数仓理论
1 范式理论
1.1 范式概念
数据建模要遵循一定的规则,在关系建模中,这种规则就是范式
采用范式结构,可以有效的降低数据的冗余性
范式在获取数据时,需要通过join拼接出数据
范式有第一范式(1NF),第二范式(2NF),第三范式(3NF),巴斯-科德范式(BCNF),第四范式(4NF),第五范式(5NF)
一般只遵循到第三范式
1.2 函数依赖
1.2.1 完全函数依赖
通过(学号,课程)可以推断出分数,但是单独用学号或者课程都不能推断出分数,这时可以说分数完全依赖于(学号,课程)
即AB能推断出C,但是A和B单独不能推断出C,这时C完全依赖于AB
1.2.2 部分函数依赖
通过(学号,课程)可以推断出姓名,但是只通过学号就能推断出姓名,这时可以说姓名部分依赖于(学号,课程)
即AB能得出C,A或B单独也能得出C,这时C部分依赖于AB
1.2.3 传递函数依赖
学号可以推断出学院名,学院名可以推断出院长,但是院长推断不出来学号,这时可以说院长传递依赖于学号
即A得出B,B得出C,但是C得不到A,这时C传递依赖于A
1.3三范式的区分
1.3.1 第一范式
1NF的核心原则为:属性不可切割
比如下面的表格,商品列中的数据可以分割成 3台 和 电脑 ,所以下面的表格不遵循1NF
| 商品ID | 商品 | 商家ID | 用户ID |
|---|---|---|---|
| 001 | 3台电脑 | 001 | 001 |
修改成遵循1NF的表格为
| 商品ID | 商品 | 商家ID | 用户ID | 数量 |
|---|---|---|---|---|
| 001 | 电脑 | 001 | 001 | 3 |
1NF时关系型数据库的最基本的要求,在RDBMS中创建表时,如果不符合1NF的要求,操作是不会成功的
1.3.2 第二范式
2NF的原则为:不存在部分函数依赖
比如下面的表格,属性不可切割,满足第一范式,但是课名不完全依赖于(学号,姓名),所以不满足2NF的要求
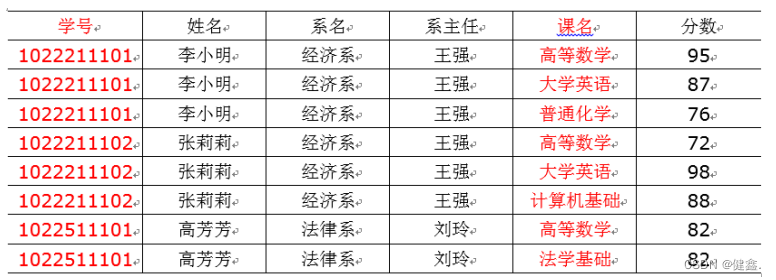
这时将表拆分成以下两个,这时就满足了2NF


1.3.3 第三范式
3NF的原则为:不存在传递函数依赖
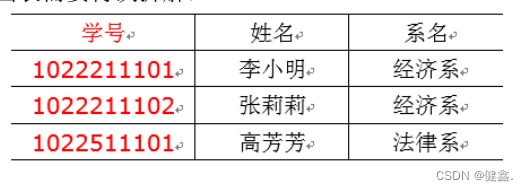
拿上面满足2NF的第二章表来说,系主任传递依赖于学号,所以需要进行进一步的拆解
拆分之后的如下两张表满足3NF

2 关系建模和维度建模
2.2 关系建模
关系建模将数据抽象成两个概念:实体和关系,使用规范化的方式表示出来,如图所示,关系建模较为松散。

关系建模遵循三范式,数据冗余性低,但是查询相对复杂,join操作比较多导致MR较多,查询效率较低
2.3 维度建模
维度建模以数据分析为出发点,不遵循三范式,存在一些数据冗余
面向业务,将业务用事实表和维度表的方式表现出来
查询效率较高

3 维度表和事实表
3.1 维度表
维度表一般是对事实的描述信息,比如:用户、商品、日期等
维度表很宽,具有多个属性,列多
与事实表相比,行数相对较小
内容相对固定
- 比如:时间维度表
| 日期ID | day of week | day of year | 季度 |
|---|---|---|---|
| 2023-2-15 | 3 | 46 | 1 |
| 2023-2-16 | 4 | 47 | 1 |
3.2 事实表
事实表中每行数据代表了一个业务事件(下单,支付等)
实时表示的是实践的度量值(次数,个数,金额等)
比如:2023年2月15日,jx在京东花了40元买了一本书
维度表存储:时间、用户、商家、商品等
实时表存储:数量、价钱(40元,一本)
一个事实表的行包括:度量值、与维度表相连的外键(通常有多个外键)
事实表非常大,相对较窄,列数较少,主要存储的是外键id和度量值
经常会发生变化,会产生很多的新增数据
3.2.1 事务型事实表
以单个事务或时间为单位
比如:一笔支付记录、一个订单记录
事实表中的一行数据,一旦事务被提交,数据被插入,就不能在进行更改
更新方式为增量同步
3.2.2 周期型快照事实表
不会保留所有的数据,只保留固定时间间隔的数据
比如:每天的营业额、每月的账户余额等
再比如:购物车随时都有可能增减商品,但是只关心每天结束时购物车的情况
3.2.3 累积型快照事实表
用于跟踪业务事实的变化
比如:要累积订单从下单开始,到订单商品打包、运输、签收的各个业务阶段的数据来追踪进展情况
这个业务进行时,事实表的记录也要不断更新
4 维度模型的分类
4.1 模型的介绍
维度模型分为三种:星型模型、雪花模型、星座模型
- 星型模型
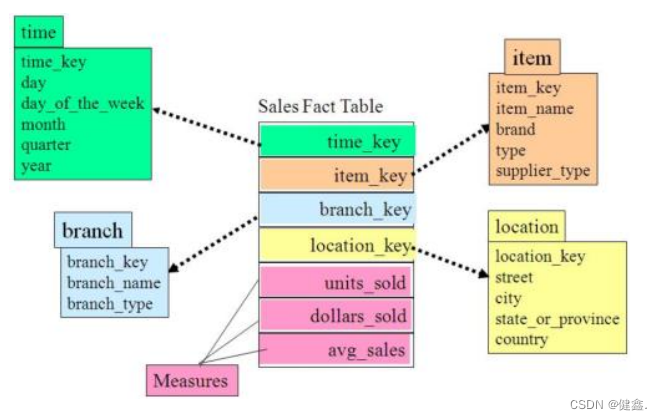
标准的星型模型只有一层
- 雪花模型
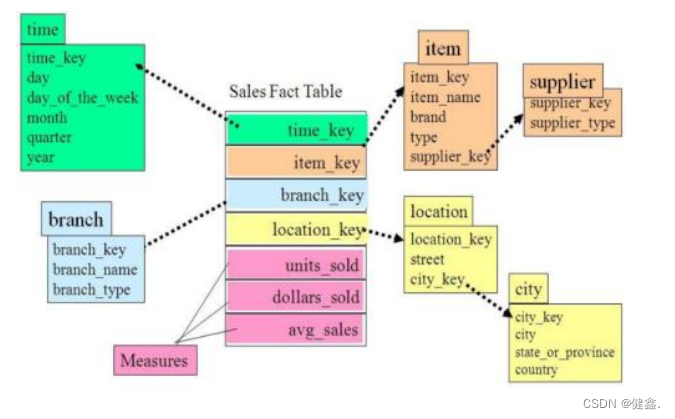
雪花模型和星型模型的区别主要在于维度的层级
雪花模型较为靠近3NF,但是无法完全遵守
- 星座模型

星座模型包含多个事实表,多个事实表共享维度表
多个星型模型或者雪花模型会形成星座模型
4.2 模型的选择
星座模型不用进行原则,多个事实表共享维度表是正常的,是数据仓库的常态
选择星型模型还是雪花模型,取决于是性能优先还是灵活优先,在实际的开发中不会只选择一种,需要根据情况灵活组合
星型模型维度更少,可以减少join,进而减少shuffle