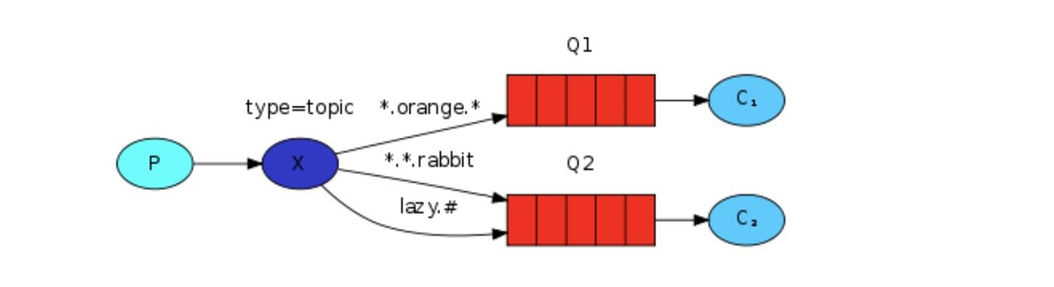
SAS在最新的展示图,表现力比较丰富。
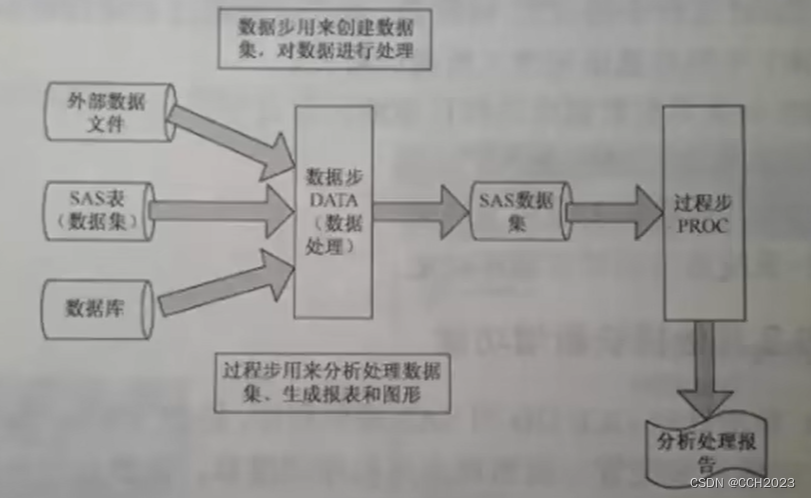
SAS的处理流程:
数据步 过程步:
ETL是数据分析非常重要的步骤。70%-90%花在收集数据以及整理数据,数据分析数据的时间不是很多的。
一个完整的数据步和过程步:

数据步基本语句总结:
DATA
INPUT (难度最大)
DATALINES(CARDS)和ATALINES
LENGTH
LABEL
LOSTCARD
INFORMAT/FORMAT
MISSING
OPTIONS
DATA语句:
格式:DATA <数据集名> <选项>
常用选项:label=为数据集提供标记;DROP=列出不包括在数据集中的变量
缺省逻辑库为work
同一次会话过程中,可以有多个DATA语句创建多个数据集。最后建立的为当前数据集
如果分析工作不需要建立数据集,DATA语句中的数据集名可以用_NULL_
说明:
1)sas关闭,临时数据库work中的数据集会被删除掉;那么就要创建永久数据集;
DATA例子:当前数据集
data student;
input num $ name $ sex $;
datalines;
060101 zhangsan f
060102 liling m
060201 liufeng f
data score;
input num $ phy math engl;
datalines;
060101 89 90 77
060102 92 70 88
060201 80 84 75
proc print;
/* proc print data=student; */
run;代码说明:
1)input语句 定义内置数据中定义三个变量,后面跟$,表示读入的字符的变量。
2)datalines:相当于cards,用来定义内置数据。
3)proc print; 输出的是哪个数据集呢?默认是输出最后的数据集,就是当前数据集score;
4)proc print data=student; 指定数据集student输出。
DATA 例子:空数据集
data _null_;
a = sin(3.14159/4);
put a;
run;代码说明:
1)定义一个变量a,值是正弦函数;
2)put a: /* 显示a的值 */
3)data _null_: 定义空的数据集,产生的变量也不会放到数据集,在硬盘中不会产生任何东西。
DATA例子:永久数据集
libname ep 'e:\saslx';
data ep.students;
input num $ name $ sex $ h w;
datalines;
020801 zhangling f 1.56 47.1
020802 zhaohua m 1.72 61.5
030813 wangqang m 1.69 64.5
030824 liuli f 1.58 53.6
030815 shidong f 1.60 48.0
;
proc print;
run;
建立永久数据集后, 下次可以直接调用
libname ep 'e:\saslx';
proc print data=ep.students;代码说明:
1)创建逻辑库ep,对应硬盘中的e盘的某目录路径;
2)指定的数据集是ep下面的students数据集;
3)然后输出;
4)下次再登录,可以输出ep.students,说明数据被永久保存在硬盘中。
INPUT语句:在数据步中最关键的部分。
用于描述输入的数据。从外部文件infile或紧跟的CARDS读入数据,赋给该语句列出的各个变量。每个列应该怎么读,它的类型是什么样的。
格式:INPUT <数据项描述>......中间用空格分开就行了。
一般认为读入的数据是数值型,除非:1 变量名后有$号,2 使用字符的输入格式表示;3 变量事先被定义成字符型;
数据中的缺项值用"." 表示。如果读入数据与数据类型不匹配,则按无效数据置为缺项值;
说明:
1)数据项描述:中间默认用空格分开就行;
2)数据中有空值,在SAS中,是用缺项值表示,缺失值。缺项值用一点来表示。
3)数据与数据类型不匹配,则为缺失值。
INPUT语句:数据项描述
方法一:列表或自由格式;
方法二:列
方法三:格式化
列表输入:
格式:INPUT 变量名 [$] ....;
对输入数据的要求:1)输入数据项之间至少被1个空格分隔;2)用句号表示缺失值;3)字符型变量缺省默认最大长度为8,除非用LENGTH、ATTRIB、INFORMAT等语句给定更长的长度;INPUT语句中列出的变量顺序要跟输入数据的顺序一致。
如果INPUT后变量数量少于输入数据中的列数,则后面的列被略去
如果输入数据前后包含空格,会被判为作为分隔符的空格
说明:
1)没有$,就是数值型,有$,就是字符型;
2)至少一个空格;列之间连在一起没有空格,INPUT就无法辨认;
3)用英文句号来表示缺失值;
4)变量的长度的重新定义;
INPUT语句:列输入:
格式: INPUT变量名[$] 开始列[-结束列];
输入值可以以任何的次序读入,而不管它们在输入记录中的位置;
字符型数据可以包含空格。全部是空格或只含一个"."的字段被解释为缺失值。
可读全部或者部分数据
DATA;
input ID $1-18 birthyear 7-10 name $ 19-29;
Age = YEAR(DATE())-birthyear;
DATALINES;
210103195909123912zhanglin
210104195007231234liuli
211110195208113421linzexu
;
proc print;
run;代码说明:
1)这是列输入,ID是从第1个字符到第18个字符;birthyear 是从第7个字符到第10个字符,每个字符都是一列。name:就是从第19个列到第29列,就是从19个字符到29个字符;
2)AGE DATE,SAS是从60年代就有了,SQL通用语言有很多地方借鉴了SAS。
3)AGE这列是通过赋值语句产生的。
格式化输入:
格式:INPUT变量名 <修饰符> 输入格式....;
输入格式例子:INPUT name $10. birthday mmddyy10. weight 4.1; (解释)
说明:10. 是输入格式。mmddyy10. 表示的是10位的mmddyy格式。4.1 数字有4位这么长,保留小数点1位。
DATA days;
INPUT num $3. name $14. birthday mmddyy8. weight 4.1;
DATALINES;
081ZHANGLIN 7-21-86 60.5
082ZHAOHUA 10/30/86640
083WANGQANG 06 19 8659.5
084LIULI 03 07 8763
;
proc print;
run;
数据中的年月日之间应用特殊符号或空格隔开。格式化输入时,数据项不再以空格作为结束标志,而是由读指针按给出的格式长度移动,依次读数据项。数据前后的空格也要计算在内。

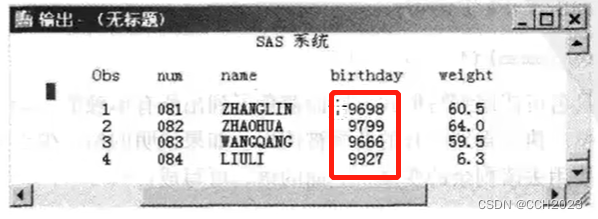
1)我们看到时间显示比较特别;birthday不是我们能认识的时间,直观看起来从某年某月某日的天数。mysql中是从1970年开始进行的。
2)weight:640,读出来的是64.0,SAS是先把小数点后一位先读出来;63,SAS先把3先作为小数点后面读出来。

FORMAT语句的使用。是worddate格式显示的。
INPUT语句:格式列表
例子:
input(score1-score5)(4. 4. 4. 4. 4.);
input(score1-score5)(4.);
input(name score1-score5)($10. 5*4.);代码说明:
1)score1是数值型,4位;
2)第二行,4. 表示所有的变量都是4位宽;
3)第三行:$10. 表示10个字符长,5*4. 表示5个变量全部都是4位。