网络原理
文章目录
- 1. 前言:
- 2. 应用层
- 2.1 XML
- 2.2 json
- 2.3 protobuffer
- 3. 传输层
- 3.1 UDP
- 3.1 TCP
- 4. TCP 内部的工作机制 (重点)
- 1. 确认应答
- 2.超时重传
- 3. 连接管理
- 3.1 建立联系 :三次握手
- 3.2 断开连接 : 四次挥手
- 4. 滑动窗口
- 5. 流量控制
- 6. 拥塞控制
- 7. 延时应答
- 8. 捎带应答
- 9. 面向字节流
- 10. 异常情况
1. 前言:
本文主要介绍 TCP / IP 协议栈 这里的关键协议 , 根据对 TCP / IP 等关键协议的 介绍 使对网络通信有更明确的认识 .
下面就按照 TCP/IP 五层网络模型 其中的四层来介绍 (应用层 , 传输层 , 网络层 , 数据链路层)
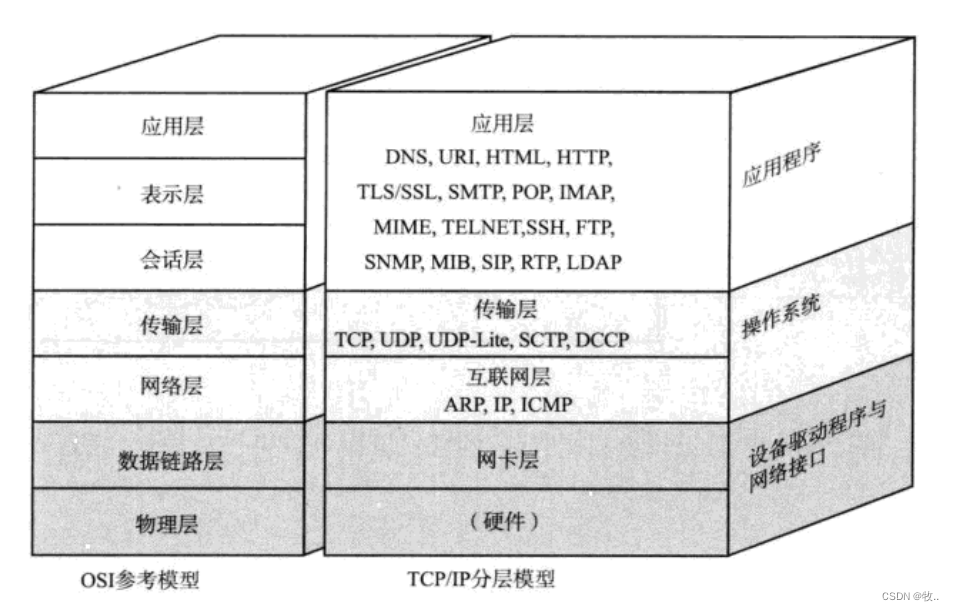
2. 应用层
关于应用层 可以说是和程序猿打交道最多的一层协议 , 我们 很多时候写代码 ,都是涉及到应用层协议的。
在应用层 这里 , 需要我们自定义一个应用层协议 , 此时就好比 武侠小说 里 的自创武功 , 既然能够 自创武功 ,那么肯定这个人是比较厉害的 。
看到这里是不是就慌了呀 , 其实 自定义应用层协议 并不如 武侠小说中自创武功那么困难 , 对于我们自定义应用层协议 是要容易很多的 。
看到这里 是不是就 松了口气 ,嘿 先别松气 , 这里我提出两个问题
1. 为啥我们需要自定义应用层协议 ?
答 : 我们的软件(应用程序) 要解决的业务场景 是错综复杂的 ,不同的公司有不同的业务 , 不同的业务又有不同的流程, 业务复杂 ,
使用层序来解决这个复杂的业务 ,程序也就复杂了。因此很难有一个通用的协议 满足所有的业务需求 , 所以我们就 需要 根据 具体的业务创建对应的协议 。
2. 怎样去进行自定义协议 ?
答 :1. 结合需求 ,分析清楚 , 请求响应 ( 客户端 / 服务器之间 要传递那些信息 )。
举个例子 : 点外卖
查看外卖列表 :
-
请求 : 我们当前所在的位置 , 我们的身份信息 . (需要当前所在位置 是因为 外卖平台可以根据你的位置搜索 附近的商家 , 而 提供身份信息 是因为外卖平台可以根据你的身份信息 ,进行一些智能化推荐 , 推荐你 喜欢吃的 ,常吃的)
-
响应 : 一个列表 , 列表中要有 商家信息 (名称 , 图片 , 距离 / 位置 ,简介 等)
此时 这里查看外卖列表 的 请求 和响应 就分析玩了 , 在来个例子 。
点击某个具体的店铺 , 要显示这个店铺都有啥吃的
-
请求 : 店铺的名字 / id 等 ,
-
响应 : 一个列表 , 列表中 要有 食品的信息 , 名称 , 图片 ,价格 , 简介 , 口味 等
简单的 过一遍流程 : 客户端 点击 店铺 ,将请求 (店铺的名字 , id) 发送给服务器 , 服务器 通过 请求 计算出响应 (对应店铺的信息) , 然后返回给客户端 ,
客户端接收到响应 ,将响应的信息 显示在 页面上 。
另外可以说 , 需求分析 ,就是软件开发中最最重要的环节 ,没有之一 , 虽然 需求分析是产品经理主要的工作 ,但是我们程序猿也得能够分析明白.
第一个 环节 需求 看完 ,下面来看看第二个环节
2.明确传递的信息以什么样的格式来组织
这里可选的方案是很多的 , 举个例子 : 使用文本的方式 ,这也是最简单 , 最朴素的方式 。
文本方式 :约定一下查看外卖列表 的请求 和 响应
-
请求 : 约定请求是一行文本, 字段之间使用
;来分割 =>用户 id ; 地址\n -
响应 : 也使用文本格式 , 响应有多行 , 每一行代表一个商家列表的结果 .
商家名字;商家的图片地址;商家简介;商家地址\n 商家名字;商家的图片地址;商家简介;商家地址\n 商家名字;商家的图片地址;商家简介;商家地址\n 商家名字;商家的图片地址;商家简介;商家地址\n \n
此时我们就通过 文本的方式约定好了请求 和 响应 。
这里进行的约定,目的就是为了让客户端和服务器之间,能够步调一致 , 约定好协议的具体格式内容之后,客户端就能够按照这个格式构造数据并发送,服务器按照这个格式来解析 .
除了文本的方式 ,还有很多其他的方式来约定,具体如何约定还是看自己 。
另外 我们约定的协议的内容(传递的信息) 是和业务相关性特别大的 , 但是协议的数据组织的格式 (传递的格式 , 比如上面的 文本方式) 和业务相关性就没那么大。
正因为关系不那么大 ,在业界 就有大佬发明了一些比较通用的,也被我们广泛使用的数据格式 .
下面就来简单介绍 一些比较典型的用来组织数据的格式 .
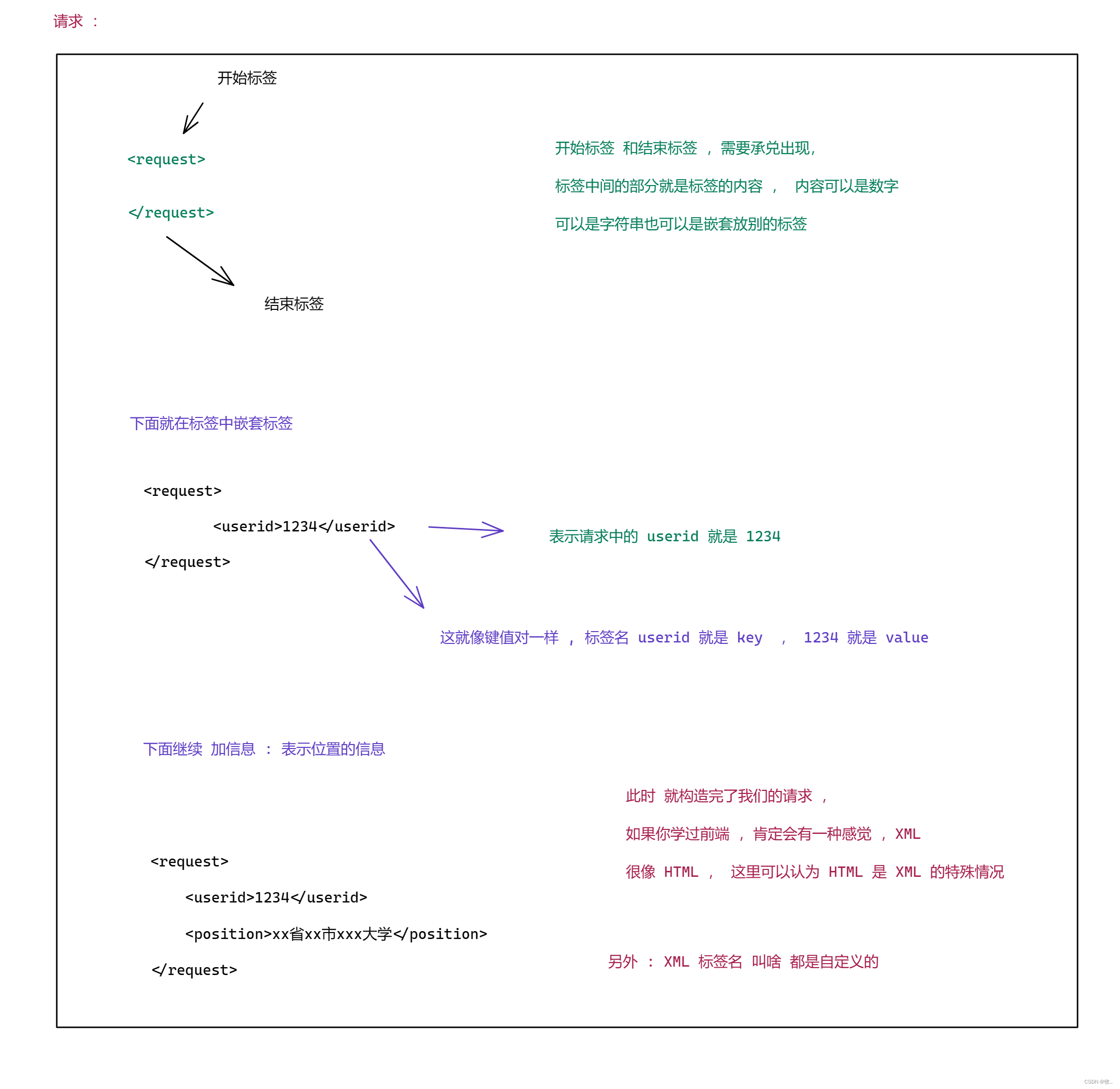
2.1 XML
XML : 标签化的数据组织方式 , 使用标签来表示键值对, 以及树形结构 .
还是通过 : 点外卖中的 查看附近商家 (查看外卖列表) 来举例 :
请求 :
响应 :
<response>
<shops>
<name>湖南牛肉面</name>
<position>位置信息: </position>
<description>广告语: </description>
........
</shops>
<shops>
<name>湖南牛肉面</name>
<position>位置信息: </position>
<description>广告语: </description>
</shops>
......
</response>
2.2 json
先来看 json 如何构造 请求和 响应的 ,还是 对 查看外卖列表 举例 :
请求 :
{
userid:1234,
position:"xxx.xxx.xxx"
}
响应 :
{
shops: [
{
name : "魏家凉皮",
description:"想吃凉皮就吃魏家凉皮",
position:"xxxx.xxxx.xxx",
},
{
name : "xxxx",
description:"xxxxx.xxxx",
position:"xxxx.xxxx.xxx"
},
{
name : "xxxx",
description:"xxxxx.xxxx",
position:"xxxx.xxxx.xxx"
}
]
}
看完 json 格式 构造的请求和响应 , 可以明显感受到 xml 构造的请求和 响应 是比较繁琐的 , 比较啰嗦 , 所以 在 2010 年 后 xml 的 使用 就少了 , 目前我们主
要使用的格式 就是 json , 而 xml 主要作为一些配置文件 ,
总结 : xml 和 json 都是 按照 文本的方式来组织的 , 优点 可读性好 ,用户不需要借助其他工区 , 肉眼就能看到懂数据的含义 。
缺点 : 效率不高 , 尤其是占用较多的网络带宽 , xml 中需要 传很多标签 , json 中 需要传很多的key …
对于我们的 服务器来说 ,最贵的硬件资源 ,不是 cpu 更不是内容 ,而是网络带宽 .
2.3 protobuffer
此时为了 解决 上述 json 和 xml 会传很多 key 和 标签 的 情况 , 谷歌就推出了 protobuffer , 它是以 二进制的表示数据的方式 ,
还是 拿上述的外卖列表 举例 :
protobuffer 就会 针对上述的数据信息 ,通过 二进制的方式进行压缩表示 。
二进制数据的特点也非常明显 就是 肉眼观察不了 (二进制 直接用笔记本打开 ,乱码) , , 同时带来的好处 就是 占用空间小了, 传输的带宽也就降低了.
到此 这些比较典型的用来组织数据的格式就看完了 ,下面来看我们的传输层 , 另外 应用层除了上述自定义协议之外,也有一些大佬已经设计好的现成的协议 ,比如 : HTTP 协议.
3. 传输层
传输层虽然是操作系统内容已经实现好了 , 但是程序猿写代码 ,要调用系统提供的 Socket api 完成网络编程 , socket 就是属于传输层的部分 .
关于传输层 涉及到的协议 , 相比因该比较熟悉就是 UDP 和 TCP 。
在详细说这两个协议之前,这里先来对端口号的内容进行补充
端口号 , 我们之前 都接触过 , 在我们安装 mysql 的时候, 就看到过 ,mysql 默认的端口号就是 3306 .
端口号 起到的效果 就是区分一个主机上具体的应用程序 , 正因如此 使用端口号的要求 就是 在同一个主机上, 一个端口号不能被多个进程绑定 。
比如 : 进程 A 绑定了 3306 , 此时 进程 B 也尝试绑定 3306 ,进程B 绑定操作就会失败 (抛异常 , 这个之前说过)
另外 : 端口号是传输层协议的概念 , TCP 和 UDP 协议报头中都会包含 源端口 和 目的端口
TCP 和 UDP 都是 使用 2个字节 16 个 bit 位来表示的 , 这里就意味着 一个 端口号的 取值范围 是 0 - 65535
(1 个 字节 , 8 个比特位 范围 - 128 – 127 , 2 个字节 16 个比特位 范围 -32768 – 32767 , 4 个字节 32 个比特位 范围: -21亿 – 21亿)
虽说端口号的范围是 0 - 65535 ,但是 我们自己写的程序 ,绑定的端口 得从1024 开始 。
因为 : 0 - 1023 这个 范围的端口 ,称为 “知名端口号/ 具名端口号” , 这些端口号是属于已经分配给了一些知名的广泛使用的应用层序。
如果非要使用 1023 以内的端口 , 也是可以的 (不建议) ,
第一步 : 需要先确定你使用的这个端口确实没有程序在绑定 ,第二步 : 确定你由管理员权限
端口号的内容就补充到这里, 下面先来学习一下 相对简单的 UDP
3.1 UDP
UDP 的特点 : 1. 无连接 2. 不可靠传输 3. 面向数据报 4. 全双工 .
关于 UDP 的特点 在之前的文章就说过 ,这里就不再继续了, 下面来学一下 UDP 的报文结构 .
图一 :
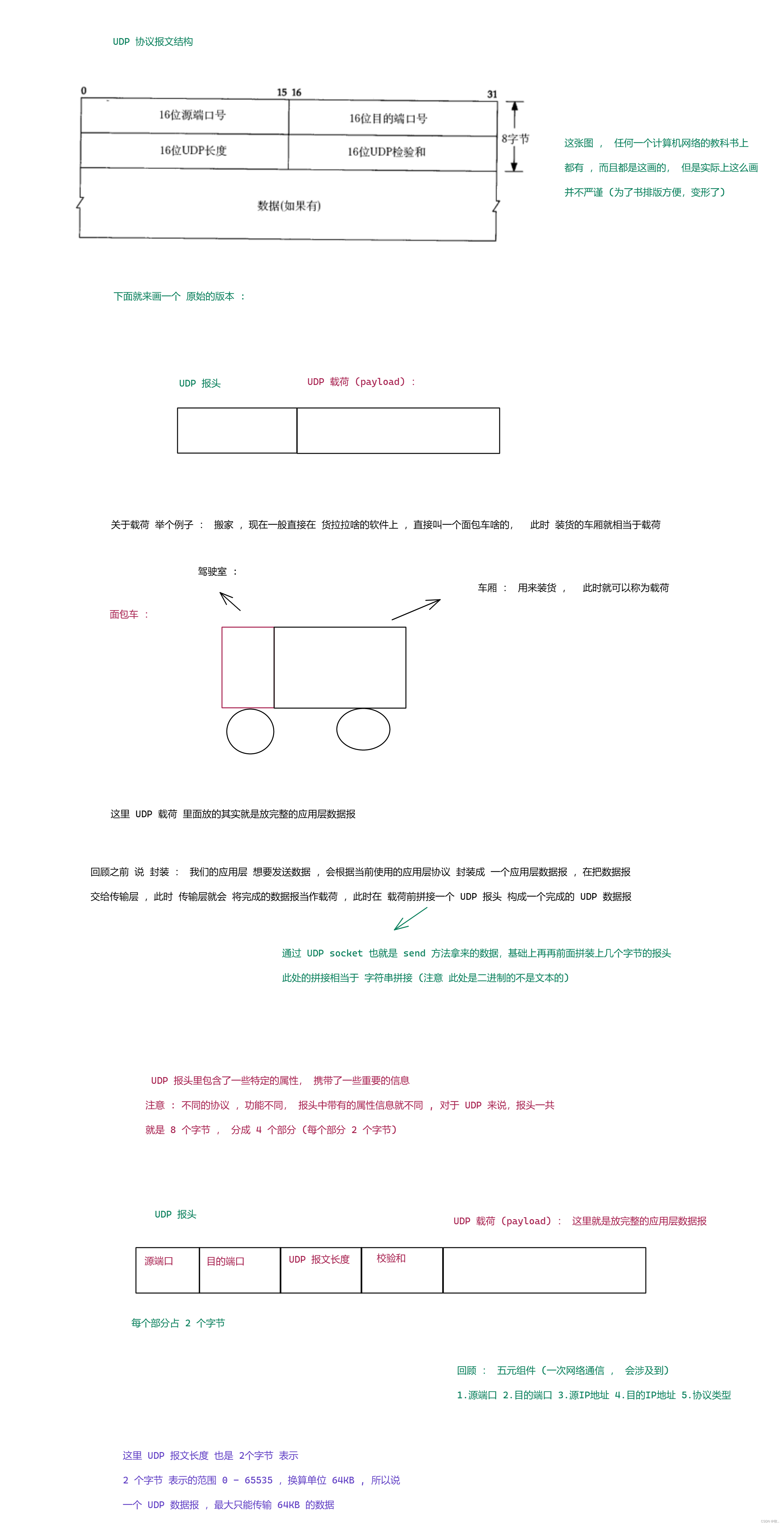
图二 : 报文长度

图三 : 校验和
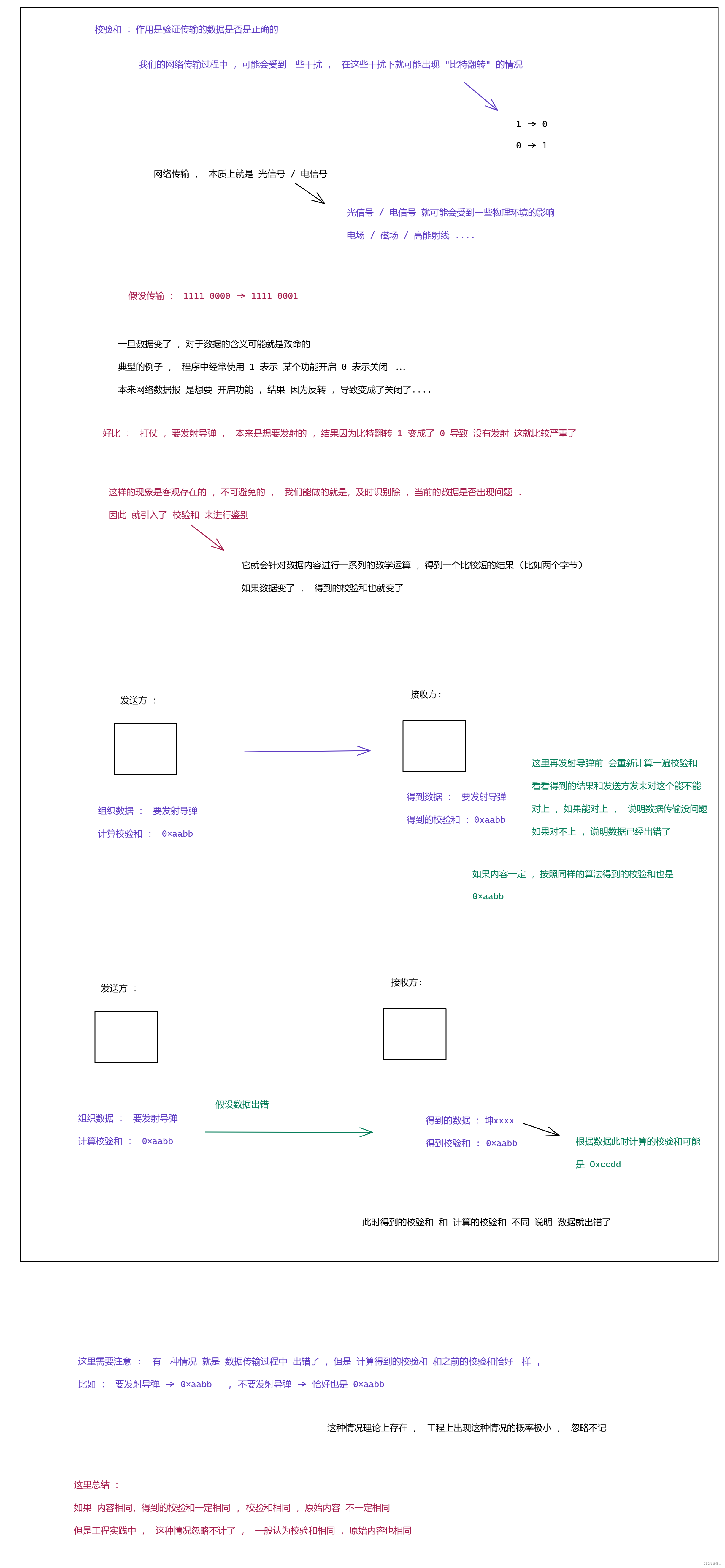
其实在我们的生活中 像校验和这种 是比较常见的 :
比如 : 买菜 ,母亲叫你买菜 ,给你列举出需要购买 菜 如 : 西红柿 , 鸡蛋 , 茄子 , 香菜 最后还特意嘱托了一句 , 是四样菜哦 .
这里的 买四样菜 ,就相当于 简单的校验和 .
此时 买了三样菜 , 根据 这个简单的校验和 就能确定 , 出错了 ,但是当前的这种校验和功能是有限 , 无法针对内容进行校验 ,比如 : 我们将 香菜 买成了 小芹菜 , 就检查不出 , 手上是 4 样 菜 满足校验和 .
正经的校验和 一般会和 内容挂钩 , 基于数据内容算出的校验和 , 内容一变就能发现 。
下面来简单的说一说针对网络传输的数据 ,生成校验和的几种算法 :
1. CRC : 循环冗余校验 ,简单除暴 , 把数据的每个字节 循环往上 累加 , 如果累加溢出了 , 高位就不要了。
使用 CRC 计算校验和 是比较好算的 , 但是校验的效果不是特别理想 , 万一 数据同时变动了 两个 bit (前一个字节少1 , 后一个字节多1
这种) , 就会出现内容变了 ,CRC 没变这样的情况
2. MD5 : 不是 简单相加 ,是有 一些列公式 , 来进行更复杂的数学运算 (数学问题)
关于 MD5 算法的特点 :
-
定长 , 无论你原始数据多长 ,得到的 md5 值都是固定长度 (4 个字节版本 , 8 个字节版本)
-
冲突概率小 , 原始数据哪怕只变动一个地方 ,算出来的 MD5 值 都会 差别 很大 (让MD5 结果 更分散了)
-
不可逆 ,通过原始数据计算 MD5 很容易 , 通过 MD5 还原成原始数据 (找到是那个数据生成这个 MD5) 很难 理论上不可实现 (计算量极大)
MD5 算法 有这些特点 就比较适合做 : 1. 校验和 , 2. 作为 计算 hash值的方式 3.加密
3.SHA1 与 MD5 类似
到此 UDP 就看完了, 下面来看看 TCP , TCP 相比 UDP 重要 且 更加复杂 。
3.1 TCP
TCP 的特点 : 1. 有连接 , 2. 可靠传输 , 3. 面向字节流 , 4. 全双工
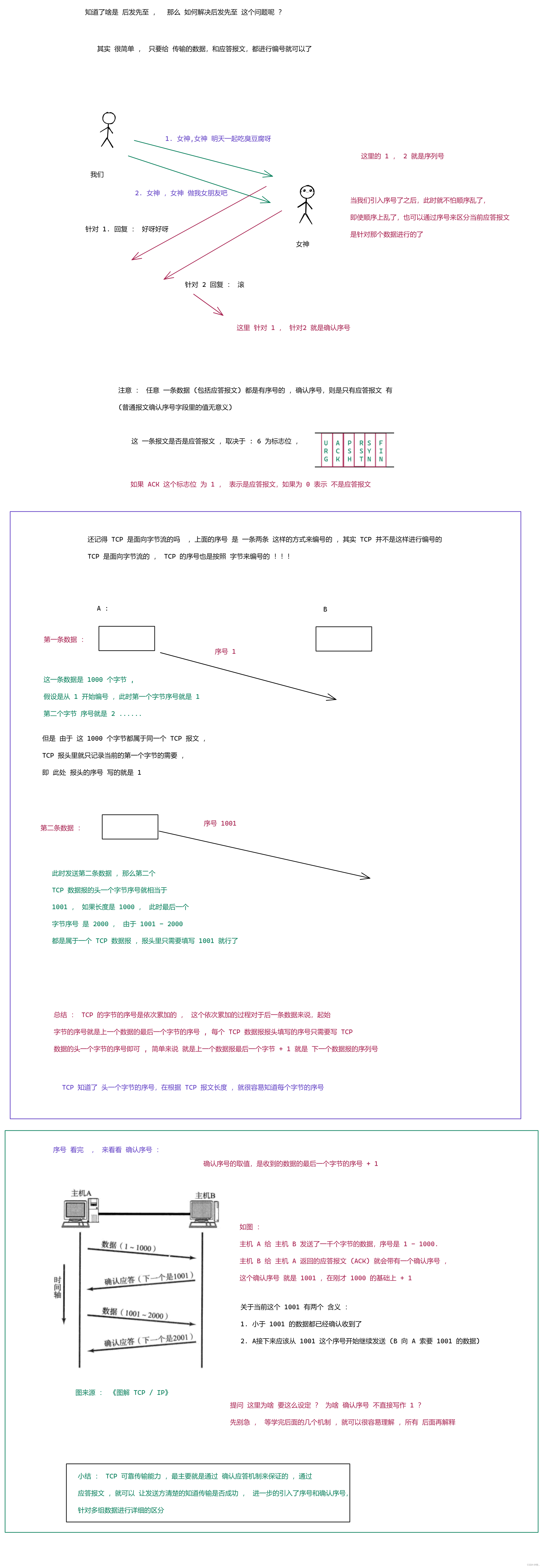
TCP 协议段格式
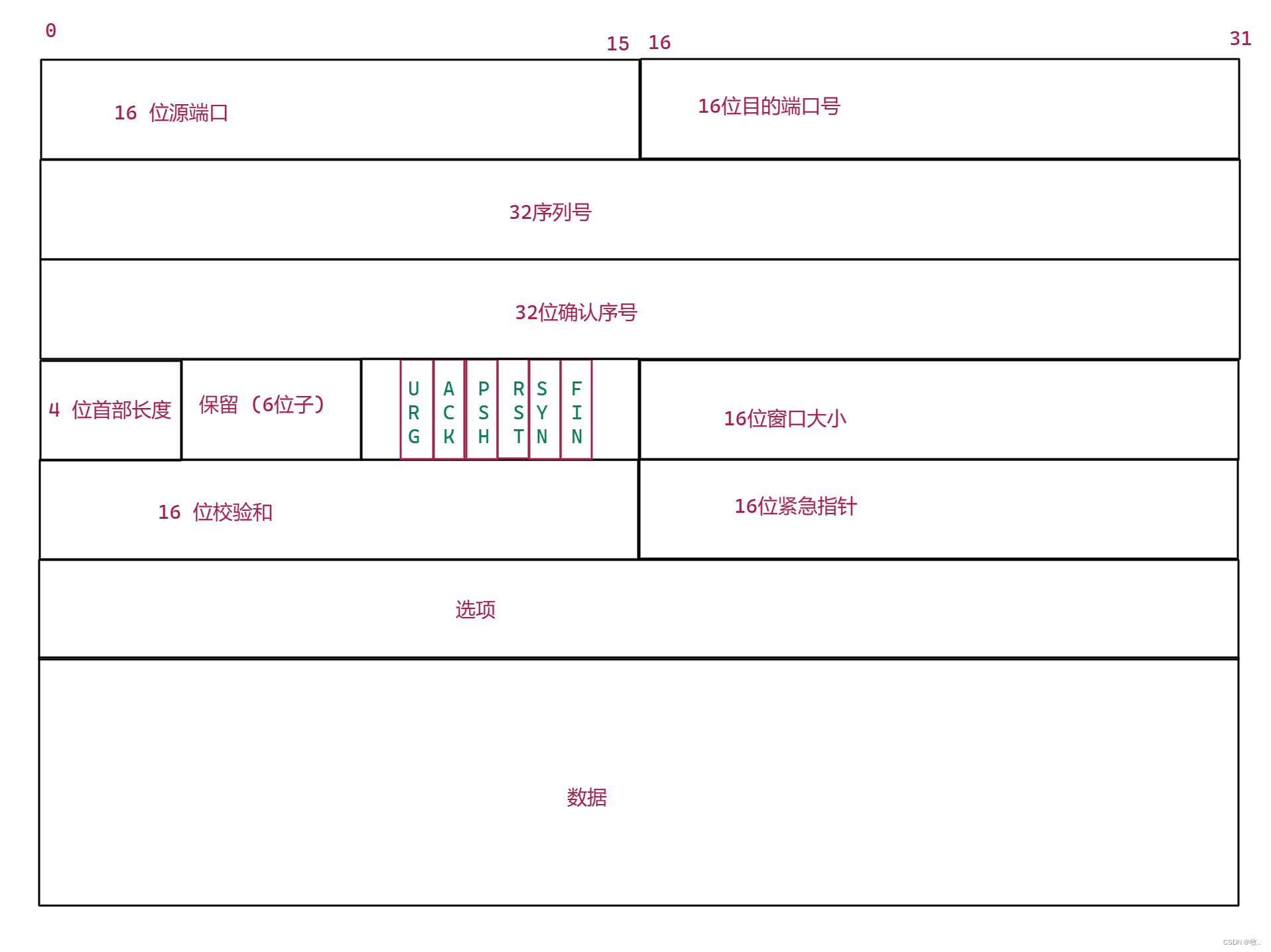
分析 TCP 协议报 :

这里 先留下 32 序列号 , 32 确认序列号 , 16 位窗口大小 , 16 位紧急指针 , 6 个标志位 (URG , ACK , RST , SYN , FIN) 后面再说 .
当前 看 TCP 报头 , 看了一圈 发现 , 看了个寂寞, 仍然有很多东西,我们是看不懂的 .
这里就需要进一步的了解 TCP 后续的工作机制 。
4. TCP 内部的工作机制 (重点)
TCP 是 一个 复杂的协议 ,里面有很多东西很多机制 , 本文主要讨论 TCP 提供的 10个比较核心的机制
1. 确认应答
之前说过TCP 的特点 , 最大的特点就是 可靠传输, 这里提问 TCP 的可靠传输是如何做到可靠的呢?
简单回顾 : 可靠传输 , 可靠 , 不是说 ,发送方百分百能将消息发送给接收方 . ( 如果网线断了就不可能发过去 ) , 尽力而为 , 尽可能的把数据传输过去,同时 如果还是传输不过去,至少能知道。
确认应答 就是 实现 可靠传输 最核心的机制 !!!!
那么啥是 确认应答 呢 ?
举个典型的例子 :
图一 :

图二 :
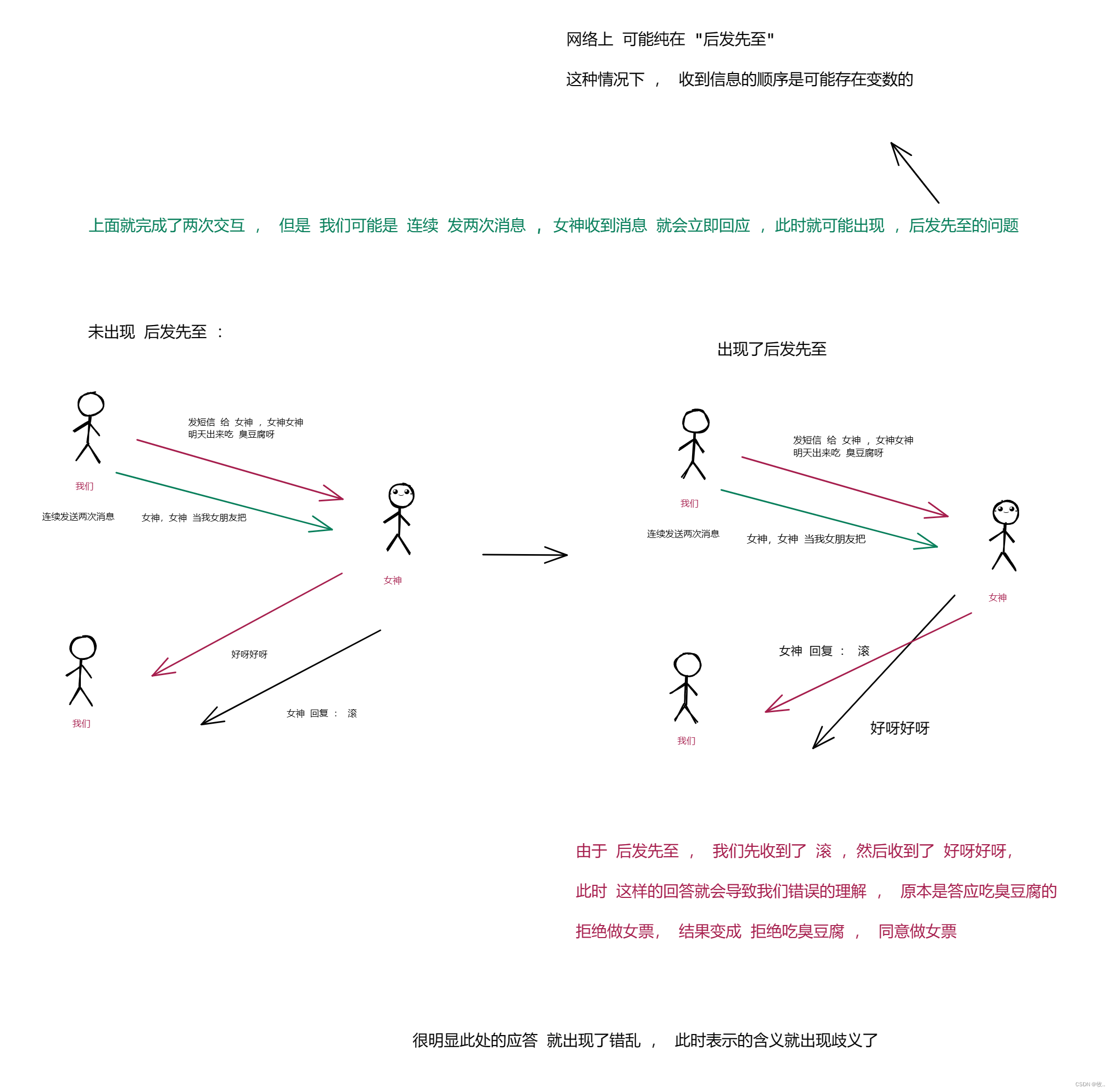
图三 :
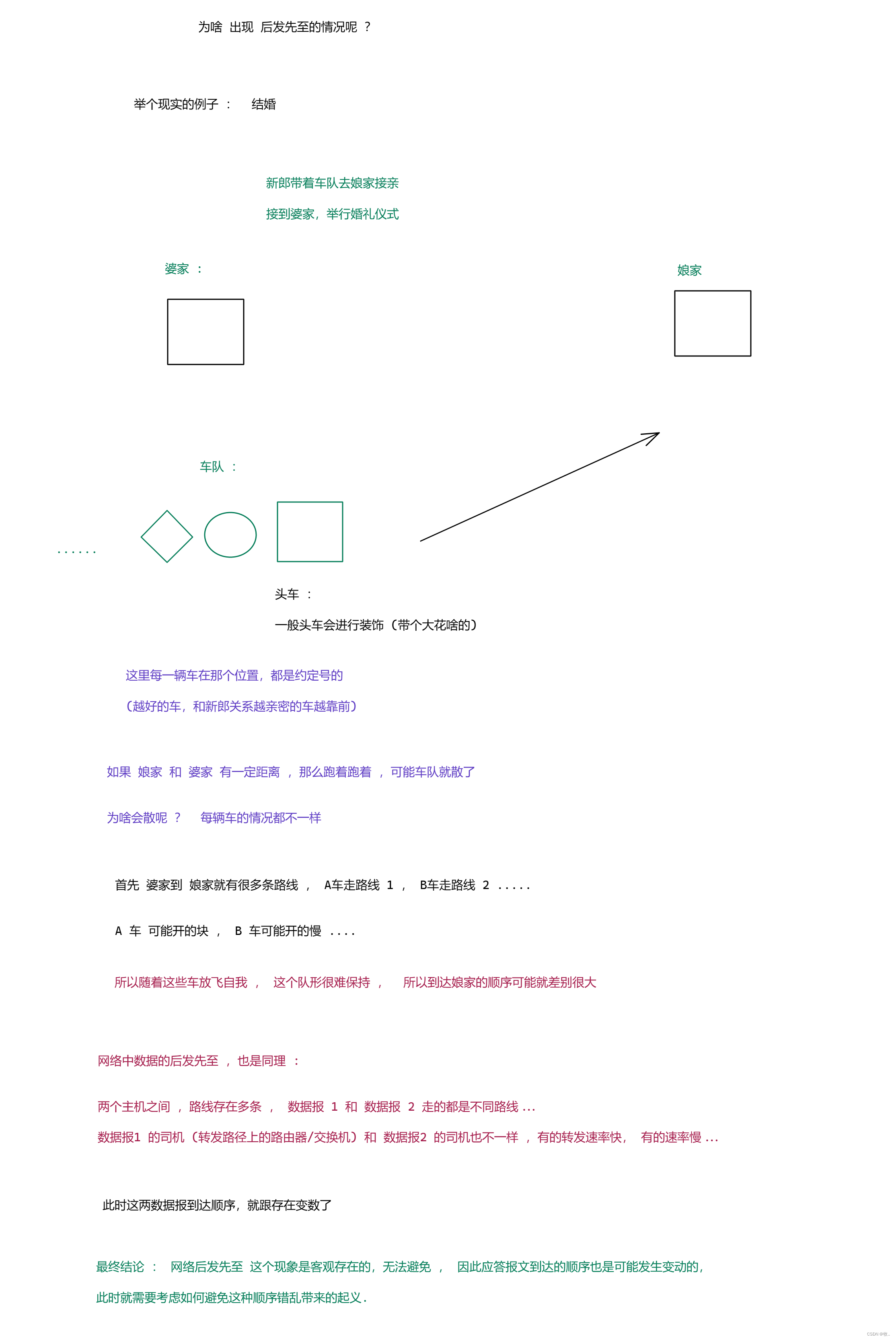
图四 :
到此 确认应答 这个机制 差不不多就看完了,但是 上面只是 考虑了 数据顺利传输的情况,规避了数据发生丢包后的场景 ,那么下面来 看看 数据发生丢包 后需要 TCP 会如何处理
2.超时重传
丢包涉及到 两种情况 :
- 发的数据丢了
- 返回的 ack 丢了
举例 :
图一 :
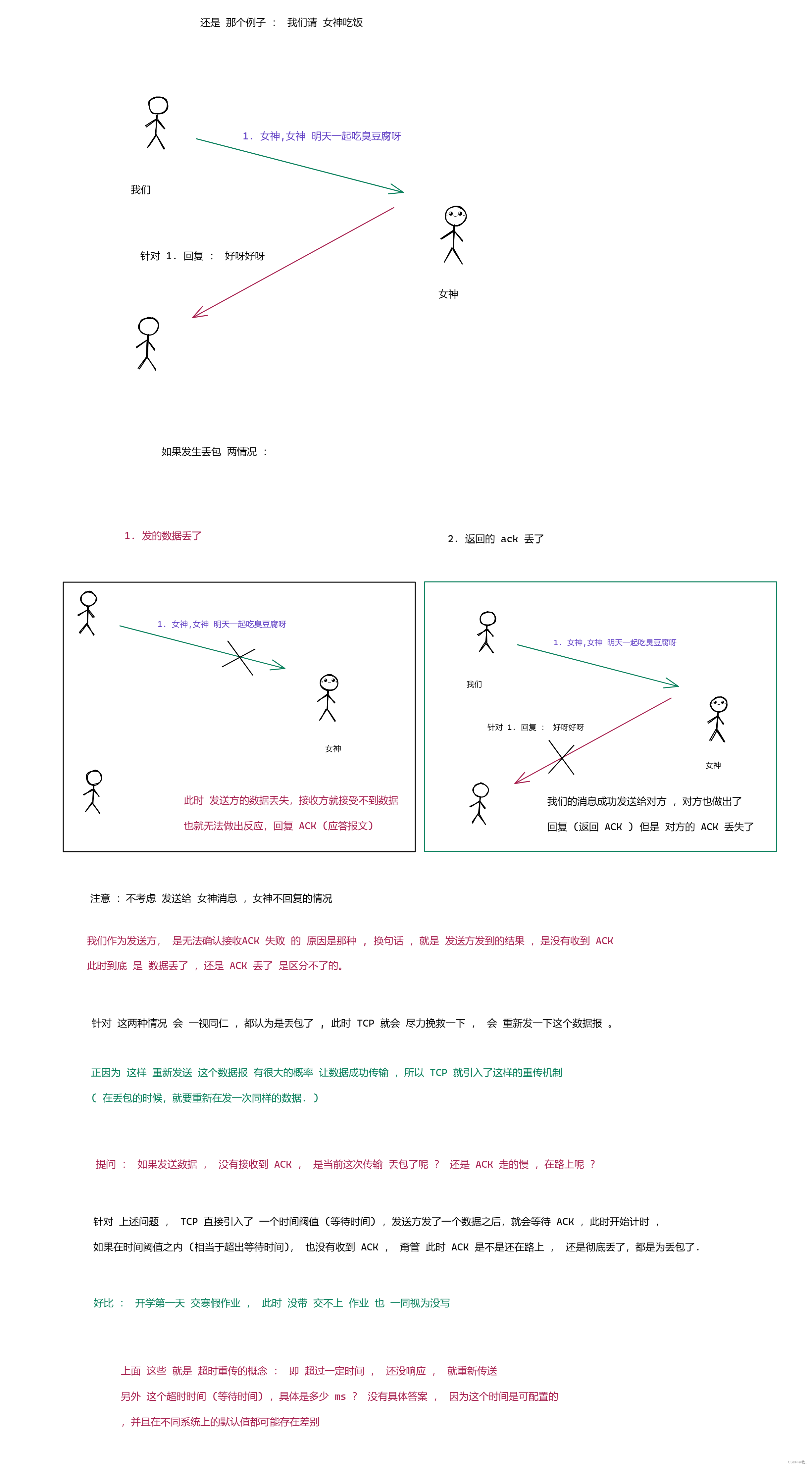
图二 :
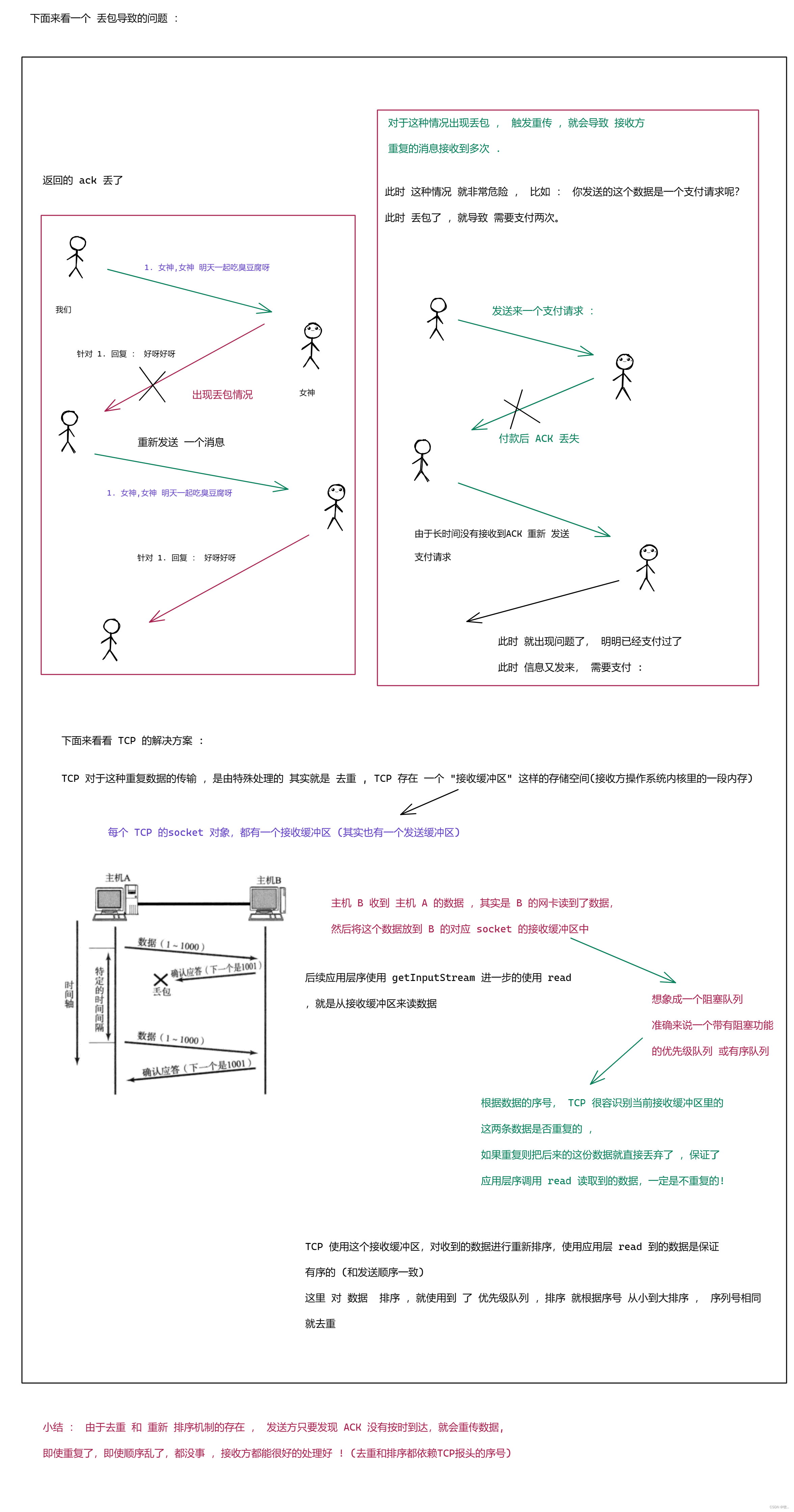
图三 :

最后小结 : 可靠传输是TCP 最核心部分 ,TCP 的可靠传输 就是 确认应答 加 超时重传 来进行体现的 , 其中 确认应答描述的是传输顺利的情况 , 超时重传描述的是传输出现问题的情况,这两者相互配合,共同支撑起整个 TCP 的可靠性
3. 连接管理
在学习连接管理之前先来了解一下啥是连接 :
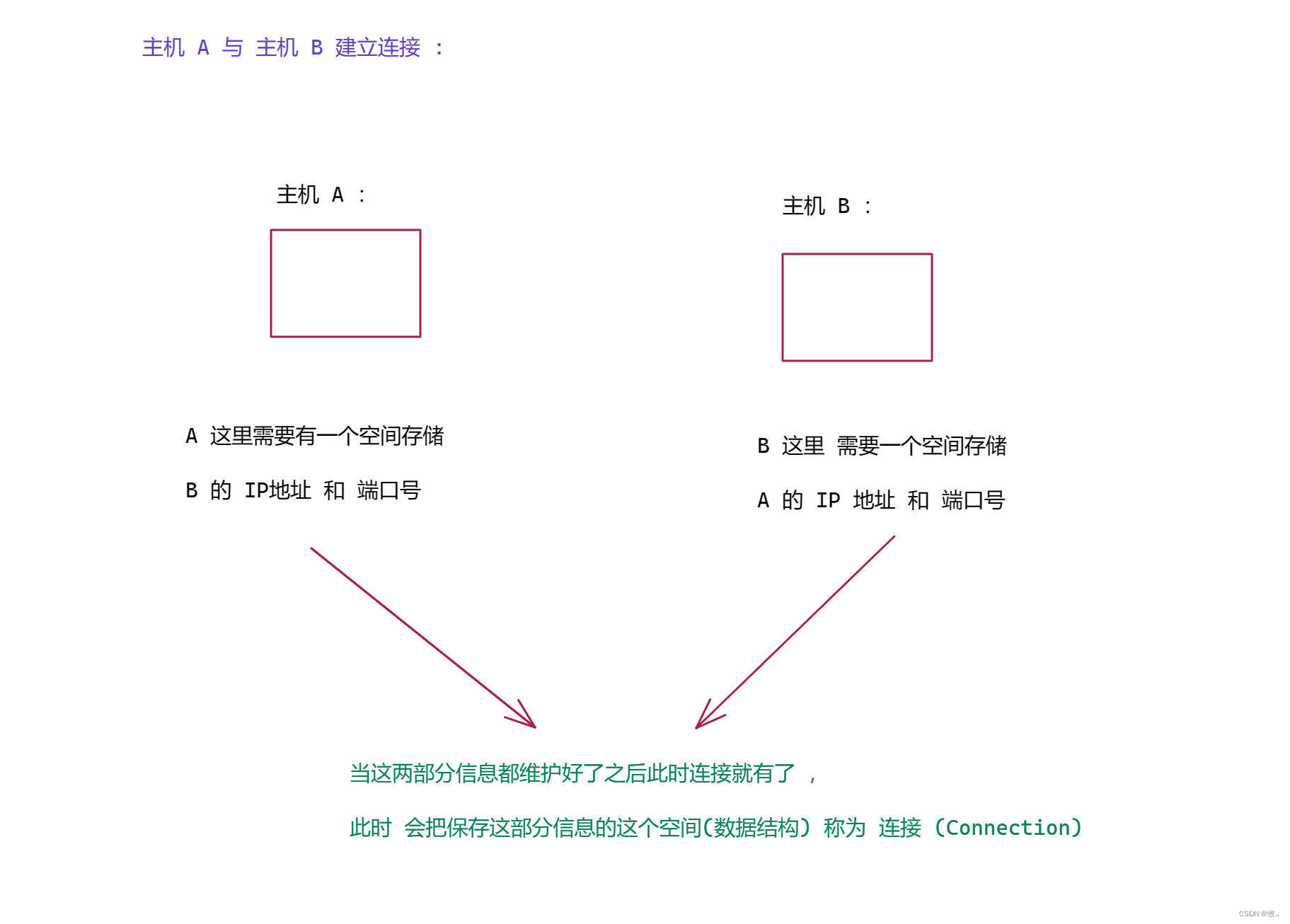
连接知道了 , 来看看管理 , 管理 : 其实就是描述了连接如何建立, 如何断开.
解释完 , 连接 和 管理 ,下面来 学习一下,整个网络原理中最最高频的面试题 .
TCP 的 建立连接过程 (三次握手)和 断开 连接过程 (四次挥手).
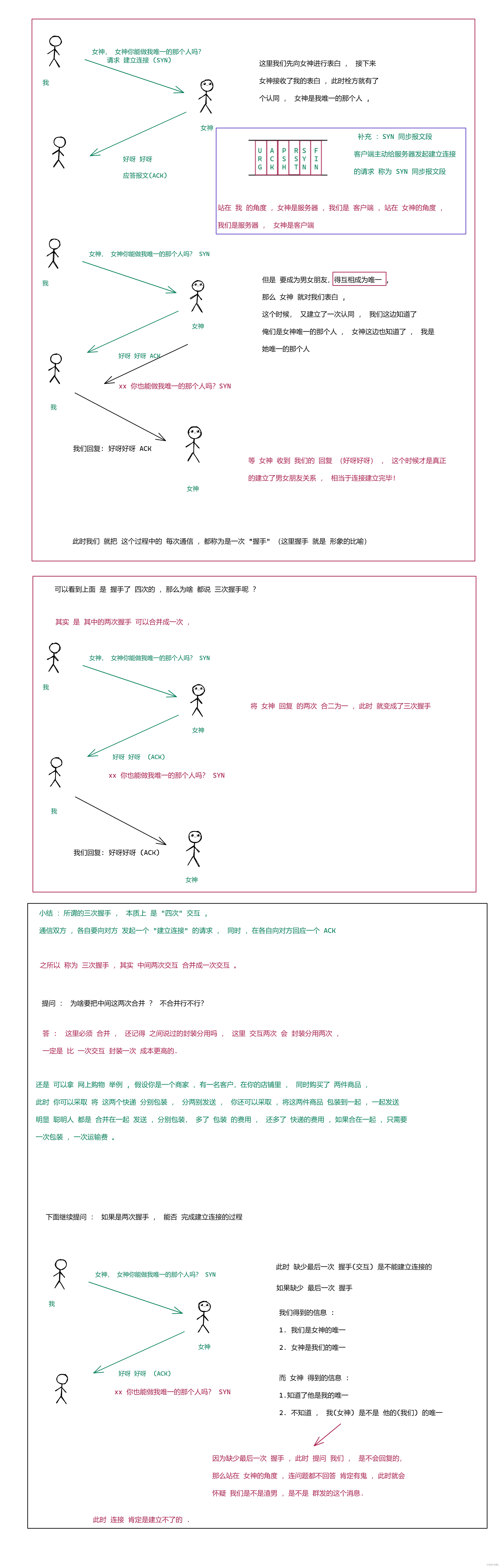
3.1 建立联系 :三次握手
通信双方各自要记录对方的信息 , 彼此之间要相互认同
举例 :
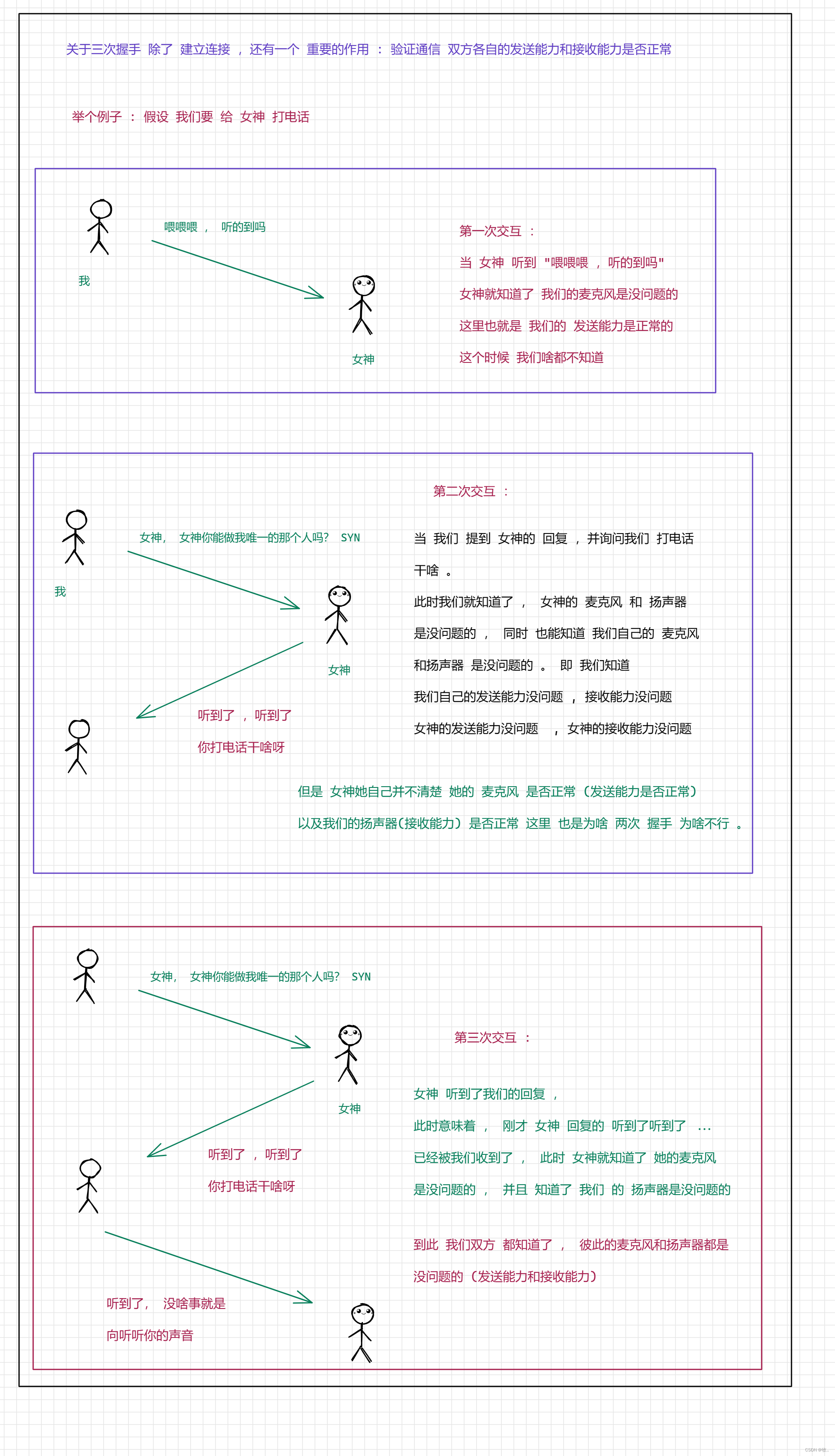
关于三次握手 除了 建立连接 还有 一个 重要的作用 : 验证通信 双方各自的发送能力和接收能力是否正常
作用看完 , 下面来谈谈 三次握手的意义 :
1.让通信双方各自建立对对方的 “认同”
2.验证通信双方各自的发送能力 和 接收能力 是否 ok
3.在握手的过程中 ,双方来协商一些重要的参数 . ( TCP 通信过程中 ,有些数据,通信双方要相互同步 ,此时就需要 有这样的交互过程 ,
此时就可通过三次握手这样的机会 ,来完成数据的同步 ).
上面都是通过 举例 来描述 三次握手是咋样的, 下面就来 看看 真正意义上 三次握手是啥样子的.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35KSMtKn-1676623573948)(C:\Users\A\AppData\Roaming\Typora\typora-user-images\image-20230213205352794.png)]
3.2 断开连接 : 四次挥手
挥手 和 握手 一样都是形象的叫法 , 都是客户端服务器之间的数据交互 .

图二 :

图三 :

小结 :
TCP 作为一个 有连接的协议, 就需要建立连接和断开连接 , 其中 建立连接 的过程 是三次握手 , 断开连接的过程 是四次挥手 .
建议 : 将 三次 握手 和 四次挥手 的图 ,熟练 记住 (简化图) .
三次握手的意义 :
- 双方建立对 , 对方的认同 (保存对方的信息)
- 验证通信双方的发送和接收能力
- 协商一些关键参数
面试题 : 握手 为啥不能是 四次 ,为啥不能是两次
答 : 如果是 握手四次 ,相当于 多封装分用了一次 ,成本更高了 , 效率还降低了 , 如果只是握手两次 ,会导致 服务器 不能知道 服务
器自己的发送能力是否正常, 也无法知道客户端的接收能力是否正常 ,此时 就无法正常建立连接了 .
四次挥手 :
为啥是四次 : 因为 FIN 是 调用用户态的 socket.close 发送 , 而 ACK 是内核态调用的 ,当 客户端 发送 FIN 给 服务器 时 (相当于 服务器
调用了socket.close) , 服务器 收到 了 立刻发送一个 ACK ,此时如果 立即 调用 了 服务器的 socket.close 那么 就可能 会将 ACK 和 FIN
并在一起 ,那么 就 是三次挥手 了 , 但是 大部分情况下 ACK 和 FIN 是合并不了的 (时机不同) 所以 ,就会 出现四次 交互 .
TIME_WAIT 意义和作用
TIME_WAIT 意义 : 防止 最后发送的 ACK 丢包 , 处在 TIME_WAIT 状态下 就会等待 2MSL 的 时间 , 此时 即便 ACK 丢包了 那么 也会
等待 FIN 重传 ,然后重新 发送 ACK
4. 滑动窗口
滑动窗口存在的意义就是在保证可靠性的前提下,尽量提高传输效率!!
这里 确认应答 , 超时重传 ,连接管理 都是 给 TCP 的可靠性提供的支持 . (确认应答 和 超时重传 主要 , 连接管理辅助)
TCP 引入了 可靠性 ,那么势必就会付出代价 ,而代价就是影响了 传输 效率 . (可靠 和 效率 是冲突 的 ) UDP 是没有可靠性 ,所以 他的
传输效率 肯定是要比 TCP 高.
TCP 作为主流的协议 ,肯定不会坐以待毙 , 会竭尽可能 提高传输效率 (本质上是补救措施) ,但是 再这么努力 提高 ,也不能比 UDP 这种
完全不考虑可靠性的效率高 , 但至少可以让自己的效率不要太拉跨. 就有了滑动窗口 这个机制 .
滑动窗口 本质 上 就是降低 确认应答 ,等待 ACK 消耗的时间
题外话 :说到等 不得不提到 IO 操作 .
当我们进行 IO 操作的时候 ,其实 时间成本主要是两个部分 :
- 等 ,
- 数据传输 (数据拷贝)
这里大多数情况下 IO 花费的 时间成本大头都是在 等 .
回到 正题 : 这里具体怎么 缩短等待 ACK 的时间 ?
其实 很简单 就是 批量发送, 批量等待 , 把多份等待时间 ,合并成一份了 .
图一 :
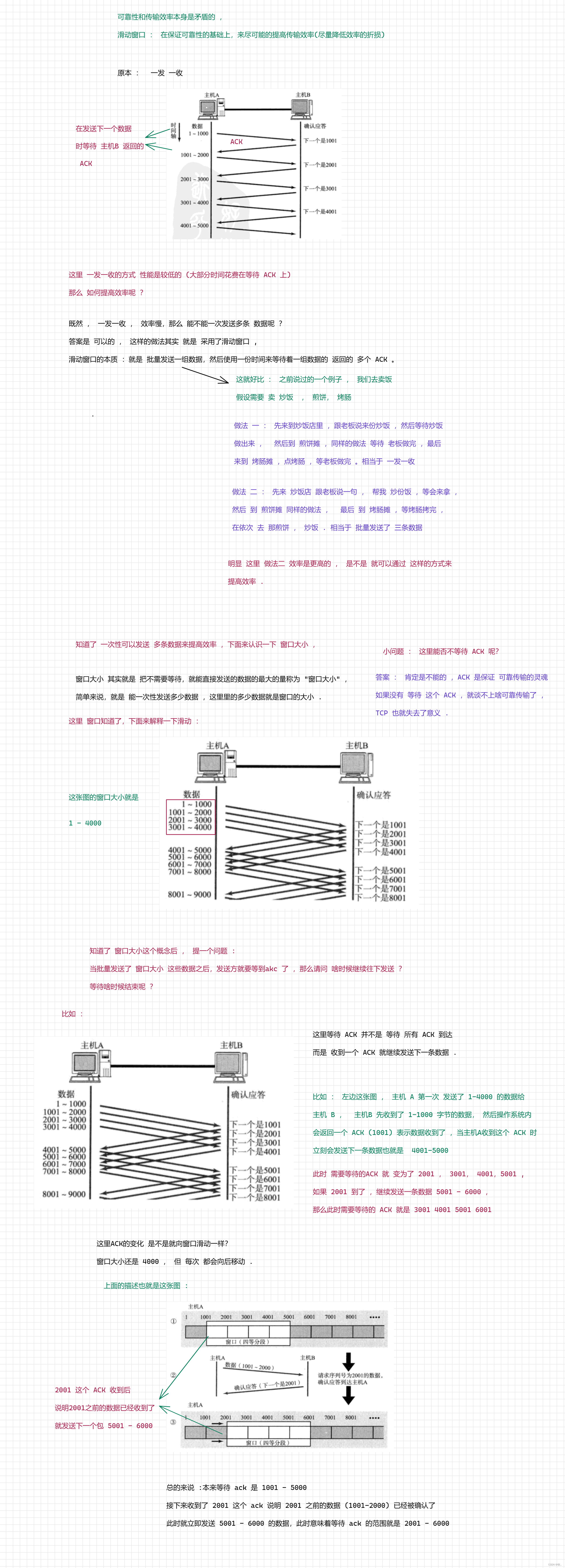
图二 :
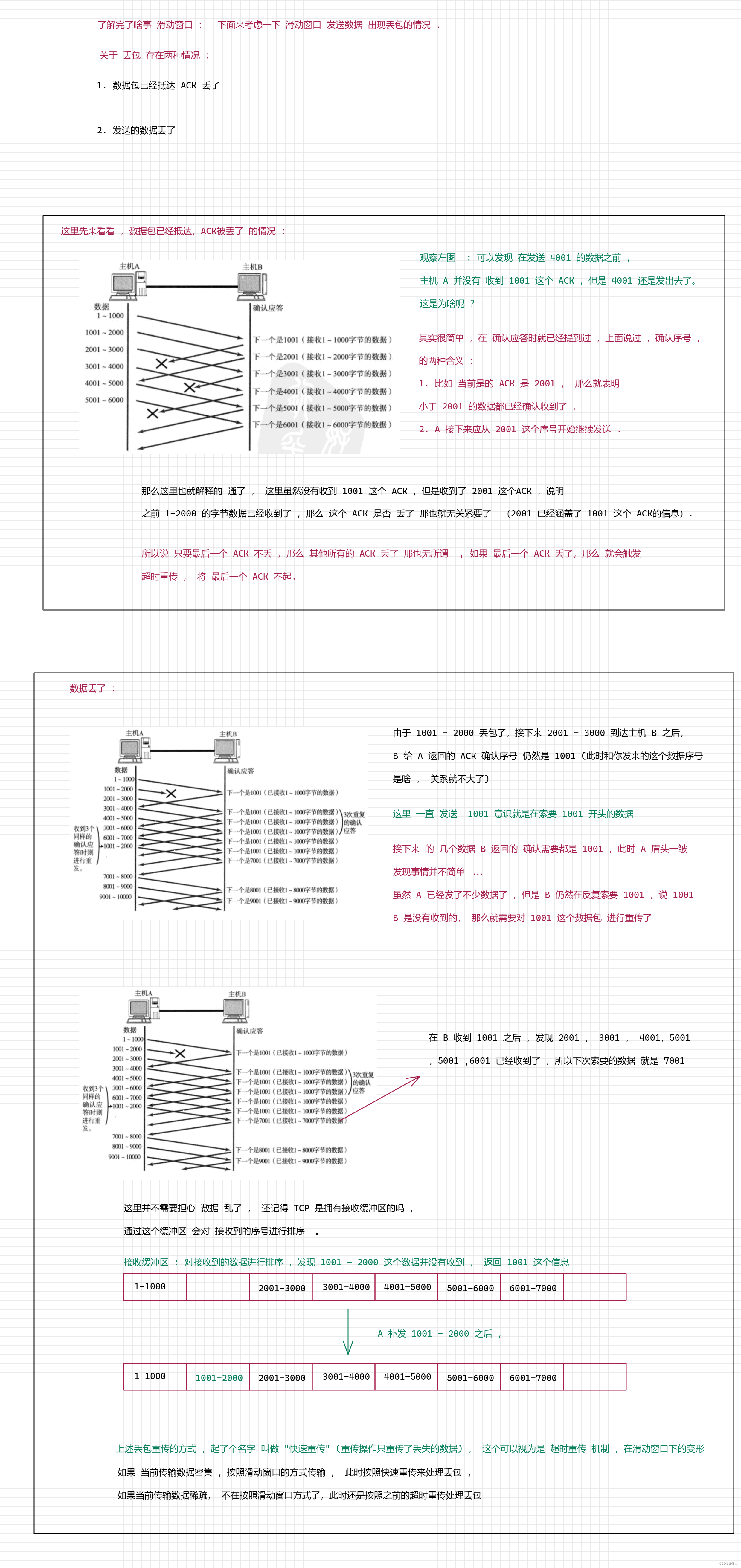
5. 流量控制
流量控制 : 这时一种干预发送窗口大小的机制 , 主要作用 保证 可靠性 .
在滑动窗口 中 , 窗口越大 (一次传输的数据量 就越多 ) ,传输效率就越高 (一份时间,等待的 ACK 就越多) ,
那么 , 能不能将窗口弄得无限大 ?
答案 是不行的 , 这里 就会导致 出现 不等 ACK 的情况 此时无法保证可靠性 , 同时 窗口太大 ,会消耗大量的系统资源 , 最后 发送速
度太快 ,接收方处理不过来 ,发了 也白发 (此时就需要重传 ,浪费时间和资源 )。
关于 发送太快 ,接收方 处理不过来 , 这种情况 就好比 老师讲课 , 讲的非常快,完全不考虑 学生听没听懂 , 一顿 输出 后 , 学生都蒙了 , 此时 讲了更没讲一样 .
这里接收方处理数据的能力 , 就是一个很重要的约束依据 (约束一次性发送多少数据,也就是规定窗口大小) ,
需要注意 : 发送方发的速度不能超出接收方的处理能力.
流量控制 要做的工作就是这个 , 根据接收方的处理能力,协调发送方的发送速率 .
如何 衡量接收方的处理能力 ?
一个量化的方法 , 计算接收方一秒钟能处理多少个字节 . (这种方式,实现起来有些麻烦, 不考虑) .
更简单的方法 : 直接看接收方接收缓冲区的剩余大小 .
6. 拥塞控制
流量控制 和 拥塞控制 共同决定发送方的窗口大小是多少 .

7. 延时应答
延时应答 , 也是提升效率的机制 , 也是在滑动窗口的基础之上 ,搞点事情 .
滑动窗口的关键 , 让窗口大小大一点 , 传输速度就快一点 。
延时应答 , 做的事 就是在 接收方能够处理的了的前提下,尽可能的把窗口大小放大一小点 .
举例 :

8. 捎带应答
捎带应答 是在延时应答的基础上 ,引入的, 同样也是 提高效率的方式 .
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RyCmqjIf-1676623573951)(C:\Users\A\AppData\Roaming\Typora\typora-user-images\image-20230217100617566.png)]
9. 面向字节流
TCP 是面向字节流的, 既然是面向字节流 , 就会引入一个麻烦的事情, 就是 粘包问题
图一 :
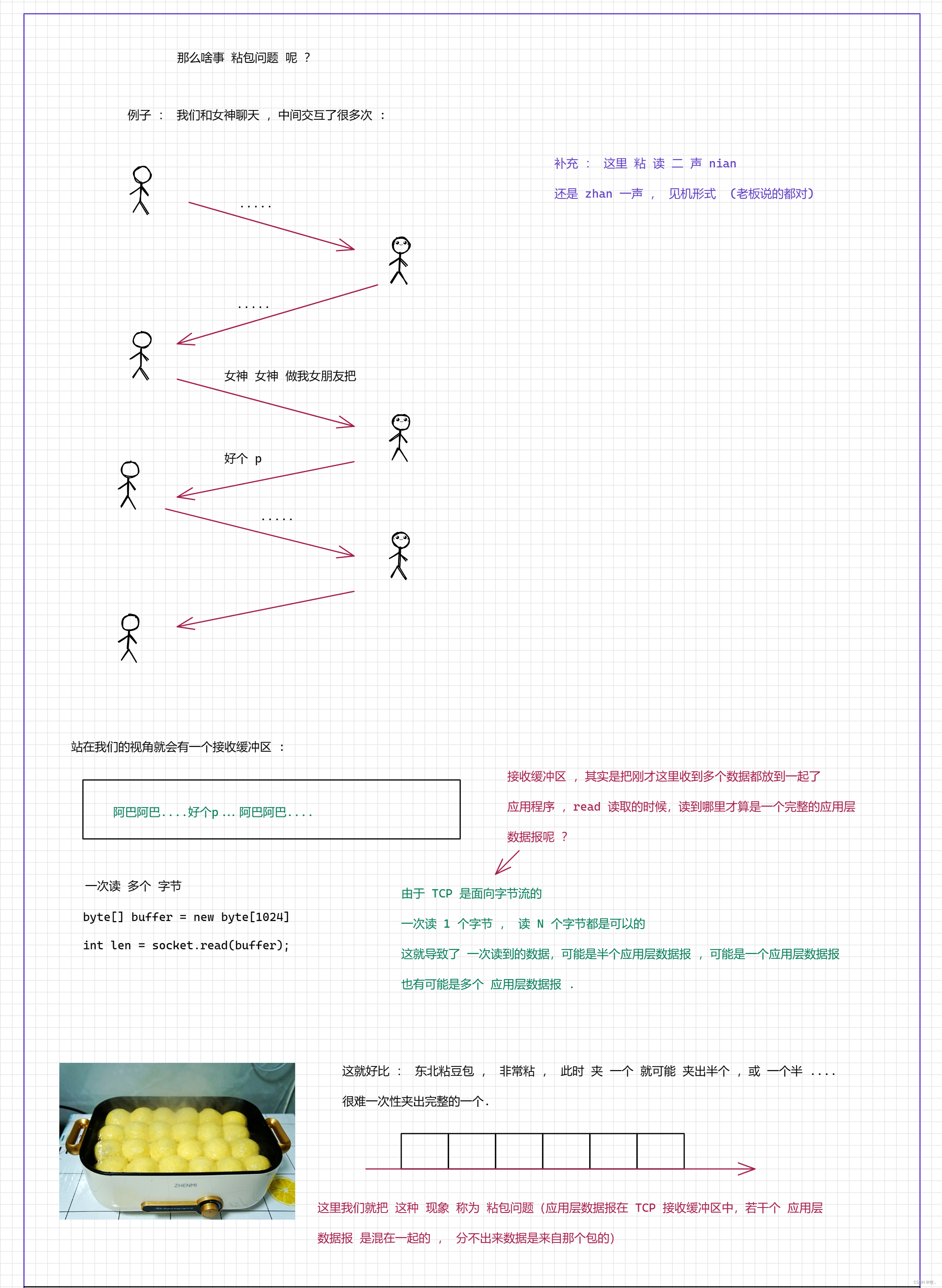
图二 :

10. 异常情况
异常情况 : 传输过程中出现了不可抗力
不可抗力 :
- 进程蹦了
- 主机关机了 (正常流程关机)
- 主机掉电了 (突然停电)
- 网线断开 (拔网线)

关于 TCP 这里 就说到这里 ,TCP 是个非常复杂的协议 , 不仅仅是这十个特性 ,这十个特性 是TCP 比较核心的特性 , 如果想要了解更多 TCP 的特性
可以查看 RFC 标准文档 : RFC 9293: Transmission Control Protocol (TCP) (rfc-editor.org)
下面来对 UDP 和 TCP 进行一下对比 :
TCP 优势在于 ,可靠传输 , 觉得大部分场景中 ,都需要可靠传输 .
UDP 优势在于 , 更高的效率, 如果有些场景对于性能要求更苛刻 .
说一下 :对于 UDP 来说 什么 场景下 对于 性能要求更苛刻 , 并且又不是 特别害怕丢包呢 ?
比较典型的场景 : 同一个机房内部的,服务器之间通信 . 此时网络 结构相当简单,网络带宽比较充裕 ,转发设备也是比较好的设备 , 整体 丢包的可能性就比小 .
UDP 还有一个小优势 ,天然支持广播

下面继续 : 关于传输层差不多就说完了, 但是需要注意 , 本文主要说的是 TCP 和 UDP , 别自以为 传输层 只有这两个 协议 .
举个例子 : 王者荣耀
请问 : 1. 是否需要可靠性 , 2. 是否需要高效率
答 : 可靠性肯定是需要的, 如果没有那么 一直丢包,那么游戏的画面不就成幻灯片了吗 , 高效率肯定也是需要的, 如果延迟比较大, 本来能操作的 因为 延迟而操作不起来 。
既然 可靠性高效率都需要,那么请问这里使用的是 TCP 还是 UDP 呢 ?
答 : 都不用 , 除了 TCP , UDP 之外 ,还有一些其他的传输层协议 ,有的传输层协议 ,属于能够专门为游戏场景来量身打造的 ,
TCP 和 UDP 太极端了 , 一个 把可靠性拉满 , 一个把高效性拉满 , 其他的协议 就可以往中间靠 , 不需要那么可靠 ,不需要那么高效 。
这里典型的协议 以 KCP 为代表的一系列协议 .
到此传输层完 ,下文 来说说 网络层