本月的论文包括语言模型、扩散模型、音乐生成、多模态等主题。
1、MusicLM: Generating Music From TextPage
https://arxiv.org/abs/2301.11325
By Andrea Agostinelli, Timeo I. Denk, et al.
扩散模型和自回归离散模型都在生成音乐/音频显示出令人印象深刻的性能。
与最近使用连续扩散模型的其他生成音频工作不同,MusicLM 是一种完全自回归和完全离散的音乐生成模型。它巧妙地利用现有工作(SoundStream [1] 和 w2v-BERT [2])在不同的时间尺度引导表示学习,并在长达几分钟的长时间跨度内实现以前看不见的连贯性的音乐生成。作者将这种技术称为层次表示,因为自回归建模发生在不同的粒度级别,这是实现长期一致性的关键。
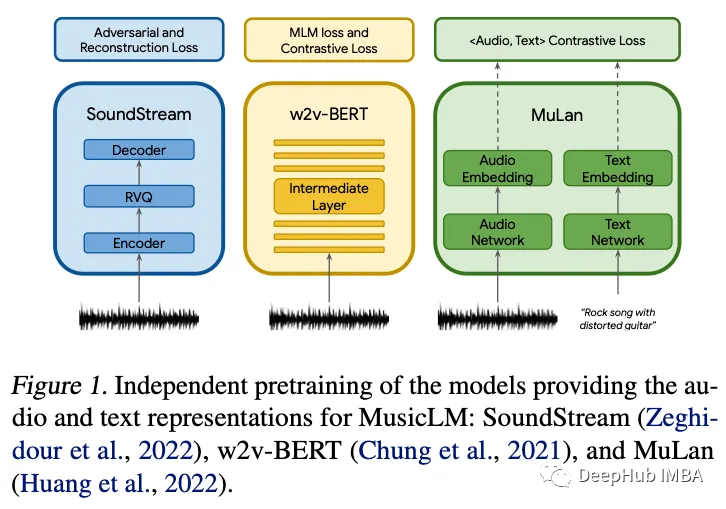
这个项目的关键组成部分之一是数据:对于 MuLan [3],他们采用冻结模型的方式,对于 SoundStream 和 w2v-BERT,他们使用免费音乐存档。为了训练分词器和自回归模型,他们使用自己的专有数据集,其中包含 5M 音频剪辑,总计 280,000 小时 24kHz 的音乐。这意味着在低级和高级表示之间,模型接受了大约 10 亿(高级)和 500 亿(低级)标记的训练。就训练数据而言,MusicLM 可与 GPT-2 相媲美,后者在大约 300 亿个令牌上进行了训练。
在他们的项目页面,有一些音乐样本。如果对音频生成主题感兴趣,请查看 archinet 在过去一个月中不断增加的音频 AI 作品列表(下表)。
https://github.com/archinetai/audio-ai-timeline
2、A Watermark for Large Language Models
https://arxiv.org/abs/2301.10226
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein.
随着 chatGPT 在主流中越来越受欢迎,对作弊的担忧也越来越多。应该在哪里使用这些模型?可以检测模型的输出吗?
这项工作提出了一种为专有语言模型(例如来自 OpenAI 的语言模型)的输出添加水印的方法。此水印的指导原则之一是它永远不会导致误报(即对某人的“诬告”)。该方法的工作原理如下:
- 给定一个标记,确定性伪随机算法将语言模型词汇表分成白/黑名单标记。
- 该模型在每个推理步骤仅从列入白名单的词汇表生成输出。
- 为了避免生成降级,这个过程只应用于高熵令牌。该方法有点复杂,作者从信息论的角度提供了理论保证
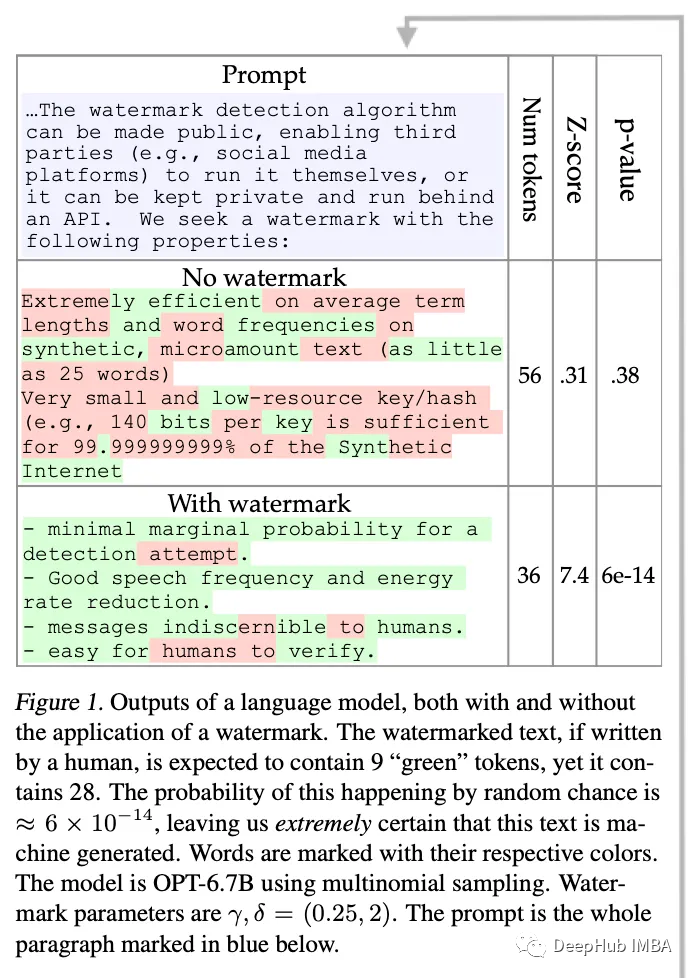
现在,正如作者所展示的那样,这种技术对于一些攻击是稳健的,比如只是在这里和那里交换一些单词,但它不是无懈可击的,并且可以通过一些方式来规避(例如,让第三方语言模型改写第一个语言模型的输出)。不过,有传言称,OpenAI计划发布一款带有类似水印技术的产品,希望减少欺诈性使用该技术。
3、Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP
https://arxiv.org/pdf/2212.14024.pdf
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, Matei Zaharia.
检索增强 LM:用外部显式记忆增强 LM 有可能彻底改变我们查找信息的方式。这项工作代表了超越通过检索增强 LM 的一步。
大多数检索增强的LM以先检索后读取的方式工作:给定提示,对检索模型(RM)进行查询,然后将其用作生成LM的上下文。但有时复杂的信息需求需要LM和RM之间更复杂的交互,这就是本文提出的建模方法。
Demonstrate-Search-Predict (DSP)是一个用于上下文学习的框架,其中LM和冻结RM交互,交换自然语言和分数。这表明在知识密集型多跳问答场景下(即当不能立即找到答案时),性能得到了提高。作者提供了一个python实现,通过3个步骤定义LM和RM交互:演示(从训练样本中自动挖掘少量示例)、搜索(RM和LM交互)和预测(生成最终答案)。

4、The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
https://arxiv.org/abs/2301.13688
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V. Le, Barret Zoph, Jason Wei, Adam Roberts.
你可以自己部署和运行的最好的全面公开、完全开源的语言模型是什么?FLAN-T5。
最初在 FLAN [5] 中提出,指令调整(不要与 InstructGPT 混淆)是在 LM 的训练中以自然语言指令的形式包含标记数据的过程。
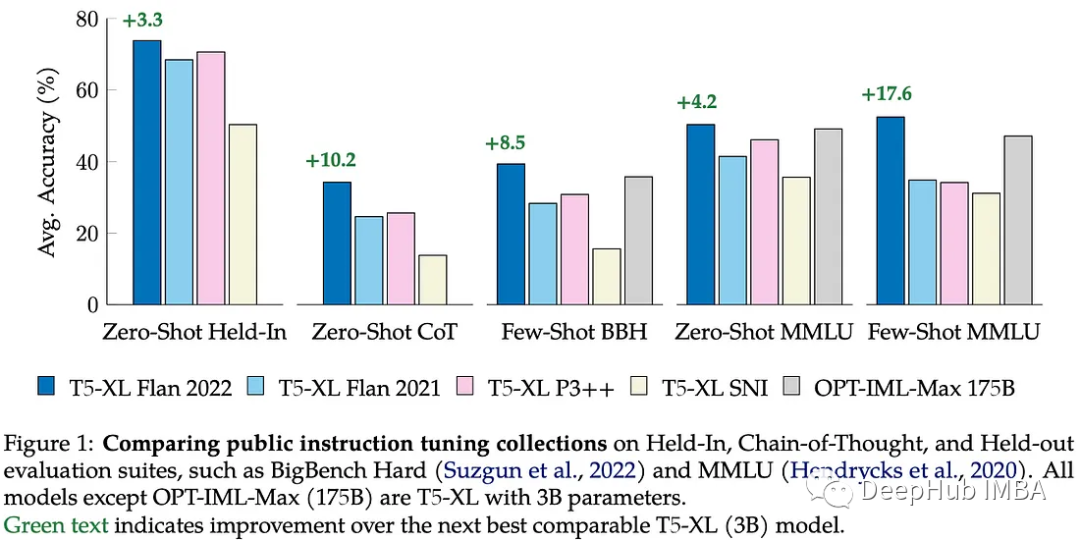
这项研究比较了现有的开源预训练指令调优模型在各种设置下的情况:保持或保持任务(模型在训练期间看到任务了吗?)和零或少样本学习。比较的所有模型都属于T5家族,除了OPT-IML-Max[8]有1750亿个参数外,其余型号都有30亿个参数。
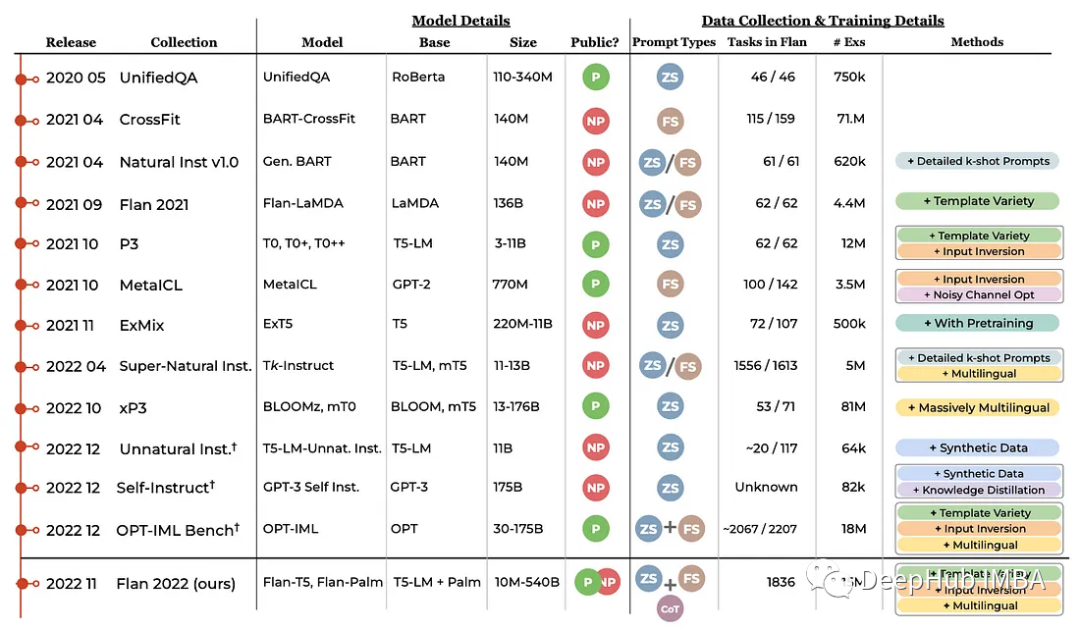
最重要的是:(1)在训练过程中混合零样本和少样本的例子,有助于在所有设置下的性能,(2)指令调优再次证明,使更小的小模型能够达到更大一个数量级的模型的性能。
这些结果证实了一个现有的流行观点,即Flan T5是目前最适用于零样本和少样本学习的中等规模(3-10B)模型。
5、Tracr: Compiled Transformers as a Laboratory for Interpretability
https://arxiv.org/abs/2301.05062
David Lindner, János Kramár, Matthew Rahtz, Thomas McGrath, Vladimir Mikulik.
把Transformers 看作计算机可以让我们对这些模型的计算能力有新的认识。
Restricted Access Sequence Processing Language (RASP[6])是一种特定于领域的语言,用于表达Transformer可以执行的计算。将Transformer视为一个计算平台,其输入是一系列分类变量,操作符可以是:(1)进行选择,(2)进行元素计算,或(3)进行选择-聚合计算。
Tracr是一种将RASP直接编译为Transformer 权重值的方法。例如,下面是一个对序列进行排序的程序。
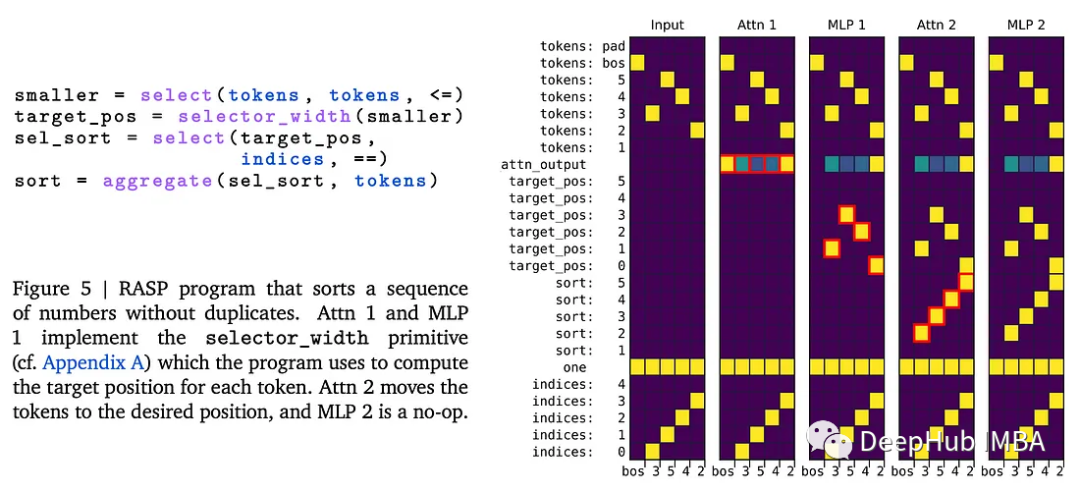
虽然目前这个论文提出的方法在实际应用中非常有限,但它可以作为一个工具,更好地理解Transformers 执行的那种计算。它可以作为在神经网络中实现符号操作的桥梁,或者在检测到实现某些算法的某些权重模式时,用更有效的算法替换神经网络组件。
本文还比较了编译权重与梯度下降学习权重的比较,从经验上证实了这两种方法如何收敛到相同的结果。
6、Extracting Training Data from Diffusion Models
https://arxiv.org/abs/2301.13188
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, Eric Wallace.
在生成式人工智能的迅速崛起中,训练数据的所有权、归因和隐私已经成为一个激烈辩论的领域。这项工作突出了扩散模型在重现训练图像时的缺点和风险,这是令人担忧的,因为训练数据通常没有完全过滤,最终包括私人信息。
他们在论文中所做的工作的要点非常简单,即生成具有稳定扩散的图像,并带有与训练集中发现的提示相匹配的提示,并查看模型生成与训练图像完全相同的图像的频率。
主要要点是:
- 模型越强大,检索到训练图像的可能性就越大。
- 基于 GAN 的图像生成模型也可以从训练数据集中生成图像, 但不太容易受到直接记忆的影响。有趣的是,GANs和dm有很强的记忆相同图像的倾向,这表明这些图像/提示对之间存在一些共性,使它们“令人难忘”

这项工作并没有调查自回归图像生成模型,但考虑到它们也被训练成精确复制训练数据,看看它们与扩散模型相比如何肯定会很有趣。
7、Multimodal Chain-of-Thought Reasoning in Language Models
https://arxiv.org/abs/2302.00923
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola.
Chain-of-thought[9] 在一年前证明可以从现有的语言模型中提取大量推理。现在该技术应用于多模式设置(视觉+语言)。
这项工作调查了问答模型,包括图像生成模型。之前的研究发现,Chain-of-Thought小模型的推理性能,而联合视觉+语言模型会在推理中产生大量幻觉。作者建议通过将基本原理生成和回答分两个阶段解耦来解决这个问题。这可以提高性能,例如超过了 ScienceQA 基准测试中的先前技术水平(这是一种文本到文本的纯语言模型,通过 OpenAI 的 API 的 GPT-3.5)。
8、StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
https://arxiv.org/abs/2301.09515
Axel Sauer, Tero Karras, Samuli Laine, Andreas Geiger, Timo Aila.
GANs在扩散模型的强势下依然可以一战
尽管扩散模型由于其令人印象深刻的多功能性和鲁棒性已经成为图像生成的焦点,GANs仍然具有一些优势。最突出的是,它们的效率要高得多:一次向前传递就足以生成一幅图像,而扩散模型则需要多个步骤来完成。
这项工作提出了最新的GAN迭代:StyleGAN-T,以解决大规模文本到图像合成的需求。包括:强文本对齐,可控输出变化,在不同数据上的训练稳定性等。总的来说,这是一项非常扎实的工程工作,将现代神经网络和优化实践应用于基于gan的图像生成。
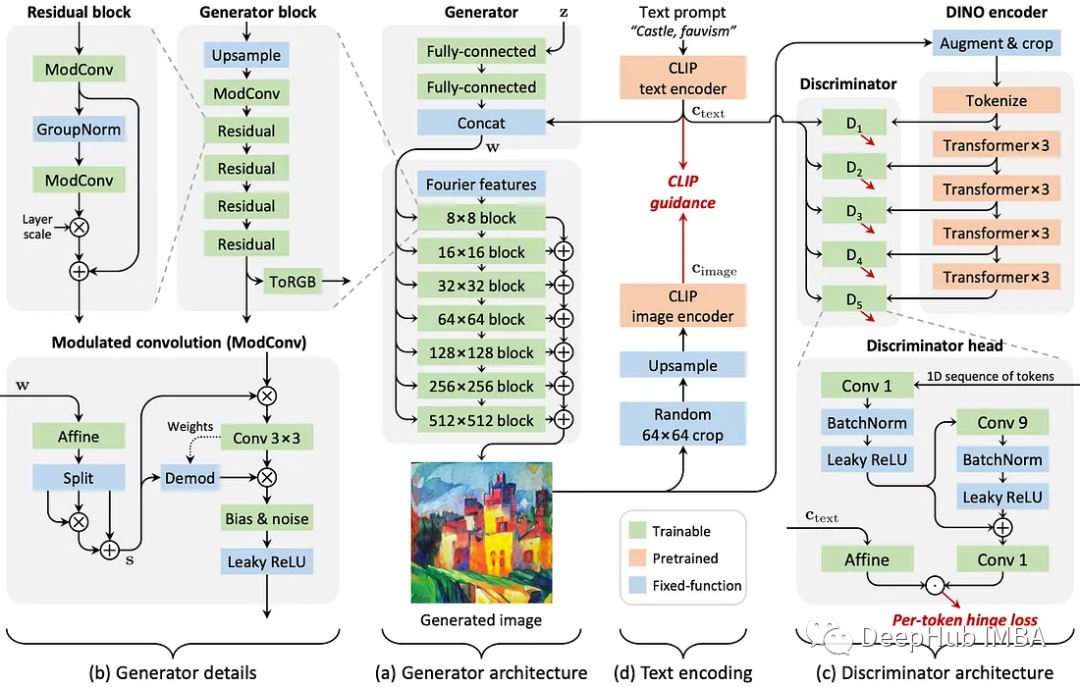
StyleGan-T与现有的著名扩散模型(如DALL·e2)有一些相似之处,例如使用CLIP嵌入的条件生成引导。作者强调,这种GAN模型可以与文本提示更好地对齐-变化(即,希望生成的图像提示,但在多次生成时也具有合理的可变性)。

考虑到效率等限制因素,gan仍然具有竞争力,但我们不期望它们很快就会使扩散模型过时,因为这些模型在不断改进并找到新的用途。
9、Text-To-4D Dynamic Scene Generation (MAV3D)
https://make-a-video3d.github.io/
Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, Yaniv Taigman.
为生成图像增加了一个维度:生成3D视频。
这项工作最令人印象深刻的壮举之一是,与图像不同3D视频和文本数据对并不多。作者依靠现有的预训练文本到视频模型(Make-A-Video[7],也来自Meta)作为NeRF模型的“场景先验”,该模型经过优化以创建场景的3D表示。也就是说在优化过程中,NeRF模型从连续的时空坐标创建场景的一系列视图,然后使用扩散模型对图像的真实感和与文本提示的对齐进行评分,这种技术称为评分蒸馏采样。
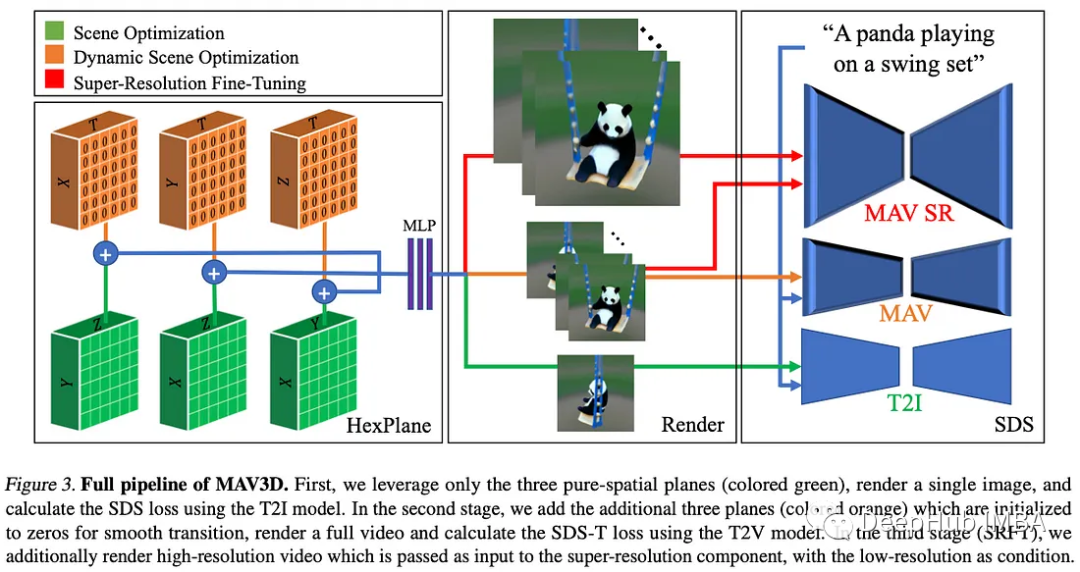
可以被视为DreamFusion[8]的扩展,这是一个文本到3d图像模型,其中添加了时间维度。这种模型生成的视频很短,不包含任何故事情节,因为这仍然是长视频生成的一个挑战。
10、PADL: Language-Directed Physics-Based Character Control
https://arxiv.org/abs/2301.13868
Jordan Juravsky, Yunrong Guo, Sanja Fidler, Xue Bin Peng.
超越文本的 LM 应用程序。
这项工作使用 LM 将自然语言指令映射到角色控制。想一想使用任意复杂的高级语言指令在视频游戏中移动角色。这在可访问性(例如,通过减少显式输入更快地设计动画)、新的视频游戏体验,甚至是具有越来越复杂的指令的新颖的一般人机交互方面具有很大的潜力。
该方法涉及学习将语言指令与角色动作对齐的技能嵌入,训练策略,最后学习聚合策略以结合技能和任务(例如,涉及对象和复杂的交互)。
最后本文的一些其他引用
[1] “SoundStream: An End-to-End Neural Audio Codec” by Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, Marco Tagliasacchi, 2021.
[2] “W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training” by Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, Yonghui Wu, 2021.
[3] “MuLan: A Joint Embedding of Music Audio and Natural Language” by Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, Daniel P. W. Ellis, 2022.
[4] “DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature” by Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D. Manning, Chelsea Finn, 2023.
[5] “Finetuned Language Models Are Zero-Shot Learners” by Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, Quoc V. Le, 2021.
[6] “Thinking Like Transformers” by Gail Weiss, Yoav Goldberg, Eran Yahav, 2021.
[7] “Make-A-Video: Text-to-Video Generation without Text-Video Data” by Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, Yaniv Taigman, 2022.
[8] “OPT: Open Pre-trained Transformer Language Models” by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, Luke Zettlemoyer, 2022.
[9] “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” by Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou, 2022.
https://avoid.overfit.cn/post/5cdbc0916d7c4428b44305a2546cc898
作者:Sergi Castella i Sapé