目录
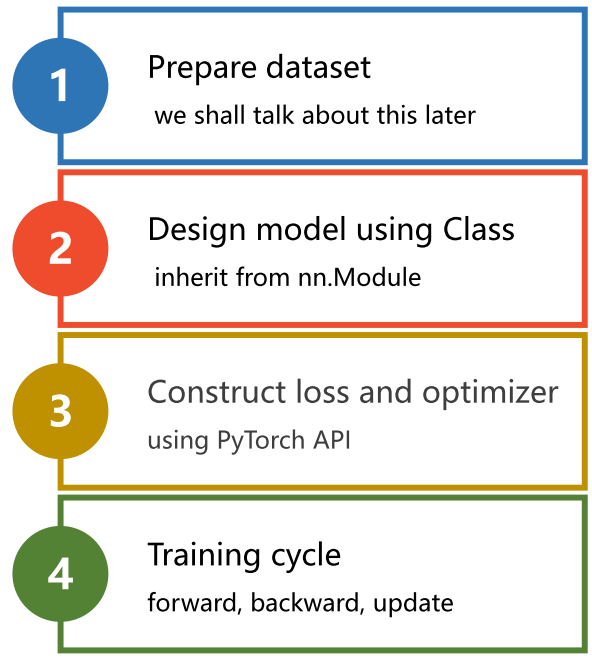
1 Pytorch实现线性回归
1.1 实现思路
1.2 完整代码
2 各部分代码逐行详解
2.1 准备数据集
2.2 设计模型
2.2.1 代码
2.2.2 代码逐行详解
2.2.3 疑难点解答
2.3 构建损失函数和优化器
2.4 训练周期
2.5 测试结果
3 线性回归中常用优化器
1 Pytorch实现线性回归
1.1 实现思路
1.2 完整代码
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(500):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)2 各部分代码逐行详解
2.1 准备数据集
在PyTorch中,一般需要采取mini-batch形式构建数据集,也就是把数据集定义成张量(Tensor)形式,以方便后续计算。
在下面这段代码中,x_data是个二维张量,它有3个样本,每个样本有1个特征值,即维度是 (3, 1);y_data同理。不清楚的同学可以使用 x.dim() 方法和 x.shape 属性来获取张量的维度和尺寸,自行调试。简言之,在minibatch中,行表示样本,列表示feature
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])2.2 设计模型

主要目标:构建计算图
2.2.1 代码
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()2.2.2 代码逐行详解
class LinearModel(torch.nn.Module):一般我们需要一个类,并继承自PyTorch的Module类,这是因为torch.nn.Module提供了很多有用的功能,使得我们可以更方便地定义、训练和使用神经网络模型。
接下来至少需要实现两个函数,即init和forward。
__init__方法
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)该方法对模型的参数进行初始化。
在super(LinearModel, self).__init__() 中,第一个参数 LinearModel 指定了查找的起点,即在 LinearModel 类的父类中查找;第二个参数 self 指定了当前对象,即调用该方法的对象。该语句的作用是调用 LinearModel 的父类 torch.nn.Module 的 __init__ 方法,并对父类的属性进行初始化。这是初始化模型的一个必要语句。
接下来将一个torch.nn.Linear对象实例化并赋值给self.linear属性。torch.nn.Linear 的构造函数接收三个参数:in_features 、 out_features、bias,分别代表输入特征的数量、输出特征的数量和偏置量。

forward方法
def forward(self, x):
y_pred = self.linear(x)
return y_predforward()方法作用是进行前馈运算,相当于计算。
注意这里相当于是重写了torch.nn.Linear 类中的forward方法。在我们重写forward后,函数将会执行的过程如下:

y_pred = self.linear(x) 的作用是将输入 x 传入全连接层进行线性变换,得到输出 y_pred。
最后通过实例化LinearModel类来调用模型
model = LinearModel()2.2.3 疑难点解答
1、可能你会有疑问,代码中的backward过程体现在哪呢?
答:torch.nn.Module类构造出的对象会自动完成backward过程。Module 类及其子类在前向传递时会自动构建计算图,并在反向传播(backward)时自动进行梯度计算和参数更新。比如self.linear=torch.nn.Linear(1, 1),
这里的linear属性得到Linear类的实例后,相当于继承自Module,所以它也会自动进行backward,就无须我们再手动求导了。
2、y_pred = self.linear(x) 中,linear为什么后面可以直接跟括号呢?
这里涉及到了python语法中的可调用对象(Callable Object)知识点。在self.linear后面加括号,相当于直接在对象上加括号,相当于实现了一个可调用对象。
self.linear = torch.nn.Linear(1, 1)中,相当于我们创建了一个Module对象,因为nn.Linear类继承自nn.Module类。
接着我们执行了y_pred = self.linear(x)这段代码,相当于我们调用了Moudle 类的 __call__ 方法。
于是nn.Module类的__call__方法又会进一步去自动调用模块的forward方法。
举个例子:
class Adder:
def __init__(self, n):
self.n = n
def __call__(self, x):
return self.n + x
add5 = Adder(5)
print(add5(3)) # 输出 8
在这个例子中,我们定义了一个 Adder 类,它接受一个参数 n,并且实现了 __call__ 方法。当我们创建 add5 对象时,实际上是创建了一个 Adder 对象,并且把参数 n 设置为 5。当我们调用 add5 对象时,实际上是调用了 Adder 对象的 __call__ 方法,
通过实现 __call__ 方法,我们可以让对象像函数一样被调用,这在一些场景下很有用,例如,我们可以用它来实现一个状态机、一个闭包或者一个装饰器等。
3、权重体现在哪?forward里面好像没涉及到权重值的传入?
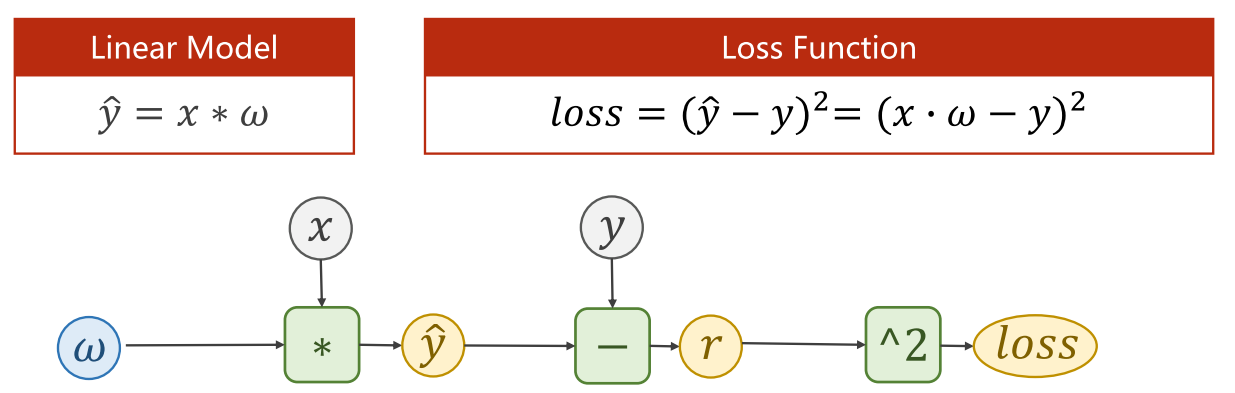
这里 self.linear 实际上是一个 PyTorch 模块(Module),包含了权重矩阵和偏置向量,于是我们便可以用这个对象来完成下图所示计算


那么权重是怎么传入forward中的呢?
在torch.nn.Linear类的构造函数__init__中,它会自动创建一个nn.Parameter对象,用于存储权重,并将其注册为模型的可学习参数(Learnable Parameter)。
这个nn.Parameter对象的创建代码位于nn.Linear类的__init__函数中的这一行:
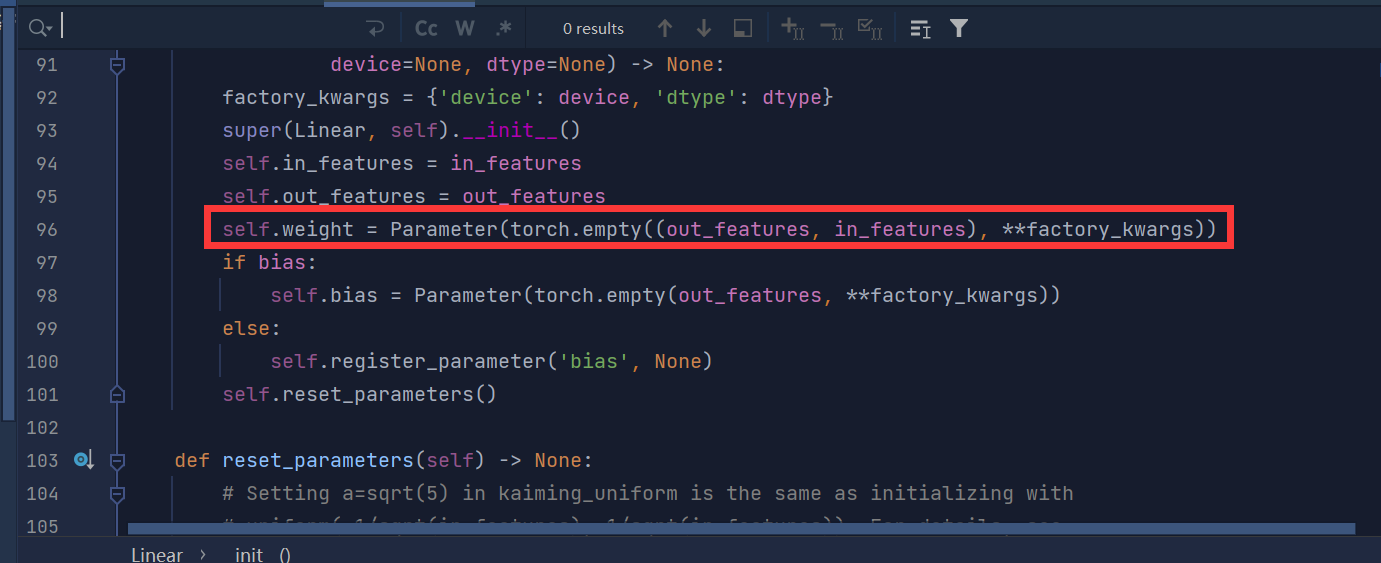
因此,self.linear中的weight属性实际上是从nn.Parameter对象中获取的。在forward方法中,self.linear会自动获取到它的weight属性,并用它来完成矩阵乘法的操作。
2.3 构建损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
torch.nn.MSELoss 是一个均方误差损失函数,用于计算模型输出与真实值之间的差异,即MSE。其中,size_average 参数指定是否对损失求均值,默认为 True,即求平均值。在这个例子中,size_average=False 意味着我们希望得到所有样本的平方误差之和。

torch.optim.SGD 是随机梯度下降优化器,用于更新神经网络中的参数。其中,model.parameters() 对神经网络中的参数进行优化,它会检查所有成员,告诉优化器需要更新哪些参数。在反向传播时,优化器会通过这些参数计算梯度并对其进行更新。lr 参数表示学习率,即每次参数更新的步长。在这个例子中,我们使用随机梯度下降作为优化器,学习率为 0.01。最后我们得到了一个优化器对象optimizer。
2.4 训练周期
for epoch in range(500): # 训练500轮
y_pred = model(x_data) # 前向计算
loss = criterion(y_pred, y_data) # 计算损失
print(epoch, loss.item()) # 打印损失值
optimizer.zero_grad() # 梯度清零,不清零梯度的结果就变成这次的梯度+原来的梯度
loss.backward() # 反向传播
optimizer.step() # 更新权重2.5 测试结果
循环迭代进行训练500轮。
# Output weight and bias
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)输出结果部分截图:
0 23.694297790527344
1 10.621758460998535
2 4.801174163818359
3 2.208972215652466
4 1.0539695024490356
5 0.5387794971466064
6 0.3084312379360199
7 0.20490160584449768
8 0.1578415036201477
9 0.13593381643295288
10 0.12523764371871948
11 0.1195460706949234
12 0.11609543859958649···
494 0.00010695526725612581
495 0.00010541956726228818
496 0.00010390445095254108
497 0.00010240855044685304
498 0.00010094392928294837
499 9.949218656402081e-05
w = 1.993359923362732
b = 0.015094676986336708
y_pred = tensor([[7.9885]])Process finished with exit code 0
总之,求yhat,求loss,然后backward,最后更新权重
3 线性回归中常用优化器
• torch.optim.Adagrad
• torch.optim.Adam
• torch.optim.Adamax
• torch.optim.ASGD
• torch.optim.LBFGS
• torch.optim.RMSprop
• torch.optim.Rprop
• torch.optim.SGD
阅读官方教程的更多示例:
Learning PyTorch with Examples — PyTorch Tutorials 1.13.1+cu117 documentation