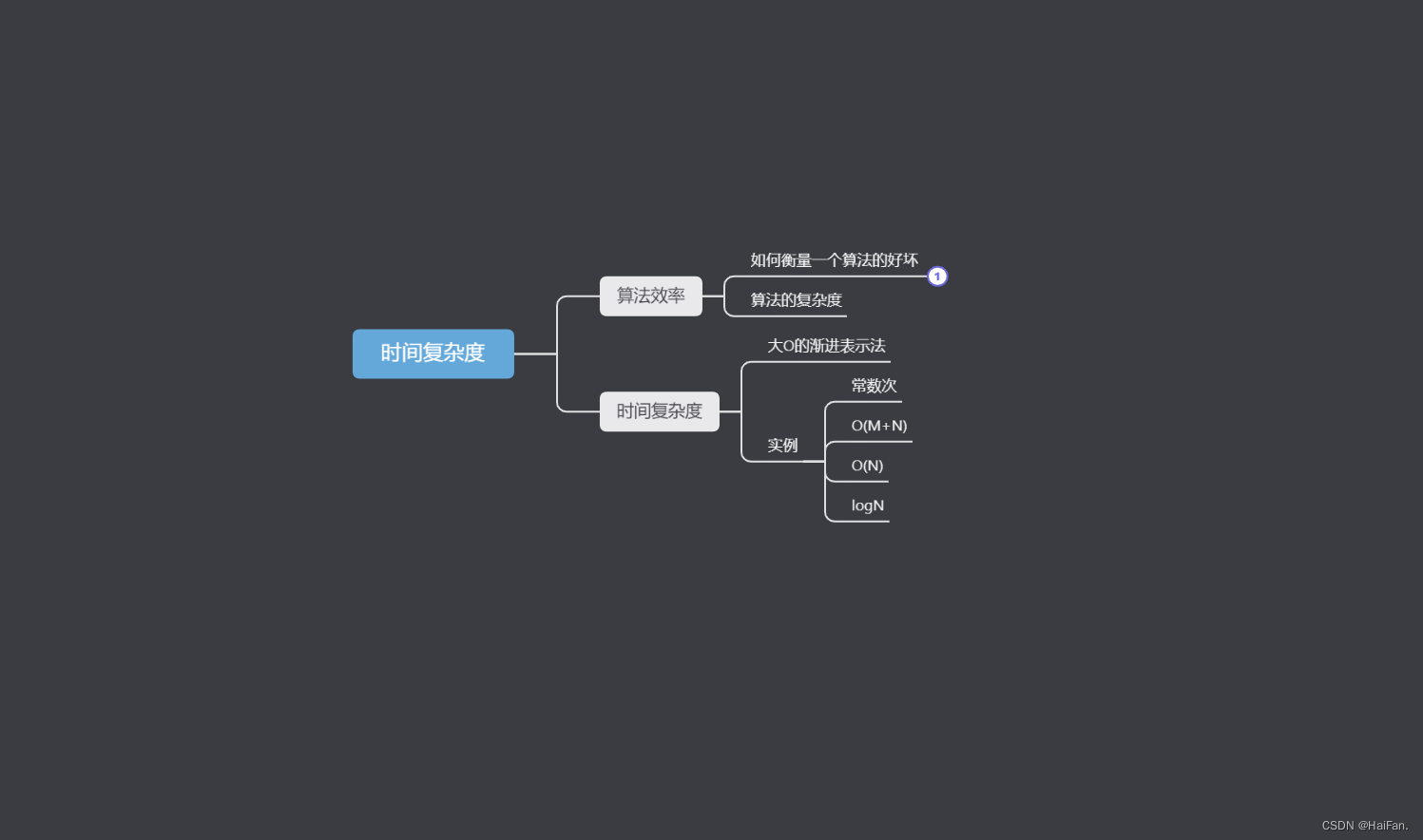
时间复杂度
- 前言
- 1.算法效率
- 1.1如何衡量一个算法的好坏
- 1.2算法的复杂度
- 2.时间复杂度
- 2.1大O的渐进表示法
- 2.2实例
- 1.常数次
- 2.O(M+N)
- 3.O(N)
- 4.logN
前言
什么是数据结构
数据结构是计算机存储,组织数据的方式,指相互之间存在一种或多种特定关系的数据与元素的集合
什么是算法
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为 输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果
1.算法效率
1.1如何衡量一个算法的好坏
比如以下的算区间和的代码
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N];
int s[N];
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
}
while (m--)
{
int l, r;
cin >> l >> r;
int sum = 0;
for (int i = l; i <= r; i++)
{
sum += a[i];
}
cout << sum << endl;
}
for (int i = 1; i <= n; i++)
{
s[i] = s[i - 1] + a[i];
}
return 0;
}
实现这个区间和很简单,代码也很简洁,但是,简洁一定好吗?如何衡量代码的好与坏呢?
1.2算法的复杂度
举个例子:
小兰写了一个冒泡排序
小张写了一个快速排序
小兰和小张执行同一组数据,小兰花了3s,小张花了5s。
这样能说明冒泡排序的效率比快速排序的效率高吗?
答案是:不能的。
算法在编写成可执行程序后,运行时需要耗费时间资源和空间资源。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要是用来衡量一个算法的运行快慢,
空间复杂度主要是用来衡量一个算法运行所需要的额外空间。
2.时间复杂度
时间复杂度:在计算机科学中,算法的时间复杂度是一个函数,他定量描述了该算法的运行时间,一个算法执行所耗费的时间,从理论上说是不能算出来的,只有把程序放在机器上跑起来,才知道,但是每个代码都需要进行一次测试吗?虽然可以,但会很麻烦,所以就有了时间复杂度这个分析方式,一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int ret = 0;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
ret++;
}
}
for (int i = 1; i <= n; i++)
{
ret++;
}
int m = 100;
while (m--)
{
ret++;
}
cout << ret;
return 0;
}
那么,这个代码中的ret共执行了多少次呢?
在代码开始,有一个双重循环,这个时候,ret++就执行了n*n次,后面又有一个循环,这个时候ret++执行了n次,最后又执行了m次ret++;
我们可以推出ret的次数:
F(n) = n*n + n + m
m是一个常数,表达式可以写成
F(n) = n * n + n + 100
- n = 10 F(n) = 100+10+100=210
- n = 100 F(n) = 100*100+100+100=1200
依次类推,当n特别大的时候,得到的函数值也是特别大的。
实际中,我们计算时间复杂度时,其实不一定要算执行次数,只需要计算大概执行次数,这就需要使用大O的渐进表示法
2.1大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法
- 用1来取代运行时间中的所有加法常数
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是1,则去除与这个项目相乘的常数,得到的结果就是大O阶
使用大O阶表示上面代码的时间复杂度:
O(N^2)
大O的渐进表示法去掉了那些对结果影响不大的项。
有些算法的时间复杂度存在最好,平均和最坏情况
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界) 例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
2.2实例
1.常数次
#include <iostream>
using namespace std;
int main()
{
int cnt = 0;
for (int i = 1; i <= 100; i++)
{
cnt++;
}
cout << cnt;
return 0;
}
这个代码非常的简单,时间复杂度也很好求,因为就一个循环,并且是常数次,所以时间复杂度就是O(1)
O(1)不是代表一次,而是常数次
2.O(M+N)
#include <iostream>
using namespace std;
int main()
{
int N;
int M;
cin >> N >> M;
for (int i = 0; i < N; i++)
{
;
}
for (int i = 0; i < M; i++)
{
;
}
return 0;
}
这个代码是两个循环,第一个循环次数是N次,第二个循环次数是M次,那么时间复杂度就是O(M+N)。
值得注意的是,如果M和N相等,那么时间复杂度就是O(N)
如果不相等,就要写成O(N+M)
3.O(N)
#include <iostream>
using namespace std;
int main()
{
int N;
cin >> N;
int cnt = 0;
for (int i = 0; i <= N * 2; i++)
{
cnt++;
}
cout << cnt;
return 0;
}
循环次数是N*2,时间复杂度就是O(N)把N前面的2给省略。
4.logN
二分查找又叫折半查找,
int l = 0;
int r = n - 1;
int mid = l + r >> 1;
while (l < r)
{
mid = l + r >> 1;
if (a[mid] >= x)
{
r = mid;
}
else
{
l = mid + 1;
}
}
二分时间复杂度最好的情况就是第一次就找到了:O(1)
最坏情况:O(logN)(以2为底)
在以2为底的对数中,一般可以写成logN,其他的不能省略
二分的最坏情况时间复杂度为什么是logN呢?
因为每次查找都会缩小区间,查找几次,就除多少个2
N/2/2/2…/2=1
2^x=N
x=logN