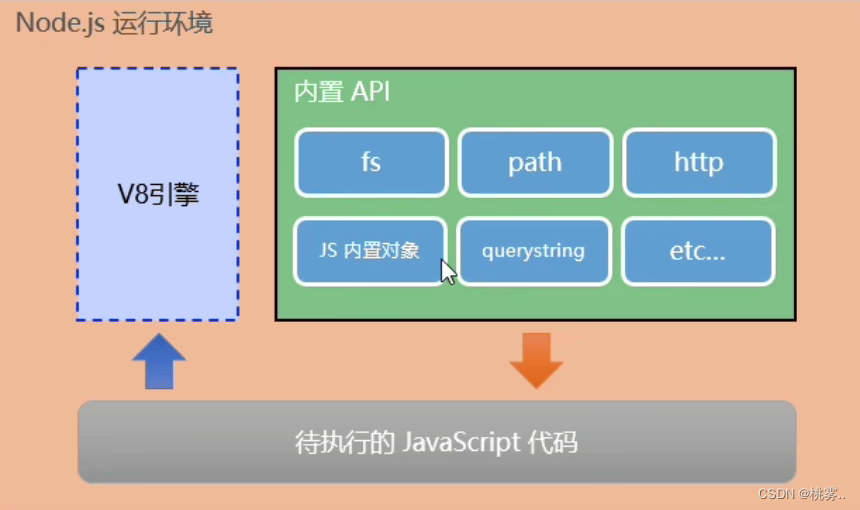
产生原因
在之前,数据量小,增长速度慢,且数据基本都是文件。储存和处理这些数据并不麻烦,单个存储单元和处理器组合就可以。
之后随着互联网发展,产生了大量多种形式的数据。
非结构化数据:邮件、图像、音频和视频等形式。这些与结构化数据一起称为大数据。此时,储存单元和处理器的组合显然不够
如何解决?
引入了hadoop框架,它通过使用硬件集群,可以有效地存储和处理大量数据
三大组件:HDFS、MapReduce、YARN
第一步存储数据
HDFS分布式文件系统,数据分布在许多计算机中并以块的形式存储。HDFS将数据存储在多个数据块上。如果其中一个数据点崩溃了–不会导致损失任何数据
HDFS对数据进行拷贝并将其存储在多个系统中。复制方法
第二步:数据处理。
之前放在单个处理器上处理,低效且费时。
MapReduce将数据分成多个部分,并在不同的数据节点上分别处理每个部分。然后将各个结果汇总并最终输出
例如统计文章中每个单词出现的次数:
步骤:输入 – 分割成不同的小部分 – 每一个部分进行分词统计 – 按同一个单词排序 – 汇总计数

这改善了负载平衡并节约了时间
第三步:
每个任务都需要硬件资源来支持完成,为了有效的管理这些资源,用到了第三个组件YARN
除了这三大组件外,HADOOP还有各种大数据工具和框架。专门用于管理、分析和处理数据,例如hive spark flume 和scoop等等
HDFS的三种模式的优势?
- 支持并行处理
- 更快的数据分析
- 确保容错
- 管理集群资源
概念理解
分布式:将不同的业务分布在不同的地方
集群:将几台服务器集中在一起,实现同一个业务
微服务:一种架构风格
岗位区别:
做菜过程:采购(数据开发)、清洗(ETL)、备菜(ETL)、摆盘(BI)、烹饪(数据分析)
hadoop主要要学的
三大组件:HDFS、MapReduce、YARN
学习对象:中台(集群+数据中台)+数据开发(算法,实时,离线),大学生