论文阅读【PAMI_2022】FSGANv2: Improved Subject Agnostic Face Swapping and Reenactment
- 论文的缩写全拼
- 一、摘要(问题,贡献,效果)
- 二、引言(idea)
- 三、方法(FSGAN)
- 1.Detection and tracking
- 2.Generator architecture
- 3.Training losses
- 1.Domain specific perceptual loss
- 2.Reconstruction loss
- 3.Adversarial loss
- 4.Face Segmentation
- 5.Face reenactment
- 1.Landmarks transformer
- 2.Landmarks heatmaps
- 3.Training

论文地址:https://arxiv.org/abs/2202.12972
项目地址:https://github.com/YuvalNirkin/fsgan
将源图片的身份信息交换到目标视频中,保持表情和姿势不变。
We present Face Swapping GAN (FSGAN) for face swapping and reenactment.
我们提出了用于面部交换和再现的面部交换GAN (FSGAN)。
论文的缩写全拼
| 英文 | 中文 |
|---|---|
| the dual-shot face detector (DSFD) | 双镜头人脸探测器 |
一、摘要(问题,贡献,效果)
一、贡献
Unlike previous work, we offer a subject agnostic swapping scheme that can be applied to pairs of faces without requiring training on those faces.
与以前的工作不同,我们提供了一种与主题无关的交换方案,该方案可以应用于成对的面孔,而无需对这些面孔进行训练。
We derive a novel iterative deep learning–based approach for face reenactment which adjusts significant pose and expression variations that can be applied to a single image or a video sequence.
我们推导了一种新颖的基于迭代深度学习的人脸再现方法,该方法可调整可应用于单个图像或视频序列的显着姿势和表情变化。
For video sequences, we introduce a continuous interpolation of the face views based on reenactment, Delaunay Triangulation,and barycentric coordinates. Occluded face regions are handled by a face completion network.
对于视频序列,我们基于再现,Delaunay三角剖分和重心坐标引入人脸视图的连续插值。
遮挡的面部区域由面部完成网络处理。
Finally, we use a face blending network for seamless blending of the two faces while preserving the target skin color and lighting conditions.
最后,我们使用面部混合网络来无缝混合两个面部,同时保留目标肤色和照明条件。
二、效果
This network uses a novel Poisson blending loss combining Poisson optimization with a perceptual loss. We compare our approach to existing state-of-the-art systems and show our results to be both qualitatively and quantitatively superior.
该网络使用新颖的Poisson混合损失,将Poisson优化与感知损失相结合。我们将我们的方法与现有的最先进的系统进行了比较,并证明我们的结果在质量和数量上都优越。
This work describes extensions of the FSGAN method, proposed in an earlier conference version of our work [1], as well as additional experiments and results.
这项工作描述了在我们工作的早期会议版本 [1] 中提出的FSGAN方法的扩展,以及其他实验和结果。
索引术语
Face Swapping, Face Reenactment, Deep Learning
换脸、重现脸、深度学习
摘要没有提及现有方法存在的问题,应该是文章提出了一种更优的面部交换和再现方法。
二、引言(idea)
| 方法 | 介绍 |
|---|---|
| Face Swapping | 面部交换是面部从源图像到目标图像的视觉变换,使得所得到的图像无缝地替换出现在目标图像中的面部,如图1所示。 |
| Face Reenactment | 面部再现 (也称为面部转移或伪造) 利用一个视频中的控制面部的面部运动和表情来引导出现在另一个视频或图像中的第二面部的运动和变形 (图1)。 |
idea
Most contemporary works proposed methods for either swapping or reenactment, but rarely both, relying on underlying 3D face representations to transfer the face appearance.
大多数当代作品都提出了用于交换或重演的方法,但很少有两者结合的。依赖于底层3D面部表示来转移面部外观。
方法
Face shapes were estimated from the input image, or kept fixed. The 3D shape was then aligned with the input images and used as a proxy to transfer the image appearance (swapping) or controlling the facial expression and viewpoint (reenactment).
面部形状是根据输入图像或保持固定。然后将3D形状与输入图像对齐,并用作代理以传输图像外观 (交换) 或控制面部表情和视点 (再现)。
问题
Some methods applied domain separation in latent feature spaces[26], [27], [28], to decompose the identity component of
a face from the other traits, such as pose and expression.
一些方法在潜在特征空间中应用域分离[26], [27], [28],将面部的身份成分从其他特征 (例如姿势和表情) 中分解出来。
The identity is encoded as the manifestation of latent feature vectors, resulting in significant information loss and limiting the quality of the synthesized images.
身份被编码为潜在特征向量的表现形式,从而导致大量信息丢失并限制了合成图像的质量。
Subject-specific approaches [13], [23], [25], [29] are particularly trained for each subject or pair of subjects to be swapped or reenacted.
特定于主题的方法 [13],[23],[25],[29] 特别针对要交换或重新制定的每个主题或一对主题进行了训练。
Thus, requiring significant training sets per subject, to achieve reasonable results, limiting their potential usage.
因此,每个受试者需要大量的训练集,以获得合理的结果,从而限制了它们的潜在使用。
A major concern shared by previous face synthesis schemes, particularly the 3D-based methods, is that they all require particular care to handle partially occluded faces.
以前的面部合成方案 (尤其是基于3d的方法) 共同关心的主要问题是,它们都需要特别注意以处理部分遮挡的面部。
对于先前工作的提升
We provide a means for interpolating between face landmarks without relying on 3D information using a face
landmarks transformer network.
我们提供了一种使用人脸地标变压器网络在不依靠3D信息的情况下在人脸地标之间进行插值的方法。
We improve the inpainting generator by adding symmetry and face landmarks cues.
我们通过添加对称性和面部地标提示来改进修补生成器。
We completely revise the preprocessing pipeline and add a postprocessing step, to reduce the jittering and saturation artifacts of our previous method.
我们完全修改了预处理管道,并添加了后处理步骤,以减少先前方法的抖动和饱和伪影。
Finally, we show additional qualitative and quantitative experiments with a new metric for comparing expressions.
最后,我们展示了使用新的度量来比较表达式的其他定性和定量实验。
总结的主要贡献
1.A face landmarks transformer network for interpolating between face landmarks without 3D information.
一种用于在没有3D信息的面界标之间进行插值的面界标transformer 网络。
2.Improved inpainting generator that utilizes symmetry and face landmarks cues.
改进的修补生成器,利用对称性和面部地标提示。
3.A demonstration of an additional use case for the new face reenactment method for pose-only face reenactment.
演示了用于仅姿势面部再现的新面部再现方法的附加用例。
4.Completely revised preprocessing and an additional postprocessing step for reducing hittering and saturation artifacts.
完全修订的预处理和额外的后处理步骤,用于减少打乱和饱和伪影。
5.Introduction of a new metric for facial expression comparison.
介绍了一种新的面部表情比较指标。
6.Additional quantitative and qualitative experiments and ablation studies using new metrics.
使用新指标进行额外的定量和定性实验以及消融研究。
三、方法(FSGAN)
先看图overview:

Is是source face images,Fs ∈ Is
It是target face images,Ft ∈ It目标是基于It,并且Ft被Fs无缝的取代,同时保持相同的姿势和表情。
Gr是The recurrent reenactment generator(循环再现生成器)
- 输入:热图编码Ft的面部地标(heatmaps encoding the facial landmarks of Ft)
- 输出:重新制定的图像,Ir(the reenacted image, Ir)它还计算Sr。
Sr即Fr的分割面具。(segmentation mask)
同理St即It的分割面具。
Fr表示Fs具有与Ft相同的姿势和表情。
Gs是the segmentation generator(分段生成器)
- 功能:计算Ft的面部和头发的分割面具。
考虑到重新制定的图像,Ir,可能会丢失面部部分。
Gc是The inpainting generator (修复生成器)或完成生成器(completion generators)
- 功能:基于St对 F r的缺失部分进行修复,以估计完成的重新制定面,Fc
Fc是the completed reenacted face(完整的重新制作的脸)
Gb是混合生成器(The blending generator)
- 功能:利用分割面具St对将Fc与Ft混合。
其中Gs基于U-Net [50],采用双线性插值进行上采样,
Gr, Gc, and Gb基于pix2pixHD体系结构 [21],使用了粗到精生成器和多尺度鉴别器。
1.Detection and tracking
使用在WLFW数据集上训练的2D面部标志 [55] 跟踪面部表情,每个面部包含98个点。在我们之前的工作中,我们使用了68个点的2D和3D地标 [56]。
2.Generator architecture


3.Training losses
1.Domain specific perceptual loss
其中
F
i
∈
R
C
i
×
H
i
×
W
i
F_i\in \mathbb{R}^{C_i\times H_i\times W_i}
Fi∈RCi×Hi×Wi
作为VGG-19网络第i层的特征图
感知损失函数如下:
其中其中Ci是通道数,Hi和Wi是高度和宽度尺寸。

2.Reconstruction loss
虽然感知损失 (如第3.3.1节) 很好地捕获了高频,但仅使用该损失训练的生成器通常会产生具有不准确颜色的图像,这与低频图像内容的错误重建相对应。

overall loss:

3.Adversarial loss

discriminator有很多个。
4.Face Segmentation
Gs输出包括三个部分:背景、脸和头发。
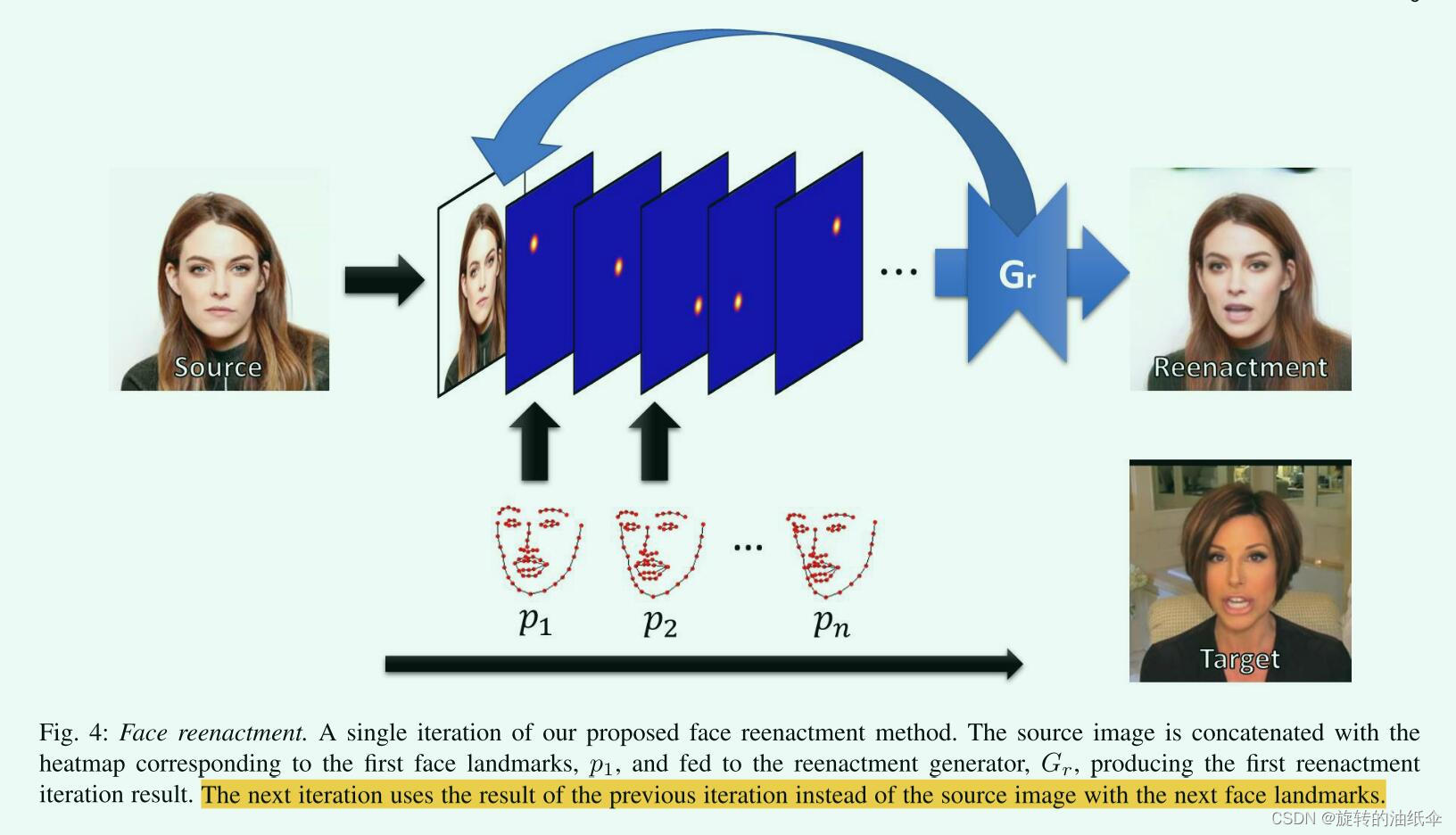
5.Face reenactment
A single iteration of our proposed face reenactment method.
1.Landmarks transformer
2.Landmarks heatmaps
3.Training
待补充