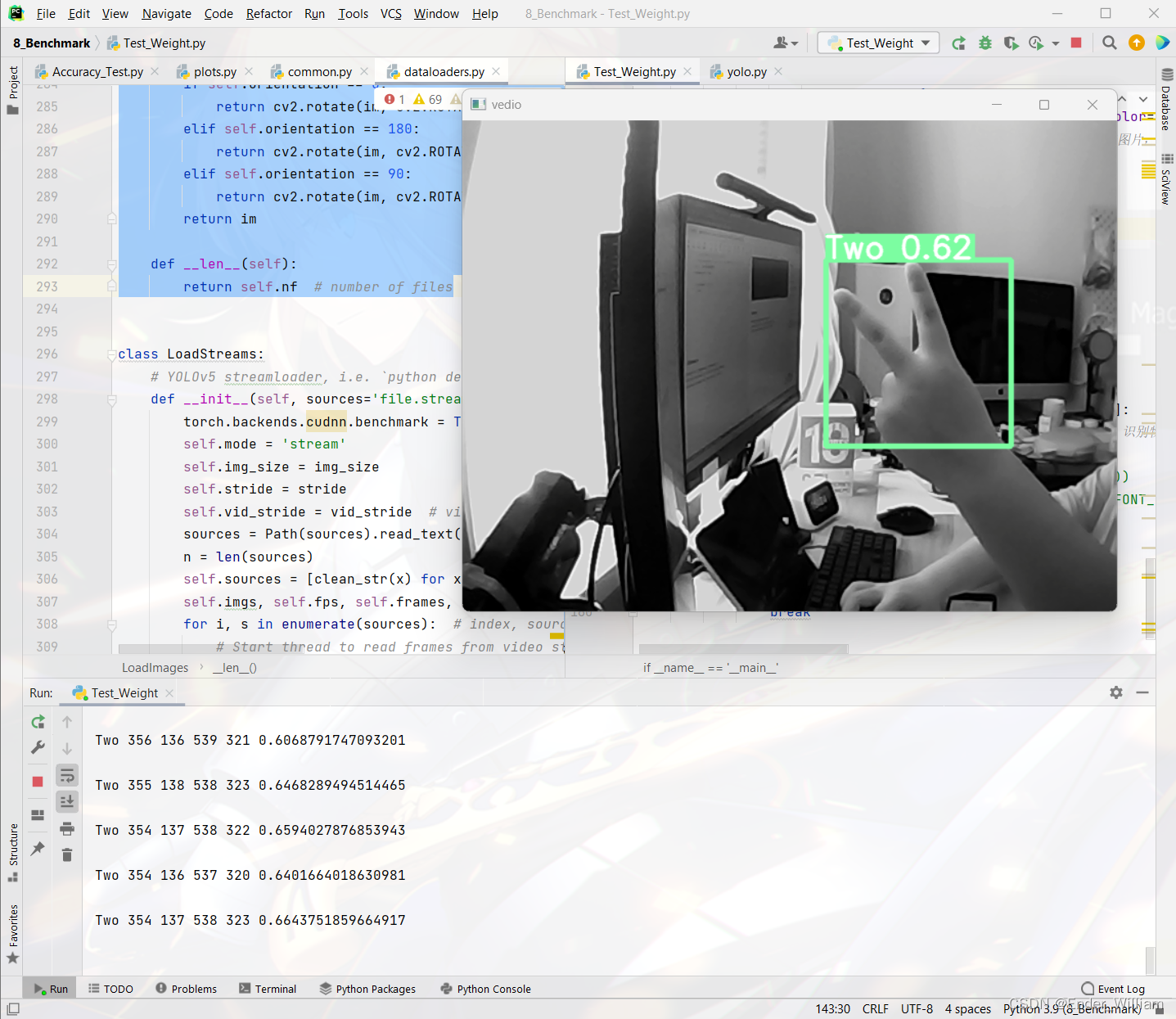
备注:测试数据库版本为MySQL 8.0
硬件优化概述
MySQL的硬件有:
- CPU
- 内存
- 硬盘
- 网络资源
对于硬件的选择与调优,在系统上线前就需要考虑起来。
当然我们都知道:
- 好的CPU,可以让SQL语句解析得更快,进而加快SQL语句的执行速度。
- 大的内存,可以缓存更多的MySQL数据在内存中,进而加快MySQL的数据读取速度。
- 快的存储,可以让MySQL更快的读取和写入数据,进而加快SQL语句的响应速度。
- 高的网络带宽,能让MySQL提供更大的吞吐量,进而加快客户端与MySQL服务器之间的数据传输速度。
如果可以,我们更应该选择更好的配置,可惜的是,大多数情况下,由于预算,我们只能进行一些取舍,选择最合适当前应用的配置。
网络一般不会作为很严重的瓶颈出现,而CPU、内存和磁盘通常是主要的瓶颈所在。对MySQL而言,通常希望有很多快速CPU可以用,但如果必须在快和多之间做选择,则一般会选择更快而不是更多(其他条件相同的情况下)。
CPU、内存以及磁盘之间的关系错综复杂,一个地方的问题可能会在其他地方显现出来。在对一个资源抛出问题时,问问自己是不是可能是由另外的问题导致的。如果遇到硬盘密集的操作,需要更多的I/O容量吗?或者是更多的内存?答案取决于工作集大小,也就是给定的时间内最常用的数据集。
CPU
计算机包含一个金字塔型的缓存体系,更小、更快、更昂贵的缓存在顶端,如下图:
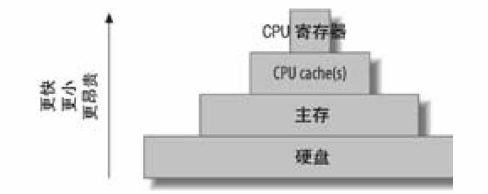
理论上CPU 频率越高,核数越多,性能也会越好,但是实际生产中,很多时候系统的瓶颈不在CPU而在IO,此时即便增加了CPU的频率和核数,带来系统性能的提升也是极其有限的。
我们可以把应用分为两类:
- CPU密集型
- I/O密集型
CPU密集型
CPU密集型服务器的vmstat输出通常在us列会有一个很高的值,报告了花费在非内核代码上的CPU时钟;也可能在sy列有很高的值,表示系统CPU利用率,超过20%就足以令人不安了。在大部分情况下,也会有进程队列排队时间(在r列报告的)。下面是一个例子:
[root@mydb ~]# vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 2047688 449636 4256 26755228 0 0 4343 232 0 0 8 1 87 4 0
0 0 2047688 444296 4280 26756244 0 0 7414 63 3660 6323 0 0 99 0 0
0 0 2047688 443304 4432 26756716 0 0 7076 97 3670 6359 0 0 99 0 0
0 0 2047688 453504 4572 26756884 0 0 7256 64 3907 6404 1 0 99 0 0
0 0 2047688 453752 4588 26757316 0 0 7282 66 4583 6631 1 0 99 0 0
0 0 2047688 453736 4604 26757952 0 0 7295 57 3831 6415 0 0 99 0 0
1 0 2047688 452512 4624 26758036 0 0 6446 59 3592 6204 1 0 99 0 0
对于此类应用:
选择频率较高、核数较多的CPU
MySQL 早期版本对多核CPU 的支持较弱,到5.6 版本以后, MySQL 能使用48 核以上的CPU 。但是由于MySQL 不支持SQL 语句并行执行,所以CPU 的频率较高、核数较多会更有优势。在硬件选型时,请尽量选择频率较高、核数较多的CPU 。
关闭节能模式
节能模式开启会带来一定的CPU性能开销,建议关闭。
I/O密集型
在I/O密集型工作负载下,CPU花费大量时间在等待I/O请求完成。这意味着vmstat会显示很多处理器在非中断休眠(b列)状态,并且在wa这一列的值很高.
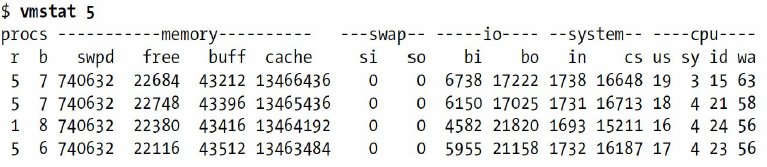
这台机器的iostat输出显示硬盘一直很忙:
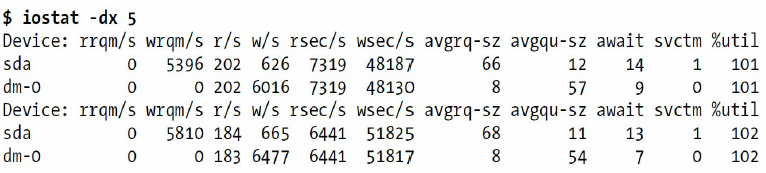
%util的值可能因为四舍五入的错误超过100%。什么迹象意味着机器是I/O密集的呢?只要有足够的缓冲来服务写请求,即使机器正在做大量的写操作,也可能可以满足,但是却通常意味着硬盘可能会无法满足读请求。这听起来好象违反直觉,但是如果思考读和写的本质,就不会这么认为了:
- 写请求能够缓冲或同步操作。如下任意一层缓冲:操作系统层、RAID控制器层,等等。
- 读请求就其本质而言都是同步的。当然程序可以猜测到可能需要某些数据,并异步地提前读取(预读)。无论如何,通常程序在继续工作前必须得到它们需要的数据。这就强制读请求为同步操作:程序必须被阻塞直到请求完成。
想想这种方式:你可以发出一个写请求到缓冲区的某个地方,然后过一会完成。甚至可以每秒发出很多这样的请求。如果缓冲区正确工作,并且有足够的空间,每个请求都可以很快完成,并且实际上写到物理硬盘是被重新排序后更有效地批量操作的。然而,没有办法对读操作这么做——不管多小或多少的请求,都不可能让硬盘响应说“这是你的数据,我等一会读它”。这就是为什么读需要I/O等待是可以理解的原因。
对于此类应用:
增加CPU频率和核数对系统性能提升基本无太大的作用,此时可以从内存和IO方面着手,适当增加内存或I/O.
内存
配置大量内存最大的原因其实不是因为可以在内存中保存大量数据:最终目的是避免磁盘I/O,因为磁盘I/O比在内存中访问数据要慢得多。
那么配置了内存之后,该如何分配MySQL使用的内存呢?
如果配置MySQL服务器使用太少的内存会导致性能不是最优的;如果配置了太多的内存则会导致崩溃,无法执行查询或者导致交换操作严重变慢。
话虽如此,但我并不觉得找到什么可以计算内存使用的秘诀公式就能很好地解决这个问题。原因有 – 如今这个公式已经很复杂了,更重要的是,通过它计算得到的值只是“理论可能”并不是真正消耗的值。事实上,有8GB内存的常规服务器经常能运行到最大的理论值 – 100GB甚至更高。此外,你轻易不会使用到“超额因素” – 它实际上依赖于应用以及配置。一些应用可能需要理论内存的 10% 而有些仅需 1%。
那么,我们可以做什么呢?首先,来看看那些在启动时就需要分配并且总是存在的全局缓冲 – key_buffer_size, innodb_buffer_pool_size, innodb_additional_memory_pool_size, innodb_log_buffer_size, query_cache_size。如果你大量地使用MyISAM表,那么你也可以增加操作系统的缓存空间使得MySQL也能用得着。把这些也都加到操作系统和应用程序所需的内存值之中,可能需要增加32MB甚至更多的内存给MySQL服务器代码以及各种不同的小静态缓冲。这些就是你需要考虑的在MySQL服务器启动时所需的内存。其他剩下的内存用于连接。例如有8GB内存的服务器,可能监听所有的服务就用了6GB的内存,剩下的2GB内存则留下来给线程使用。
每个连接到MySQL服务器的线程都需要有自己的缓冲。大概需要立刻分配256K,甚至在线程空闲时 – 它们使用默认的线程堆栈,网络缓存等。事务开始之后,则需要增加更多的空间。运行较小的查询可能仅给指定的线程增加少量的内存消耗,然而如果对数据表做复杂的操作例如扫描、排序或者需要临时表,则需分配大约 read_buffer_size, sort_buffer_size, read_rnd_buffer_size, tmp_table_size 大小的内存空间。不过它们只是在需要的时候才分配,并且在那些操作做完之后就释放了。有的是立刻分配成单独的组块,例如 tmp_table_size 可能高达MySQL所能分配给这个操作的最大内存空间了。注意,这里需要考虑的不只有一点 – 可能会分配多个同一种类型的缓存,例如用来处理子查询。一些特殊的查询的内存使用量可能更大 – 如果在MyISAM表上做成批的插入时需要分配 bulk_insert_buffer_size 大小的内存。执行 ALTER TABLE, OPTIMIZE TABLE, REPAIR TABLE 命令时需要分配 myisam_sort_buffer_size 大小的内存。
只有简单查询OLTP应用的内存消耗经常是使用默认缓冲的每个线程小于1MB,除非需要使用复杂的查询否则无需增加每个线程的缓冲大小。使用1MB的缓冲来对10行记录进行排序和用16MB的缓冲基本是一样快的(实际上16MB可能会更慢,不过这是其他方面的事了)。
另外,就是找出MySQL服务器内存消耗的峰值。这很容易就能计算出操作系统所需的内存、文件缓存以及其他应用。现在运行 “ps aux” 命令来查看 VSZ 的值 – MySQL 进程分配的虚拟内存。也可以查看 “Resident Memory” 的值,不过我想它可能没多大用处,因为它会由于交换而变小 – 这并不是你想看到的。监视着内存变化的值,就能知道是需要增加/减少当前的内存值了。
可能有的人想说,我们想要让服务器能保证100%不会耗尽内存,不管决定用什么样的查询、什么样的用户。很不幸,这其实很不明智也不可能,因为:
以下是很少考虑的MySQL服务器内存需求
- 每个线程可能会不止一次需要分配缓冲。 考虑到例如子查询 – 每层都需要有自己的 read_buffer,sort_buffer, tmp_table_size 等。
- 在每个连接中很多变量都可能需要重新设置。 如果开发者想设定自己的变量值来运行某些查询就不能继续使用全局值。
- 可能有多个索引缓存。 为了配合执行查询可能会创建多个索引缓存。
- 解析查询和优化都需要内存。 这些内存通常比较小,可以忽略,不过如果是某些查询在这个步骤中则需要大量内存,尤其是那些设计的比较特别的查询。
- 存储过程。 复杂的存储过程可能会需要大量内存。
- 准备查询语句以及游标。 单次链接可能会有很多的准备好的语句以及游标。它们的数量最后可以限定,但是仍然会消耗大量的内存。
- Innodb表缓存。 Innnodb表有自己的缓存,它保存了从一开始访问每个表的元数据。它们从未被清除过,如果有很多Innodb表的话,那么这个量就很大了。这也就意味着拥有 CREATE TABLE 权限的用户就可能把MySQL服务器的内存耗尽。
- MyISAM缓冲。 MyISAM表可能会分配一个足以装下指定表最大记录的缓冲,而且这个缓冲直到表关闭了才释放。
- Blobs可能需要3倍的内存。 这在处理很大(max_allowed_packet 的值较大)的Blobs数据时很重要,如果处理256MB的数据可能需要768MB的内存。
- 存储引擎。 通常情况下,存储引擎会设置自己的每个线程的全局分配内存,它通常不能像缓存一样可以调节。现在应该通过各种方式来特别关注MySQL释放出来的存储引擎。
我想这还不是完成的列表,相反地,我觉得还是漏掉了一些。但主要的原因是 – 找到每次内存消耗峰值是不切实际的,因此我的这些建议可以用来衡量一下你实际修改一些变量值产生的反应。例如,把 sort_buffer_size 从1MB增加到4MB并且在 max_connections 为 1000 的情况下,内存消耗增长峰值并不是你所计算的3000MB而是30MB。
硬盘
存储简介
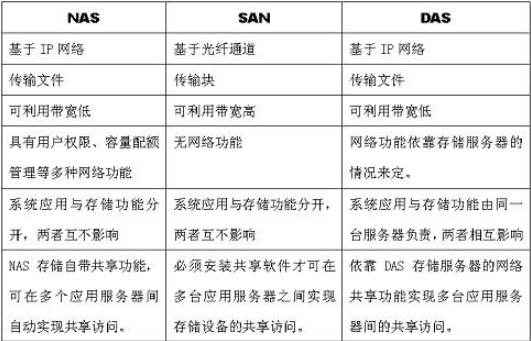
三种存储方式:DAS、SAN、NAS
三种存储类型:块存储、文件存储、对象存储
块存储和文件存储是我们比较熟悉的两种主流的存储类型,而对象存储(Object-based Storage)是一种新的网络存储架构,基于对象存储技术的设备就是对象存储设备(Object-based Storage Device)简称OSD。
本质是一样的,底层都是块存储,只是在对外接口上表现不一致,分别应用于不同的业务场景。
SAN设备可以承受大量的顺序读写操作,因为这些读I/O可以缓冲,并且进行I/O合并,但是在随机读写上的就要慢一些,甚至不如直接通过RAID访问本地磁盘那种读写效率

存储要选择SAN
仔细地做好逻辑和物理设计,包括索引和适当的服务器硬件(尽量配置更多的内存!)可避免很多的随机I/O操作,或者可以转化为顺序的I/O。然而,应该知道的是,通过一段时间的运行,这种系统可以达到一个微妙的平衡——引入一个新的查询,Schema的变化或频繁的操作,都很容易扰乱这种平衡。
RAID
存储引擎通常把数据和索引都保存在一个大文件中,这意味着用RAID(Redundant Array of Inexpensive Disks,磁盘冗余阵列)存储大量数据通常是最可行的方法。RAID可以帮助做冗余、扩展存储容量、缓存,以及加速。但是从我们看到的一些优化案例来说,RAID上有多种多样的配置,为需求选择一个合适的配置非常重要。
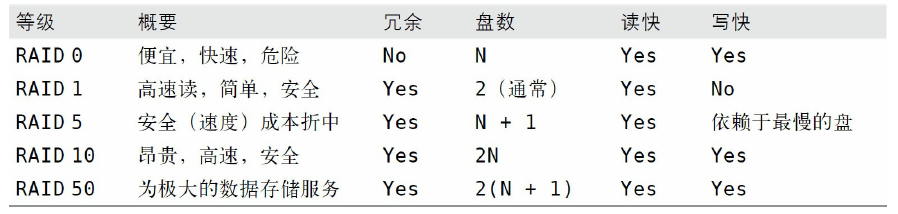
RAID 0
如果只是简单地评估成本和性能,RAID 0是成本最低和性能最高的RAID配置(但是,如果考虑数据恢复的因素,RAID 0的代价会非常高)。因为RAID 0没有冗余,建议只在不担心数据丢失的时候使用,例如备库或者因某些原因只是“一次性”使用的时候。典型的案例是可以从另一台备库轻易克隆出来的备库服务器。再次说明, RAID 0没有提供任何冗余,即使R在RAID中表示冗余。实际上,RAID 0阵列的损坏概率比单块磁盘要高,而不是更低!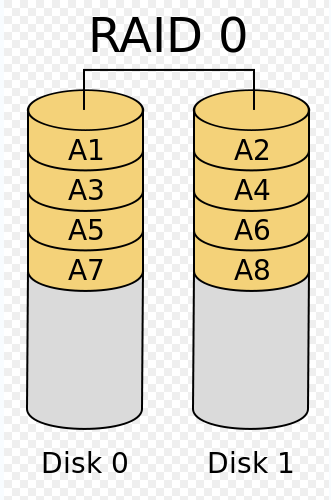
RAID 1
RAID 1在很多情况下提供很好的读性能,并且在不同的磁盘间冗余数据,所以有很好的冗余性。RAID 1在读上比RAID 0快一些。它非常适合用来存放日志或者类似的工作,因为顺序写很少需要底层有很多磁盘(随机写则相反,可以从并发中受益)。这通常也是只有两块硬盘又需要冗余的低端服务器的选择。
RAID 0和RAID 1很简单,在软件中很好实现。大部分操作系统可以很简单地用软件创建RAID 0和RAID 1。
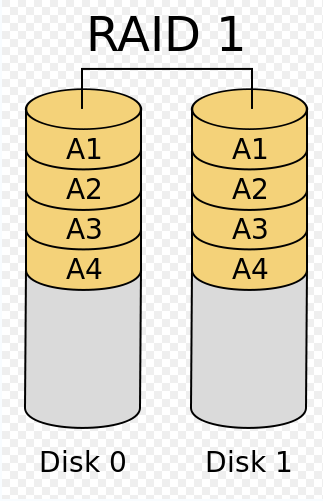
RAID 5
RAID 5有点吓人,但是对某些应用,这是不可避免的选择,因为价格或者磁盘数量(例如需要的容量用RAID 1无法满足)的原因。它通过分布奇偶校验块把数据分散到多个磁盘,这样,如果任何一个盘的数据失效,都可以从奇偶校验块中重建。但如果有两个磁盘失效了,则整个卷的数据无法恢复。就每个存储单元的成本而言,这是最经济的冗余配置,因为整个阵列只额外消耗了一块磁盘的存储空间。
RAID 10
RAID 10对数据存储是个非常好的选择。它由分片的镜像组成,所以对读和写都有良好的扩展性。相对于RAID 5,重建起来很简单,速度也很快。另外RAID 10还可以在软件层很好地实现。当失去一块磁盘时,性能下降还是比较明显的,因为条带可能成为瓶颈。性能可能下降为50%,具体要看工作负载。需要注意的一件事是,RAID控制器对RAID 10采用了一种“串联镜像”的实现。这不是最理想的实现,由于条带化的缺点是“最经常访问的数据可能仅被放置在一对机械磁盘上,而不是
分布很多份,”所以可能会遇到性能不佳的情况。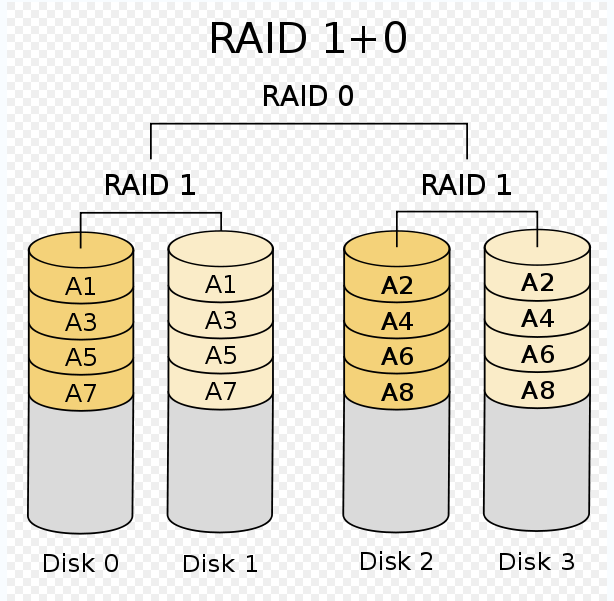
RAID 50
RAID 50由条带化的RAID5组成,如果有很多盘的话,这可能是RAID 5的经济性和RAID 10的高性能之间的一个折中。它的主要用处是存放非常庞大的数据集,例如数据仓库或者非常庞大的OLTP系统。
RAID级别选择
如果应用以随机IO为主的话,应使用raid 1+0,也就是上图的 raid 10
硬盘三大种类
硬盘三大种类:
- SSD(固态硬盘)
优点: 读写速度快;防震康率性;低功效;无噪音;工作温度范围大;轻便
缺点: 容量小;寿命有限;售价高 - HHD(混合硬盘)
- HDD (机械硬盘)
MySQL的应用是 随机读写、顺序读写都有,而且对于一些OLAP的应用,随机读写会比较多,需要使用到固态硬盘。
固态硬盘有两种接口,一种是STAT接口,一种是PCIE接口。
PCIe设备延迟也低得多,因为它们在物理上更靠近CPU。没有什么比得上从PCIe设备上获得的性能。缺点就是它们太贵了。
硬盘的选择:
- 系统盘选择 SSD
- 数据盘选择 SSD
- 日志盘选择 HDD
- 备份盘选择 HDD
如果费用足够的情况下,SSD可以使用PCIE接口。
找到有效的内存/磁盘比例
找到一个良好的内存/磁盘比例最好的方式是通过试验和基准测试。如果可以把所有东西放入内存,你就大功告成了——后面没有必要再为此考虑什么。但大多数的时候不可能这么做,所以需要用数据的一个子集来做基准测试,看看将会发生什么。测试的目标是一个可接受的缓存命中率。缓存未命中是当有查询请求数据时,数据不能在内存中命中,服务器需要从磁盘获取数据。
缓存命中率实际上也会决定使用了多少CPU,所以评估缓存命中率的最好方法是查看CPU使用率。例如,若CPU使用了99%的时间工作,用了1%的时间等待I/O,那缓存命中率还是不错的。
让我们考虑下工作集是如何影响高速缓存命中率的。首先重要的一点,要认识到工作集不仅是一个单一的数字而是一个统计分布,并且缓存命中率是非线性分布的。例如,有10GB内存,并且缓存未命中率为10%,你可能会认为只需要增加11%以上的内存,就可以降低缓存的未命中率到0。但实际上,诸如缓存单位的大小之类的问题会导致缓存效率低下,可能意味着理论上需要50GB的内存,才能把未命中率降到1%。即使与一个完美的缓存单位相匹配,理论预测也可能是错误的:例如数据访问模式的因素也可能让事情更复杂。解决1%的缓存未命中率甚至可能需要500GB的内存,这取决于具体的工作负载!
有时候很容易去优化一些可能不会带来多少好处的地方。例如,10%的未命中率可能导致80%的CPU使用率,这已经是相当不错的了。假设增加内存,并能够让缓存未命中率下降到5%,简单来说,将提供另外约6%的数据给CPU。再简化一下,也可以说,把CPU使用率增加到了84.8%。然而,考虑到为了得到这个结果需要购买的内存,这可不一定是一个大胜利。在现实中,因为内存和磁盘访问速度之间的差异、CPU真正操作的数据,以及许多其他因素,降低缓存未命中率到5%可能都不会太多改变CPU使用率。
这就是为什么我们说,你应该争取一个可接受的缓存命中率,而不是将缓存未命中率降低到零。没有一个应该作为目标的数字,因为“可以接受”怎么定义,取决于应用程序和工作负载。有些应用程序有1%的缓存未命中都可以工作得非常好,而另一些应用实际上需要这个比例低到0.01%才能良好运转。(“良好的缓存未命中率”是个模糊的概念,其实有很多方法来进一步计算未命中率。)
最好的内存/磁盘的比例还取决于系统上的其他组件。假设有16 GB的内存、20GB的数据,以及大量未使用的磁盘空间系统。该系统在80%的CPU利用率下运行得很好。如果想在这个系统上放置两倍多的数据,并保持相同的性能水平,你可能会认为只需要让CPU数量和内存量也增加到两倍。然而,即使系统中的每个组件都按照增加的负载扩展相同的量(一个不切实际的假设),这依然可能会使得系统无法正常工作。有20GB数据的系统可能使用了某些组件超过50%的容量——例如,它可能已经用掉了每秒I/O最大操作数的80%。并且在系统内排队也是非线性的。服务器将无法处理两倍的负载。因此,最好的内存/磁盘比例取决于系统中最薄弱的组件。
网络资源
就像延迟和吞吐量是硬盘驱动器的限制因素一样,延迟和带宽(实际上和吞吐量是同一回事)也是网络连接的限制因素。对于大多数应用程序来说,最大的问题是延时。典型的应用程序都需要传输很多很小的网络包,并且每次传输的轻微延迟最终会被累加起来。
运行不正常的网络通常也是主要的性能瓶颈之一。丢包是一个普遍存在的问题。即使1%的丢包率也足以造成显著的性能下降,因为在协议栈的各个层次都会利用各种策略尝试修复问题,例如等待一段时间再重新发送数据包,这就增加了额外的时间。
一个常见的问题是域名解析系统(DNS)损坏或者变慢了,可以skip_name_resolve,用户账户必须在host列使用具有唯一性的IP地址,“localhost”或者IP地址通配符。那些在host列使用主机名的用户账户都将不能登录。
典型的Web应用中另一个常见的问题来源是TCP积压,可以通过MySQL的back_log选项来配置。这个选项控制MySQL的传入TCP连接队列的大小。在每秒有很多连接创建和销毁的环境中,默认值50是不够的。设置不够的症状是,客户端会看到零星的“连接被拒绝”的错误,配以三秒超时规则。在繁忙的系统中这个选项通常应加大。把这个选项增加到数百甚至数千,似乎没有任何副作用,事实上如果你看得远一些,可能还需要配置操作系统的TCP网络设置。在GNU/Linux系统,需要增加somaxconn限制,默认只有128,并且需要检查sysctl的tcp_max_syn_back_log设置.
应该设计性能良好的网络,而不是仅仅接受默认配置的性能。首先,分析节点之间有多少跳跃点,以及物理网络布局之间的映射关系。例如,假设有10个网页服务器,通过千兆以太网(1 GigE)连接到“网页”交换机,这个交换机也通过千兆网络连接到“数据库”交换机。如果不花时间去追踪连接,可能不会意识到从所有数据库服务器到所有网页服务器的总带宽是有限的!并且每次跨越交换机都会增加延时。
监控网络性能和所有网络端口的错误是正确的做法,要监控服务器、路由器和交换机的每个端口。多路由流量绘图器(Multi Router Traffic Grapher),或者说MRT(http://oss.oetiker.ch/mrtg/),对设备监控而言是个靠得住的开源解决方案。其他常见的网络性能监控工具(与设备监控不同)还有Smokeping(http://oss.oetiker.ch/smokeping/)和Cacti(http://www.cacti.net)。
网络物理隔离也是很重要的因素。城际网络相比数据中心的局域网的延迟要大得多,即使从技术上来说带宽是一样的。如果节点真的相距甚远,光速也会造成影响。物理距离不仅是性能上的考虑,也包括设备之间通信的考虑。中继器、路由器和交换机,所有的性能都会有所降级。再次,越广泛地分隔开的网络节点,连接的不可预知和不可靠因素越大。
尽可能避免实时的跨数据中心的操作是明智的。如果不可能做到这一点,也应该确保应用程序能正常处理网络故障。例如,我们不希望看到由于Web服务器通过丢包严重的网络连接远程的数据中心时,由于Apache进程挂起而新建了很多进程的情况发生。
在本地,请至少用千兆网络。骨干交换机之间可能需要使用万兆以太网。如果需要更大的带宽,可以使用网络链路聚合:连接多个网卡(NIC),以获得更多的带宽。链路聚合本质上是并行网络,作为高可用策略的一部分也很有帮助。
如果需要非常高的吞吐量,也许可以通过改变操作系统的网络配置来提高性能。如果连接不多,但是有很多的查询和很大的结果集,则可以增加TCP缓冲区的大小。具体的实现依赖于操作系统,对于大多数的GNU/Linux系统,可以改变/etc/sysctl.conf中的值并执行sysctl-p,或者使用/proc文件系统写入一个新的值到/proc/sys/net/里面的文件。搜索“TCP tuning guide”,可以找到很多好的在线教程。