Intervals query 根据匹配项的顺序和接近度返回文档。Intervals 查询使用匹配规则,由一小组定义构成。 然后将这些规则应用于指定字段中的术语。
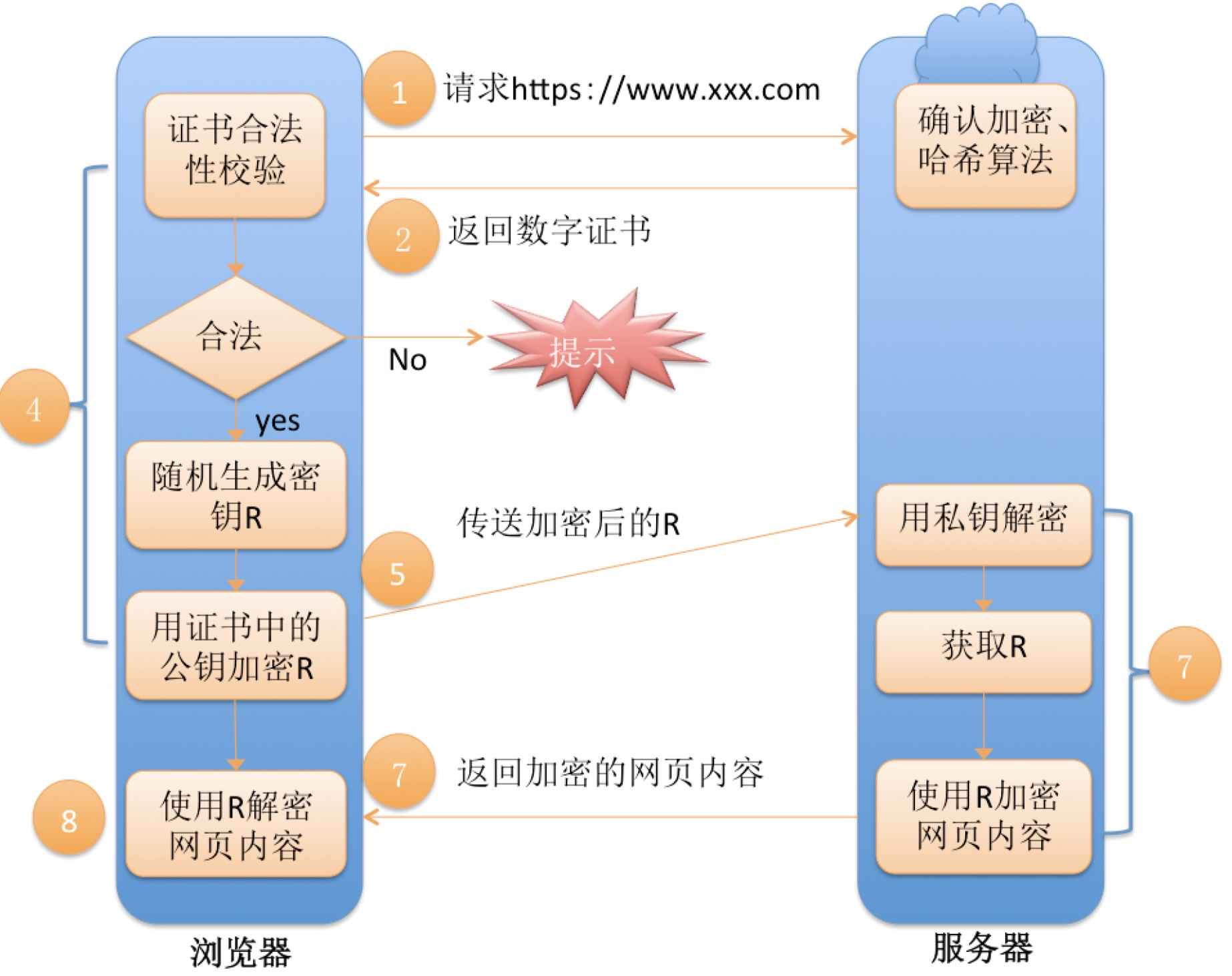
这些定义产生跨越文本正文中的术语的最小间隔序列。 这些间隔可以通过父源进一步组合和过滤。
上述描述有点费解。我们先用一个简单的例子来进行说明。
示例请求
以下 intervals 搜索返回在 my_text 字段中包含 my favorite food 的文档,并且没有任何间隙,紧接着是在 my_text 字段中包含 hot water 或者 cold porridge。
此搜索将匹配 my_text 字段值为 my favorite food is cold porridge,但是 它不匹配 my_text 的值是 it's cold my favorite food is porridge。
我们首先来写入如下的两个文档:
PUT intervals_index/_doc/1
{
"my_text": "my favorite food is cold porridge"
}
PUT intervals_index/_doc/2
{
"my_text": "it's cold my favorite food is porridge"
}
PUT intervals_index/_doc/3
{
"my_text": "he says my favorite food is banana, and he likes to drink hot water"
}
PUT intervals_index/_doc/4
{
"my_text": "my favorite fluid food is cold porridge"
}
PUT intervals_index/_doc/5
{
"my_text": "my favorite food is banana"
}
PUT intervals_index/_doc/6
{
"my_text": "my most favorite fluid food is cold porridge"
}我做如下的查询:
GET intervals_index/_search
{
"query": {
"intervals" : {
"my_text" : {
"all_of" : {
"ordered" : true,
"intervals" : [
{
"match" : {
"query" : "my favorite food",
"max_gaps" : 0,
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "hot water" } },
{ "match" : { "query" : "cold porridge" } }
]
}
}
]
}
}
}
}
}上面命令返回的结果为:
{
"took": 473,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.3333333,
"hits": [
{
"_index": "intervals_index",
"_id": "1",
"_score": 0.3333333,
"_source": {
"my_text": "my favorite food is cold porridge"
}
},
{
"_index": "intervals_index",
"_id": "3",
"_score": 0.111111104,
"_source": {
"my_text": "he says my favorite food is banana, and he likes to drink hot water"
}
}
]
}
}从返回的结果中,我们可以看出来文档 1 及 3 匹配。其原因很简单。两个文档中都含有 my favorite food,并且在它的后面还接着 cold porridge 或者 hot water 尽管它们还是离它们有一定的距离。文档 4 没有匹配是因为在 my favorite food 中间多了一个 fluid 单词。我们在查询的要求中说明 max_gaps 为 0。如果我做如下的查询:
GET intervals_index/_search
{
"query": {
"intervals" : {
"my_text" : {
"all_of" : {
"ordered" : true,
"intervals" : [
{
"match" : {
"query" : "my favorite food",
"max_gaps" : 1,
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "hot water" } },
{ "match" : { "query" : "cold porridge" } }
]
}
}
]
}
}
}
}
}在上面,我们设置 max_gaps 为 1,那么匹配的结果变为:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.3333333,
"hits": [
{
"_index": "intervals_index",
"_id": "1",
"_score": 0.3333333,
"_source": {
"my_text": "my favorite food is cold porridge"
}
},
{
"_index": "intervals_index",
"_id": "4",
"_score": 0.25,
"_source": {
"my_text": "my favorite fluid food is cold porridge"
}
},
{
"_index": "intervals_index",
"_id": "3",
"_score": 0.111111104,
"_source": {
"my_text": "he says my favorite food is banana, and he likes to drink hot water"
}
}
]
}
}很显然这次文档 4,也即 my favorite fluid food is cold porridge 也被搜索到。而文档 6,也即 my most favorite fluid food is cold porridge 没有被搜索到。
Intervals query 解决的问题
我们在一些论坛上经常看到一个非常常见的问题:“我如何创建一个匹配的查询,同时保留搜索词的顺序?”
他们中的许多人首先尝试使用 match_phrase,但有时他们也想使用 fuzzy 逻辑,而这不适用于 match_phrase。
在很多解决方案中我们可以发现使用 Span Queries 可以解决问题,但是很多问题可以通过使用 Intervals Query 来完美解决。
Intervals Query是一种基于顺序和匹配规则的查询类型。 这些规则是你要应用的查询条件。
今天我们可以使用以下规则:
- match:match 规则匹配分析的文本。
- prefix:prefix 规则匹配以指定字符集开头的术语
- wildcard:wildcard(通配符)规则使用通配符模式匹配术语。
- fuzzy:fuzzy 规则匹配与给定术语相似的术语,在 Fuzziness 定义的编辑距离内。
- all_of:all_of 规则返回跨越其他规则组合的匹配项。
- any_of:any_of 规则返回由其任何子规则生成的 intervals。
示例
我们先准备数据。我们想创建如下的一个 movies 的索引:
PUT movies
{
"settings": {
"analysis": {
"analyzer": {
"en_analyzer": {
"tokenizer": "standard",
"filter": [
"lowercase",
"stop"
]
},
"shingle_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"shingle_filter"
]
}
},
"filter": {
"shingle_filter": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "en_analyzer",
"fields": {
"suggest": {
"type": "text",
"analyzer": "shingle_analyzer"
}
}
},
"actors": {
"type": "text",
"analyzer": "en_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"description": {
"type": "text",
"analyzer": "en_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"director": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"genre": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"metascore": {
"type": "long"
},
"rating": {
"type": "float"
},
"revenue": {
"type": "float"
},
"runtime": {
"type": "long"
},
"votes": {
"type": "long"
},
"year": {
"type": "long"
},
"title_suggest": {
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
}
}
}
}我们接下来使用 _bulk 命令来写入一些文档到这个索引中去。我们使用这个链接中的内容。我们使用如下的方法:
POST movies/_bulk
{"index": {}}
{"title": "Guardians of the Galaxy", "genre": "Action,Adventure,Sci-Fi", "director": "James Gunn", "actors": "Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana", "description": "A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.", "year": 2014, "runtime": 121, "rating": 8.1, "votes": 757074, "revenue": 333.13, "metascore": 76}
{"index": {}}
{"title": "Prometheus", "genre": "Adventure,Mystery,Sci-Fi", "director": "Ridley Scott", "actors": "Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron", "description": "Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.", "year": 2012, "runtime": 124, "rating": 7, "votes": 485820, "revenue": 126.46, "metascore": 65}
....在上面,为了说明的方便,我省去了其它的文档。你需要把整个 movies.txt 的文件拷贝过来,并全部写入到 Elasticsearch 中。它共有1000 个文档。
我们想要检索符号如下条件的文件:
我们想要检索包含单词 mortal hero 的准确顺序 (ordered=true) 的文档,并且我们不打算在单词之间添加间隙 (max_gaps),因此内容必须与 mortal hero 完全匹配。
GET movies/_search
{
"query": {
"intervals": {
"description": {
"match": {
"query": "hero mortal",
"max_gaps": 0,
"ordered": true
}
}
}
}
}此搜索的结果将为空,因为未找到符合这些条件的文档。
让我们将 ordered 更改为 false,因为我们不关心顺序。
GET movies/_search
{
"query": {
"intervals": {
"description": {
"match": {
"query": "hero mortal",
"max_gaps": 0,
"ordered": false
}
}
}
}
}上面搜索的结果为:

现在我们可以看到文件已经找到了。 请注意,在文档中的 description 是 “Mortal hero”。因为我们想测试相同顺序的术语,所以我们搜索 “mortal hero”:
GET movies/_search
{
"query": {
"intervals": {
"description": {
"match": {
"query": "mortal hero",
"max_gaps": 0,
"ordered": true
}
}
}
}
}这次,我们可以看到和上面命令运行一样的结果。有一个文档被匹配。
让我们在下一个示例中使用 any_of 规则。 我们想要带有 “mortal hero” 或 “mortal man” 的文件。
GET movies/_search
{
"query": {
"intervals": {
"description": {
"any_of": {
"intervals": [
{
"match": {
"query": "mortal hero",
"max_gaps": 0,
"ordered": true
}
},
{
"match": {
"query": "mortal man",
"max_gaps": 0,
"ordered": true
}
}
]
}
}
}
}
}上面命令返回结果:

请注意,我们成功了。 返回了两个匹配的文档。
我们也可以组合规则。 在示例中,让我们搜索 “the hunger games”,结果中至少有一个是 “part 1” 或 “part 2”。 请注意,这里我们使用角色 match 和 any_of。
GET movies/_search
{
"query": {
"intervals" : {
"title" : {
"all_of" : {
"intervals" : [
{
"match" : {
"query" : "the hunger games",
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "part 1" } },
{ "match" : { "query" : "part 2" } }
]
}
}
]
}
}
}
}
}上面命令返回结果:
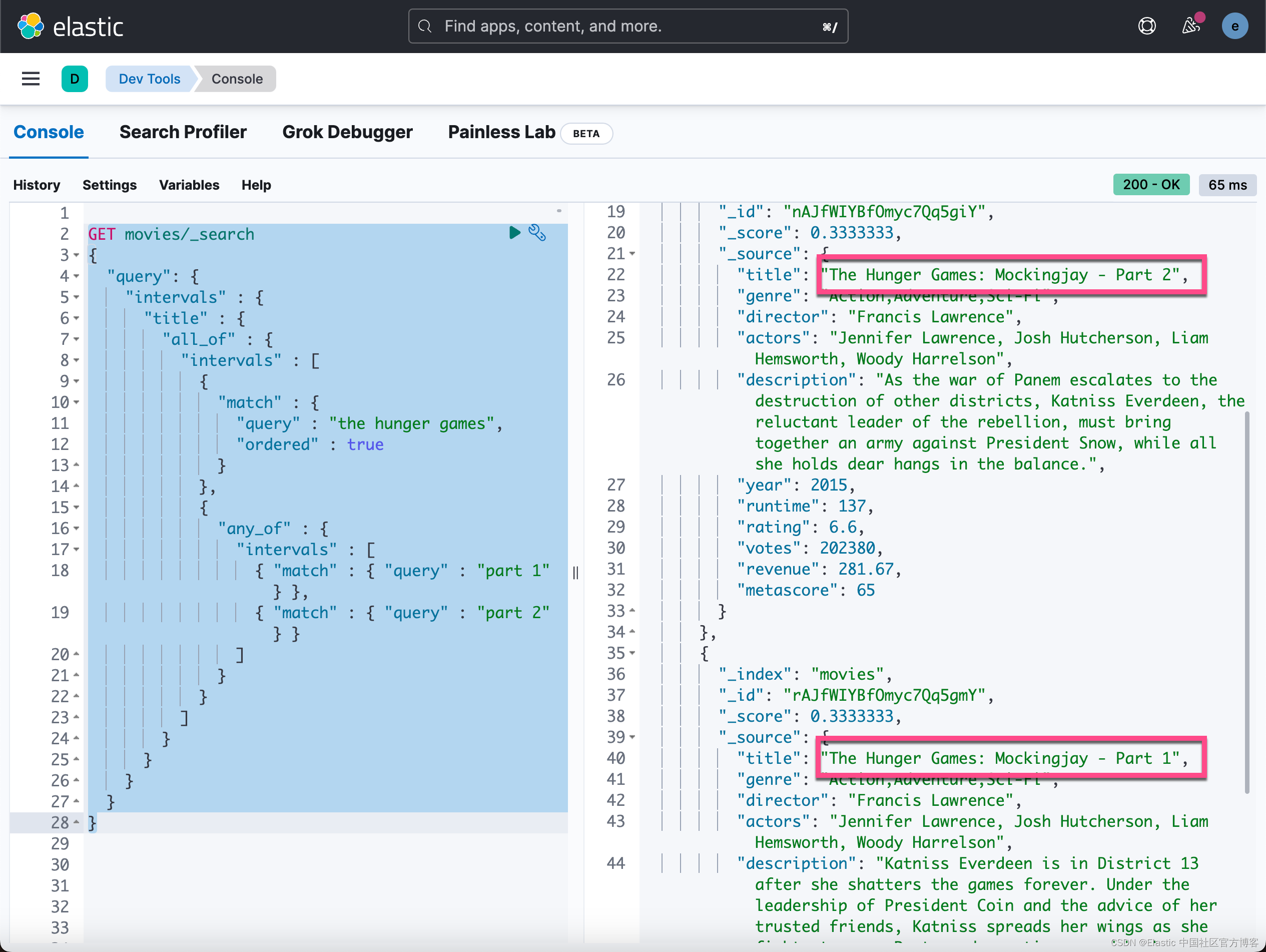
如上所示结果中只有两部电影。
间隔查询是一种按照搜索词顺序搜索文档的方法。阅读官方文档并了解如何通过它解决问题。