【参加CUDA线上训练营】共享内存实例1:矩阵转置实现及其优化①
- 1.完整代码
- 2.原理介绍
- 2.1 将各block 线程对应元素放入共享内存tile
- 2.2 实现转置
- 2.3 在此基础上修改
- 参考文献
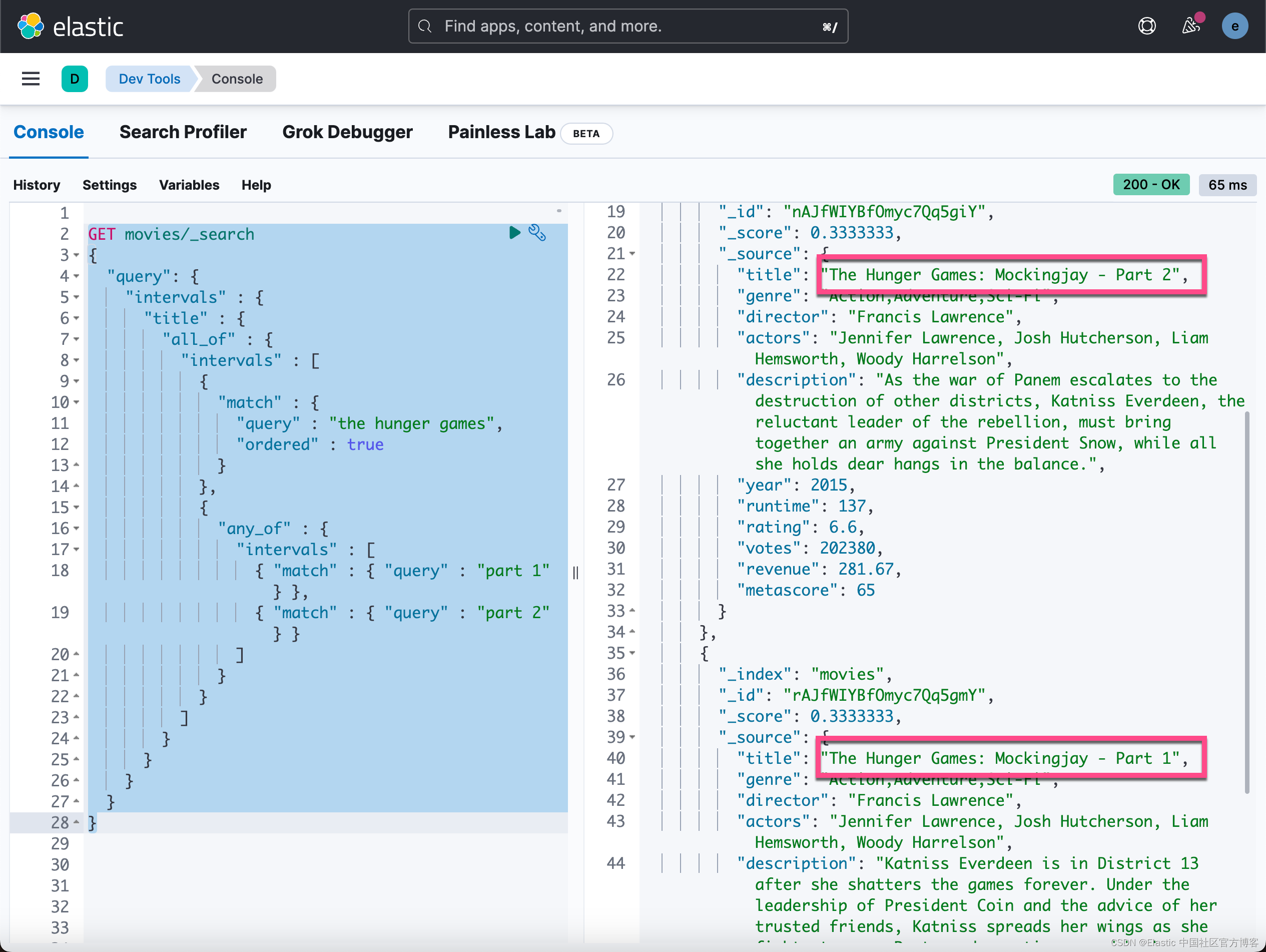
本文参考Nvidia官方blog[An Efficient Matrix Transpose in CUDA C/C++及其对应的github代码transpose.cu学习下共享内存(Shared Memory)的使用,感受下其加速效果。
使用的共享内存大小为2*2的tile,一个block中定义的线程数也是2*2。这也是本文与共享内存实例1:矩阵转置实现及其优化②的主要区别。
1.完整代码
#include "error.cuh"
#include <stdio.h>
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 10;
const int TILE_DIM = 32;
void timing(const real *d_A, real *d_B, const int N, const int task);
__global__ void transpose1(const real *A, real *B, const int N);
__global__ void transpose2(const real *A, real *B, const int N);
void print_matrix(const int N, const real *A);
int main(int argc, char **argv)
{
if (argc != 2)
{
printf("usage: %s N\n", argv[0]);
exit(1);
}
const int N = atoi(argv[1]);
const int N2 = N * N;
const int M = sizeof(real) * N2;
real *h_A = (real *) malloc(M);
real *h_B = (real *) malloc(M);
for (int n = 0; n < N2; ++n)
{
h_A[n] = n;
}
real *d_A, *d_B;
CHECK(cudaMalloc(&d_A, M));
CHECK(cudaMalloc(&d_B, M));
CHECK(cudaMemcpy(d_A, h_A, M, cudaMemcpyHostToDevice));
printf("\ntranspose with shared memory bank conflict:\n");
timing(d_A, d_B, N, 1);
printf("\ntranspose without shared memory bank conflict:\n");
timing(d_A, d_B, N, 2);
CHECK(cudaMemcpy(h_B, d_B, M, cudaMemcpyDeviceToHost));
if (N <= 10)
{
printf("A =\n");
print_matrix(N, h_A);
printf("\nB =\n");
print_matrix(N, h_B);
}
free(h_A);
free(h_B);
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
return 0;
}
void timing(const real *d_A, real *d_B, const int N, const int task)
{
const int grid_size_x = (N + TILE_DIM - 1) / TILE_DIM;
const int grid_size_y = grid_size_x;
const dim3 block_size(TILE_DIM, TILE_DIM);
const dim3 grid_size(grid_size_x, grid_size_y);
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
switch (task)
{
case 1:
transpose1<<<grid_size, block_size>>>(d_A, d_B, N);
break;
case 2:
transpose2<<<grid_size, block_size>>>(d_A, d_B, N);
break;
default:
printf("Error: wrong task\n");
exit(1);
break;
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
const float t_ave = t_sum / NUM_REPEATS;
const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave);
printf("Time = %g +- %g ms.\n", t_ave, t_err);
}
__global__ void transpose1(const real *A, real *B, const int N)
{
__shared__ real S[TILE_DIM][TILE_DIM];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
__global__ void transpose2(const real *A, real *B, const int N)
{
__shared__ real S[TILE_DIM][TILE_DIM + 1];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
void print_matrix(const int N, const real *A)
{
for (int ny = 0; ny < N; ny++)
{
for (int nx = 0; nx < N; nx++)
{
printf("%g\t", A[ny * N + nx]);
}
printf("\n");
}
}
2.原理介绍
核函数transpose1和transpose2主要区别在于消除Bank Conflicts(更详细的信息可见共享内存实例1:矩阵转置实现及其优化②),这里就transpose1进行下分析。
__global__ void transpose1(const real *A, real *B, const int N)
{
__shared__ real S[TILE_DIM][TILE_DIM];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
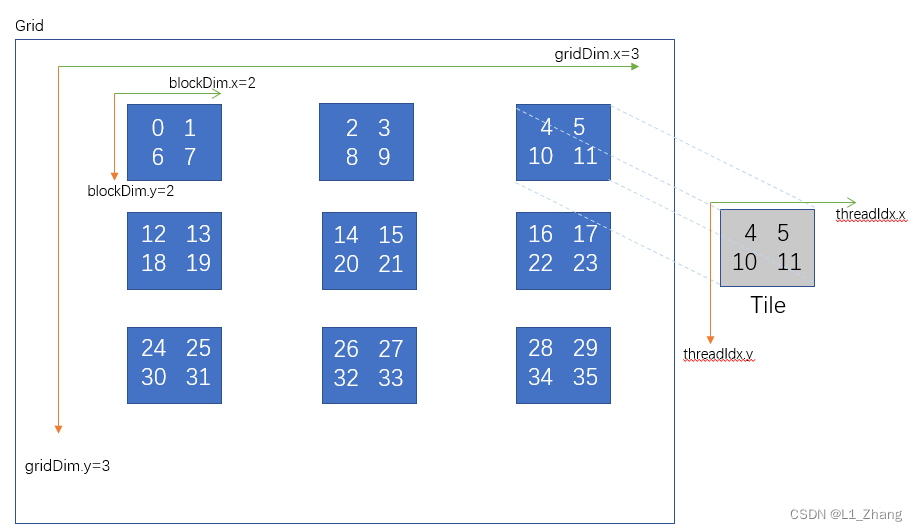
以6*6矩阵的转置为例:
2.1 将各block 线程对应元素放入共享内存tile
前半部分代码主要实现的是将各block 线程对应元素放入对应的共享内存tile。
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
2.2 实现转置
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
.
.
.
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
以右上角这个block中的数据为例,转置过程如下图所示:
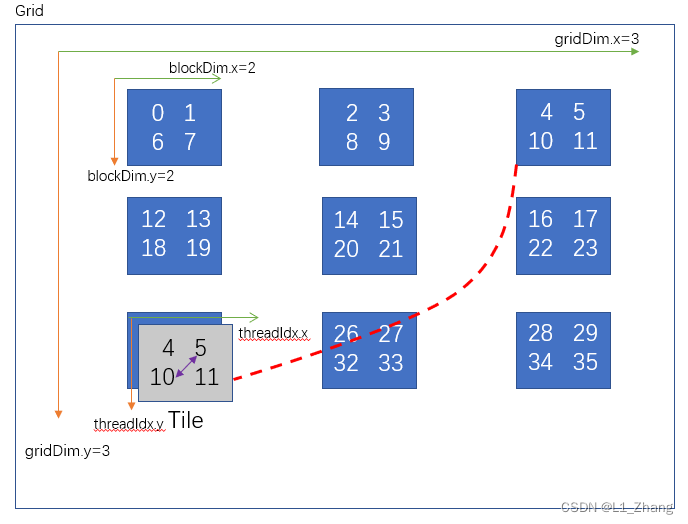
首先,对于block的id,
转置前:
Blockid_x Blockid_y
2 0
转置后:
Blockid_x Blockid_y
0 2
而threadIdx.x,threadIdx.y为什么不需要反过来呢?
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
.
.
.
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
这是因为,单独看每个block,已经通过下面这句代码实现了各个块中对应元素的转置:
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
#正常读取是这样的:S[threadIdx.y][threadIdx.x],
#而S[threadIdx.x][threadIdx.y]正好反过来。
2.3 在此基础上修改
//int nx2 = bx + threadIdx.y;
//int ny2 = by + threadIdx.x;
//if (nx2 < N && ny2 < N)
//{
// B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
//}
if (nx1 < N && ny1 < N)
{
B[nx1 * N + ny1] = S[threadIdx.y][threadIdx.x];
}
原代码使用了block id_x和id_y对调,共享内存中thread id_x和id_y两步实现,思路和实现都比较复杂,可读性也比较差,此代码对block id及block thread id进行对调。
经咨询,此代码没有合并,起不到加速效果。
参考文献
[1] transpose.cu
[2] brucefan1983/CUDA-Programming/