反悔贪心
贪心是指直接选择局部最优解,不需要考虑之后的影响。
而反悔贪心是在贪心上面加了一个“反悔”的操作,于是又可以撤销之前的“鲁莽行动”,让整个的选择稍微变得“理智一些”。
于是,我个人理解,反悔贪心是对于某些直接贪心无法解决的问题的一种“救场策略”。当然如果反悔贪心都贪不动当我没说。
不妨先来看一个有无数种做法的问题:
给你一个序列 a 1 , a 2 , . . . , a n a_1,a_2,...,a_n a1,a2,...,an,从中选出 k k k 个使得选中值的和最大,要求不进行排序。
显然如果可以排序的话,这道题就是非常简单的了。
但是我们这时候从另一个角度来考虑这个问题,给出一种相对奇怪的做法,讲完你大概就知道什么是反悔贪心了!
不妨设 a = { 1 , 7 , 3 , 2 , 8 , 4 , 6 , 5 } , k = 3 a=\{1,7,3,2,8,4,6,5\},k=3 a={1,7,3,2,8,4,6,5},k=3。然后再设定一个集合 S = ∅ S = \emptyset S=∅,表示目前选中了那些数字。
我们看到 1 1 1 这个数字,因为 ∣ S ∣ = 0 < k |S|=0 < k ∣S∣=0<k,所以目前来说,选择当前数字肯定比不选择好一些。所以 S = { 1 } S=\{1\} S={1}。
看到 7 7 7 这个数字,因为 ∣ S ∣ = 1 < k |S|=1 < k ∣S∣=1<k,所以还是可以选。 S = { 1 , 7 } S=\{1,7\} S={1,7}。
3 3 3 同理,因为 ∣ S ∣ = 2 < k |S| =2 < k ∣S∣=2<k,所以 S = { 1 , 3 , 7 } S=\{1,3,7\} S={1,3,7}。
看到 2 2 2 这个数字,因为前面已经选择了恰好 k k k 的数字,所以不能直接加进去(否则就 ∣ S ∣ = k + 1 |S| = k+1 ∣S∣=k+1 就违法了),如果非要加的话一定要丢掉一个数字。
显然这个时候因为 1 < 2 1<2 1<2,把 1 1 1 丢掉把 2 2 2 加进来一定更优。于是 S = { 2 , 3 , 7 } S=\{2,3,7\} S={2,3,7}。
遇到 8 8 8,最好的选择显然是把 2 2 2 丢掉把 8 8 8 加进来,$S={3,7,8}$。
遇到 4 4 4,把 3 3 3 替代为 4 4 4, S = { 4 , 7 , 8 } S=\{4,7,8\} S={4,7,8}。遇到 6 6 6,把 4 4 4 替代为 6 6 6, S = { 6 , 7 , 8 } S=\{6,7,8\} S={6,7,8}。
遇到 5 5 5,发现再也没有什么东西可以替代掉的了,因为最小的 6 6 6 都大于 5 5 5,替换掉显然更劣。
最终, S = { 6 , 7 , 8 } S=\{6,7,8\} S={6,7,8},发现这的确是最大值。
上面的过程,应该就已经把反悔贪心的策略讲清楚了。
说白了,反悔贪心的思想是:一开始贪心选择选项,一旦发现某个阶段选不了了,就考虑从已选的选项集合中( S S S),丢掉一些“最差”的选择并以此来替代掉。
这里介绍一个易错点:已选的选项集合中,一定是要保证随着从左到右依次考虑越来越优,一定不可以为了眼前把这个选项加进去而牺牲更多的东西。
前面的贪心和后面丢掉“最差的选择”,就体现出来了反悔贪心中的“贪心”。
“丢掉”弱选择并替换掉的过程,就体现出来了反悔贪心中的“反悔”。
但是,反悔贪心不是想用就能用的,毕竟我以前说过“如果反悔贪心都贪不动当我没说”。它是有使用条件的。
它需要支持快速维护加入和删除选择之后的结果,因为反悔贪心主要就是:一开始疯狂往集合里面加东西。后面从集合里面删东西,并加上更优的东西。
举一个例子:例如一个问题中间的选项是环环相扣的,如果你选择了这个选项的时候,它会对你的整个值造成巨大的影响。如果你无法很快速地维护这些影响,这个问题就没法用反悔贪心做了。
那么这个东西怎么实现呢?
很明显,这个东西不可能会有一个具体的模板,因为贪心是一种思想,反悔贪心也是如此。
大致给出一个实现方向:一般都是使用优先队列存储选择,使用其他变量更新当前选择策略的结果以达到快速维护。
CF1526C2 Potions (Hard Version)

注意这里是子序列,我不会说是谁这道题把子序列看成了子串导致没做出来。
举个例子,例如 A = { 4 , − 4 , 1 , − 3 , 1 , − 3 } A=\{4,-4,1,-3,1,-3\} A={4,−4,1,−3,1,−3},答案为 5 5 5,因为我们可以选择 { 4 , 1 , − 3 , 1 , − 3 } \{4,1,-3,1,-3\} {4,1,−3,1,−3},其前缀和为 { 4 , 5 , 2 , 3 , 0 } \{4,5,2,3,0\} {4,5,2,3,0}。
因为这个东西贪心显然不可做,所以考虑反悔贪心。
从左到右依次考虑当前值 x x x,而且设当前选择的数的序列前缀和为 s u m sum sum。
如果 x ≥ 0 x \ge 0 x≥0,显然加入之后肯定更优,更新 s u m sum sum。
如果 x < 0 x <0 x<0,那么还需要分类讨论一下:
-
1.如果 x < 0 x<0 x<0 且 s u m + x ≥ 0 sum+x \ge 0 sum+x≥0:直接加入,更新 s u m sum sum。
-
2.如果 x < 0 x<0 x<0 且 s u m + x < 0 sum+x < 0 sum+x<0:这时候就有两个选择了,一种是加入,一种是不加入。
-
如果这个时候选择了加入,则一定要将其他小的负数值弹出来,使得加入这个数之后和仍然 ≥ 0 \ge 0 ≥0。如果怎么样删除都不能使得加入这个数之后 ≥ 0 \ge 0 ≥0,则不加。如果可以删除但是删除了 ≥ 2 \ge 2 ≥2 个数,显然还会更劣,也要选择不加入。
-
如果不加入,则不变。
-
因为要删除也是删除负数值,不会使得任意前缀和减少。所以如果加入前合法,加入后依然合法。
实现方式与思路略有不同,但主体是一样的。
#include <bits/stdc++.h>
using namespace std;
const int N = 200010;
int a[N];
int n;
priority_queue<int, vector<int>, greater<int> > q;
int main() {
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i];
int sum = 0;
for (int i = 1; i <= n; i++) {
if (sum + a[i] >= 0) {//直接加
q.push(a[i]);
sum += a[i];
continue;
}
if (q.empty())
continue;
sum += a[i];
sum -= q.top();
if (sum >= 0) {
q.pop(), q.push(a[i]);
continue;
} else
sum -= a[i], sum += q.top();
}
int cnt = 0;
while (!q.empty())
cnt++, q.pop();
cout << cnt << endl;
return 0;
}
CF1185C2 Exam in BerSU (hard version)

首先,对于每一个询问,要求的是其被选中,但是如果该值被选中的话又可能会影响后面的结果。怎么办呢?
我们观察到一个很重要的东西: m ≤ 100 m \le 100 m≤100。这意味着什么???
由于值小于等于 100 100 100,所以单次计算最多会在集合中丢掉 100 100 100 个值。
那么就可以暴力计算这个答案,算完答案再把丢掉的选项加回来,然后再考虑当前的值要不要留下。
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int n, m;
int a[N];
priority_queue<int> q;
stack<int> x;
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++)
cin >> a[i];
int sum = 0, num = 0;//记录删除的数字数量
for (int i = 1; i <= n; i++) {
if (sum + a[i] <= m) {
sum += a[i];
q.push(a[i]);
cout << num << " ";
} else {
while (sum + a[i] > m) {
sum -= q.top();
num++;
x.push(q.top());
q.pop();
}//删除
cout << num << " ";
while (!x.empty()) {
sum += x.top();
num--;
q.push(x.top());
x.pop();
}//还原
if (q.top() > a[i]) {
sum -= q.top();
q.pop();
sum += a[i];
q.push(a[i]);
}//考虑增加
num++;
}
}
return 0;
}
P2949 [USACO09OPEN] Work Scheduling G
你有 n n n 个工作(每一个工作需要一整天完成),第 i i i 个工作若在前 t i t_i ti 天完成,可以获得酬劳 p i p_i pi,问最多能得到多少酬劳。
这是一个很简单的 trick 了。
首先,可以按照完成截止天数( t i t_i ti)排序。
然后依次选择,如果已经选择工作的数量等于截止天数(那么就冲突了),则考虑是否可以反悔其中一项工作。
这个反悔的工作显然就是目前已经选出来的 p i p_i pi 最小的工作(这样可以获得更多的酬劳,当然如果这个工作都比目前的工作的酬劳高,那么还不如不反悔)。然后这道题就做完了。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n;
const int N = 100010;
struct node {
int d, p;
bool operator <(const node &a)const {
return d < a.d;
}
} a[N];
priority_queue<int, vector<int>, greater<int> > q;
signed main() {
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i].d >> a[i].p;
sort(a + 1, a + n + 1);
int num = 0;
for (int i = 1; i <= n; i++) {
if (a[i].d == num) {
if (q.top() > a[i].p)
continue;
else
q.pop(), q.push(a[i].p);
} else
num++, q.push(a[i].p);
}
int sum = 0;
while (!q.empty())
sum += q.top(), q.pop();
cout << sum << endl;
return 0;
}
贪心调整法
贪心调整法同样的是依靠的数学,和数学的局部调整发有着异曲同工之妙。
贪心调整法是这样的:尝试交换两个值,如果交换之后的答案更优,我们就可以这样一直交换,最终得到最好的结果。
就是不等式的分析。
先看题。
P5963 [BalticOI ?] Card 卡牌游戏
现在有一个算式:-?+?-?+?……(一共有 n n n 个?),现在你有 n n n 张卡片,每张卡片有两个值 a i , b i a_i,b_i ai,bi。要求将卡片放入 ? 的位置并选择其中一个值,要求算式结果最小。
这种最优化的题目,可以想到使用 dp 和 贪心。但是 dp 的复杂度还是太高了,故不采用。
设目前有一个加号位和一个减号位,有两个卡片
A
,
B
A,B
A,B 填进去了。则为了使答案最小,有两种方案: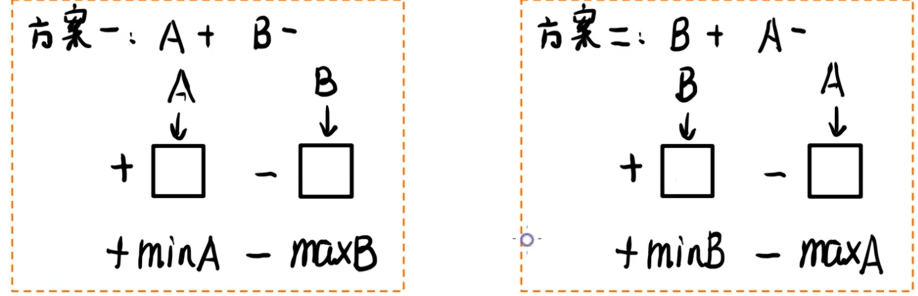
这东西全是未知数,但是这并不妨碍我们提出一个假设:假设方案一优于方案二,这回是什么样子。

整理一下,得到一个很神奇的东西:
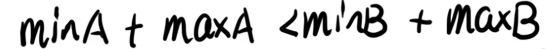
这样是不是就可以得出:如果 A A A 在加号位、而 B B B 在减号位更加优秀的话,则一定满足 m i n A + m a x A < m i n B + m a x B minA + maxA < minB+maxB minA+maxA<minB+maxB。
然后想想,**这东西是不是就是我们的贪心策略啊?**我们只要按照这个不断地交换,不断地交换,最终就可以得到答案了。
贪心策略:两数之和最小的排在加号位,其余的排在减号位。
已经确定了顺序,则如果加号位的地方取两个值中间的最小值,减号位的地方取两个值中间的最大值,那不就可以了吗。
最终根据样例得到结果,正好是样例答案,也印证了我们这样是正确的:
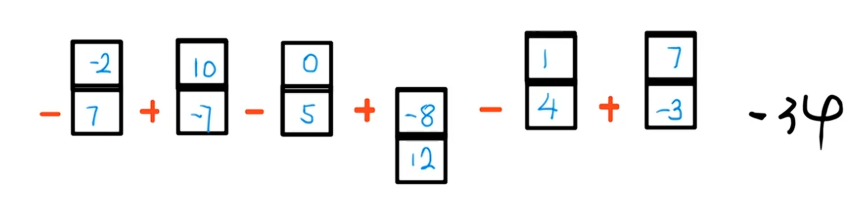
很有趣吧???这个东西乍一看完全和两个数的和没有关系,但是最终却不偏不倚的推到了这里。
就是纯数学。
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 530010;
struct node {
int a, b;
bool operator<(const node &x)const {
return (a + b) < (x.a + x.b);
}
} a[N];
int n;
signed main() {
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i].a >> a[i].b;
sort(a + 1, a + n + 1);
int ans = 0;
for (int i = 1; i <= n / 2; i++)
ans += min(a[i].a, a[i].b);
for (int i = n / 2 + 1; i <= n; i++)
ans -= max(a[i].a, a[i].b);
cout << ans << endl;
return 0;
}
P1012 [NOIP 1998 提高组] 拼数
n n n 个数,问如何拼在一起使得结果最大。
考虑故技重施,使用贪心调整法:
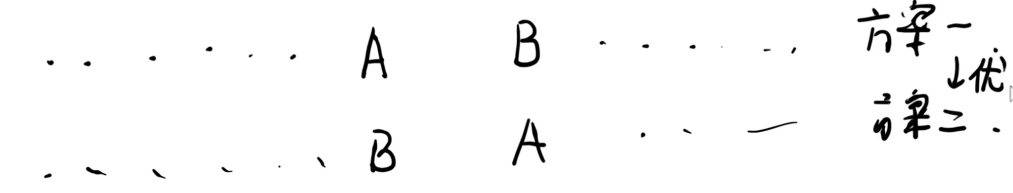
假设方案一优于方案二。
显然,在交换 A , B A,B A,B 之前和之后,左右两边的东西都是一样的。
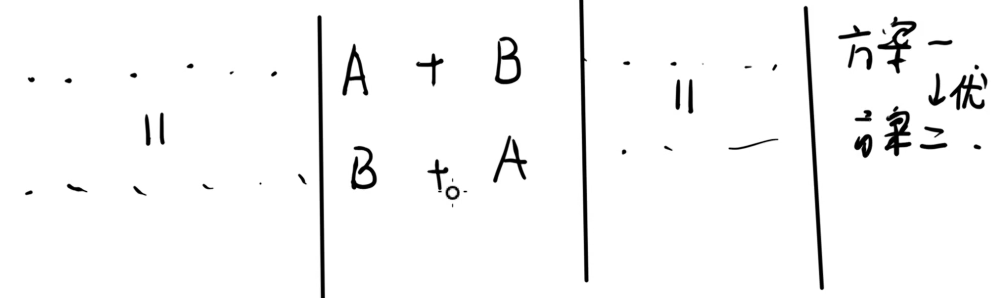
于是就变成了比较 A + B A+B A+B 和 B + A B+A B+A 两个字符串,其中 + + + 表示字符串拼接。
因为方案一优于方案二,所以 A + B > B + A A+B> B+A A+B>B+A。于是这道题就做完了。
你可能会问:这还没做完啊!因为这里还没有非常明确的排序方式。
但是这个东西可以作为 比较方式,剩下的就交给我们伟大的 sort 来解决了。
#include <bits/stdc++.h>
using namespace std;
string s[21];
int n;
bool cmp(const string &a, const string &b) {
return (a + b > b + a);
}
int main() {
cin >> n;
for (int i = 1; i <= n; ++i)
cin >> s[i];
sort(s + 1, s + n + 1, cmp);
for (int i = 1; i <= n; ++i)
cout << s[i];
return 0;
}
#P1080 [NOIP 2012 提高组] 国王游戏

考虑使用贪心调整法。
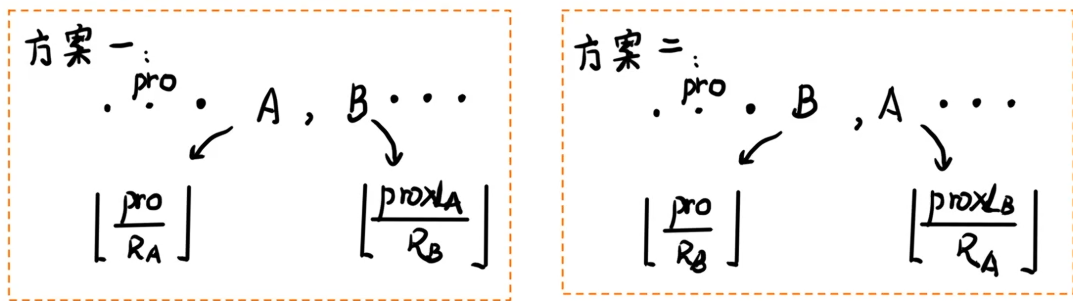
可以发现他们前面和后面的那一部分的得分依然没变。
假设方案一优于方案二,就可以得到:
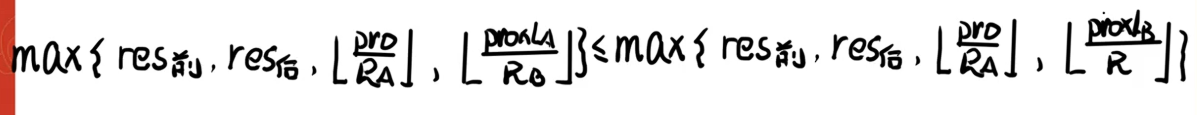
发现 r e s 前 res_前 res前 和 r e s 后 res_后 res后 是可以消去的,如果他们有一个承包了最大值,则也可以说方案一优于方案二。如果其他两项承包了最大值, r e s 前 res_前 res前 和 r e s 后 res_后 res后 就是完全没有意义的。
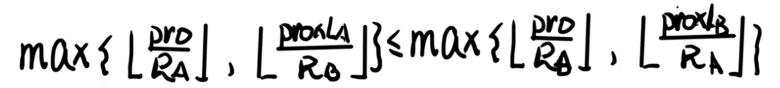
然后发现他们都有一个 p r o pro pro,而 p r o pro pro 是整数,不影响我们的向下取整。我们能不能将这个恶心的 p r o pro pro 给除掉呢?
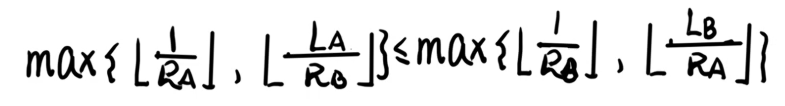
然后又发现因为 R a , R b R_a,R_b Ra,Rb 都是正整数,所以 ⌊ 1 R a ⌋ = ⌊ 1 R b ⌋ = 0 \lfloor \frac{1}{R_a} \rfloor = \lfloor \frac{1}{R_b} \rfloor = 0 ⌊Ra1⌋=⌊Rb1⌋=0,显然这样进行 max \max max 是毫无意义的。式子变为:
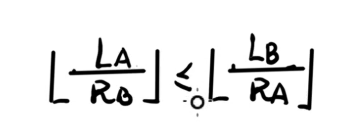
这里可以把向下取整拆掉,因为必须要满足下面的式子才能满足上面的式子:
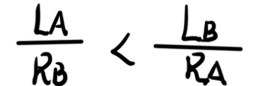
然!后!通分得到 L A × R A < L B × R B L_A\times R_A < L_B \times R_B LA×RA<LB×RB。然后就得到了我们的贪心策略。
是不是很魔幻?我们就是一路过五关斩六将,先把没有用的东西消掉,然后再考虑消去 max \max max 和 ⌊ ⌋ \lfloor \rfloor ⌊⌋ 这两个加工操作。
可能你会很懵逼:为什么这样的一个纯数学推导就可以得到正确的思路,为什么推出来这样一个局部调整策略就可以作为全局贪心的策略了??
可以感性理解一下,当任意两项没有满足我们贪心调整法给定的偏序关系,那么还是可以通过交换使得结果更优,那么不能调整的局面就是按照偏序关系排序的结果,也一定没有更好的解。
贪心调整法有利有弊,和反悔贪心一样。也有自己的使用条件。
首先,最终推出来的式子一定是满足偏序关系。要不然就没法排序。
偏序关系的意思是,对于任意两个不同的项,都一定要分出大小。
第二,还记得我们以前提到的东西吗:“可以发现他们前面和后面的那一部分的得分依然没变。”这也正是它使用的环境,否则就不可以使用了。因为你交换之后,不止有这两个东西的值发生了改变,其他也发生了改变。
小经验:如果不知道怎么进行不等式的分析,能不能直接把不等式作为贪心策略丢进去?
**回答:可以,但很不推介!!!**因为你无法知道这个不等式是不是满足偏序关系,还是需要进一步的推理。
直接采用可能是赌命行为。
P2123 皇后游戏
题面和国王游戏是差不多的,但是它的得分数变成了这个样子:
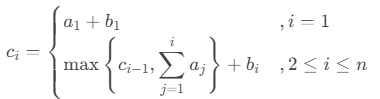
使用贪心调整法:

假设方案一比方案二更优:

然后套路地,消掉相同的部分:
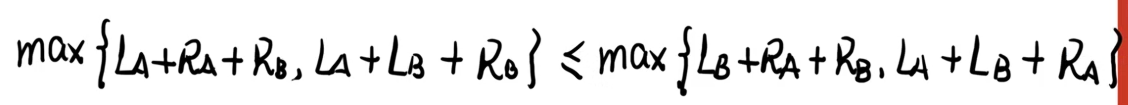
然后发现又有很多相同的,考虑将所有的项减去 L A + R A + R B + L R L_A+R_A+R_B+L_R LA+RA+RB+LR。
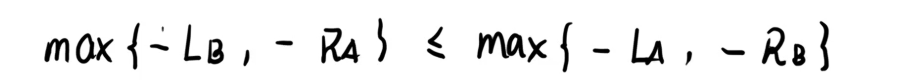
同时取相反数:

这样不就得出来贪心策略了吗?
代码就是得到顺序之后直接模拟即可。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int t;
int n;
const int N = 20010;
struct node {
int a, b;
bool operator<(const node &x)const {
return min(b, x.a) > min(a, x.b);
}
} a[N];
int c[N];
signed main() {
cin >> t;
while (t--) {
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i].a >> a[i].b;
sort(a + 1, a + n + 1);
int ans = 0, sum = 0;
for (int i = 1; i <= n; i++) {
sum += a[i].a;
if (i == 1) {
c[i] = a[i].a + a[i].b;
ans = c[i];
continue;
}
c[i] = max(c[i - 1], sum) + a[i].b;
ans = max(ans, c[i]);
}
cout << ans << endl;
}
return 0;
}
但是,我们一交,发现这样只能达到 80pts,到底是什么问题呢?
这就启发我们这样的式子不是对的。
我们观察我们最后的出来的这个式子,它真的满足偏序关系吗?它会不会影响到后面的结果?
这样确实满足偏序关系,但是不严谨。
有一个很恼人的点:当 min { L B , R A } = min { L A , R B } \min\{L_B,R_A\} = \min\{L_A,R_B\} min{LB,RA}=min{LA,RB} 时, A A A 在前面或者 B B B 在前面的结果可能是不一样的!
而且还不止这一个问题,这样也会影响后面的结果。这道题是紫就紫在这里。
这个时候,我们需要在式子的上面进行修改,使得这个式子变成偏序的,而且也不会影响后面的结果。
这里采用了洛谷题解的做法。
我们再观察一下这个式子。
可以发现,这个式子是不是成立,和 a , b a,b a,b 的大小有关。不妨将所有的分为三大类,分类讨论:
- 当 L A < R A L_A < R_A LA<RA 而且 L B < R B L_B < R_B LB<RB 而且 L A ≤ R A L_A \le R_A LA≤RA 时,这个式子就相当于按照 L L L 升序排序。
- 当 L A = R A L_A = R_A LA=RA 而且 L B = R B L_B = R_B LB=RB 时,就可以随便排。
- 当 L A > R A L_A > R_A LA>RA 而且 L B > R B L_B > R_B LB>RB 而且 R A ≥ R B R_A \ge R_B RA≥RB 时,这个式子就相当于按照 R R R 降序排序。
同一个类别的排序处理完了,考虑处理类别之间的排序。
发现第一类在第二类前面,第二类在第三类前面一定是可以满足要求的。
对于这个符号,我们有很好的表示方式:设 d A = L A − R A ∣ L A − R A ∣ d_A = \frac{L_A - R_A}{|L_A-R_A|} dA=∣LA−RA∣LA−RA,当 d A = − 1 d_A = -1 dA=−1 时为第一类,当 d A = 0 d_A=0 dA=0 时为第二类,当 d A = 1 d_A=1 dA=1 时为第三类。
于是可以得到最终的排序条件:先按照 d d d 排序,处理类别之间的排序;然后再按照上面给出的排序。
就这样,我们成功的将一个式子化成了三个式子,也保证了正确性。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int t;
int n;
const int N = 20010;
struct node {
int a, b, d;
bool operator<(const node &x)const {
if (d != x.d)
return d < x.d;
if (d == -1)
return a < x.a;
else if (d == 1)
return b > x.b;
}
} a[N];
int c[N];
signed main() {
cin >> t;
while (t--) {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i].a >> a[i].b;
if (a[i].a != a[i].b)
a[i].d = (a[i].a - a[i].b) / (abs(a[i].a - a[i].b));
else
a[i].d = 0;
}
sort(a + 1, a + n + 1);
int ans = 0, sum = 0;
for (int i = 1; i <= n; i++) {
sum += a[i].a;
if (i == 1) {
c[i] = a[i].a + a[i].b;
ans = c[i];
continue;
}
c[i] = max(c[i - 1], sum) + a[i].b;
ans = max(ans, c[i]);
}
cout << ans << endl;
}
return 0;
}








![MySQL基础 [三] - 数据类型](https://i-blog.csdnimg.cn/direct/286af1eb96cd41e6bd8d4458c4fc5eeb.png)