目录
1.numpy举几个demo
2.pytorch基础
2.1 tensor介绍
3.简单版DataSet & DataLoader
4.模型构建
5.深度学习模型demo:手写文字识别
5.1 构建网络
5.2 前向传播过程
5.3 训练部分
5.4 测试部分
5.5 模型导出
5.6 模型测试
6.pytorch可视化工具tensorboard
7.pytorch实用小工具
1.numpy举几个demo
demo1:numpy索引
if __name__ == '__main__': a = np.array([[1,2,3],[4,5,6],[7,8,9]]) print(a[1:]) #从第二行开始切割 print('\n') print(a[...,1]) #第二列所有行 print('\n') print(a[1,...]) #第二行的所有列 print('\n') print(a[...,1:]) #从第一列开始切割的所有行demo2:reshape
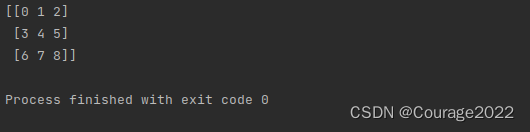
if __name__ == '__main__': a = np.arange(8) print(a) b = a.reshape(4,2) print(b)
demo3:transpose维度互换
if __name__ == '__main__': a = np.arange(12).reshape(3,4) print(a) b = a.transpose() print(b)
demo4:expand_dims
if __name__ == '__main__': a = np.arange(12).reshape(3,4) print(a) b = np.expand_dims(a,axis=0) print(b) print(b.shape)
if __name__ == '__main__': a = np.arange(12).reshape(3,4) print(a) b = np.expand_dims(a,axis=1) print(b) print(b.shape)
if __name__ == '__main__': a = np.arange(12).reshape(3,4) print(a) print('\n') b = np.expand_dims(a,axis=2) print(b) print(b.shape)
demo5:squeeze
if __name__ == '__main__': a = np.arange(9).reshape(1,3,3) y = np.squeeze(a) print(y)
demo6:concatenate
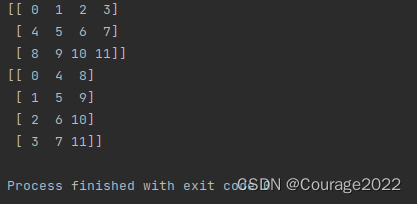
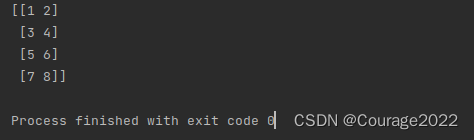
if __name__ == '__main__': a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) print(np.concatenate((a,b),axis=0))
if __name__ == '__main__': a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) print(np.concatenate((a,b),axis=1))





2.pytorch基础
2.1 tensor介绍
demo1:数据转换
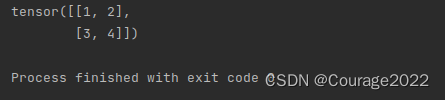
if __name__ == '__main__': data = [[1,2],[3,4]] x_data = torch.tensor(data) print(x_data)
demo2:数据转换
if __name__ == '__main__': data = np.array([[1,2],[3,4]]) x_data = torch.from_numpy(data) print(x_data)
demo3:随机初始化
if __name__ == '__main__': shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape)
demo4:
if __name__ == '__main__': shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape,device="cuda") print(rand_tensor) print(ones_tensor) print(zeros_tensor) print(torch.cuda.is_available()) print(f"shape of the tensor:{rand_tensor.shape}") print(f"datatype of the tensor:{rand_tensor.dtype}") print(f"Device of the tensor:{rand_tensor.device}")
if __name__ == '__main__': shape = (2,3,) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape) zeros_tensor = zeros_tensor.to('cuda') print(rand_tensor) print(ones_tensor) print(zeros_tensor) print(torch.cuda.is_available()) print(f"shape of the tensor:{rand_tensor.shape}") print(f"datatype of the tensor:{rand_tensor.dtype}") print(f"Device of the tensor:{zeros_tensor.device}")





3.简单版DataSet & DataLoader
我们看MVSDataset类,代码在datasets/custom.py
初始化,传入图片路径并定义一个类获取图片的列表
重载样本获取方法:
测试模型:






4.模型构建
举例:
在神经网络中,我们实现forward函数进行正向传播:
有的时候(迁移学习,我们可能会禁用一些层的梯度):
优化:
模型加载和保存:
train和eval模式介绍:












5.深度学习模型demo:手写文字识别
先说一下我们自己搭建网络时候的一些文件夹属性:
__pycache__是python自动生成的。
checkpoints文件夹我们放模型数据用的,即训练权重(预训练权重):
datasets:重写数据加载的py文件(定义自己的数据怎么输入到目标网络中的数据格式转换)
model.py:模型文件,即算法主体。
train.py、eval.py:训练和测试的脚本。
data:放数据集

5.1 构建网络
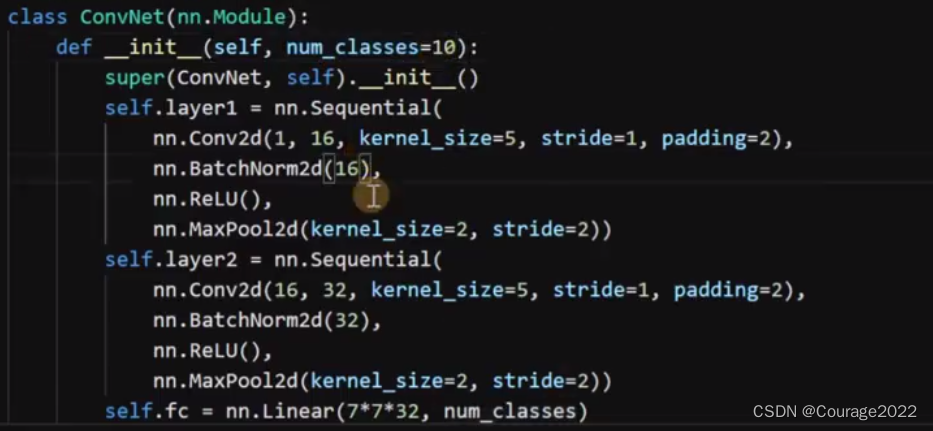
手写文字识别主要构建的是一个卷积神经网络,类的初始化初始化类别为10(0-9十个数字)
定义了两个卷积层,nn.Sequential是一个存储器,我们调用layer1的时候执行layer1里面定义的操作顺序执行。
5.2 前向传播过程
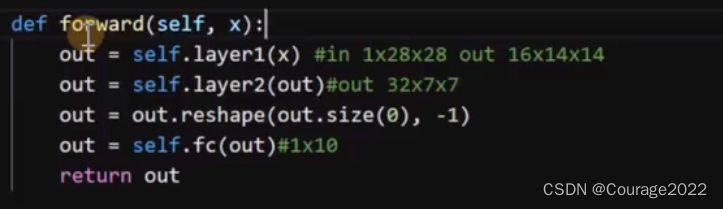
对于一个输入的图片,调用ConvNet中的卷积网络进行处理,输入是一张1*28*28的图片(batchsize=b),因此输入shape为b*1*28*28,经过layer1卷积后,shape变为b*16*14*14。经过layer2卷积后,shape变为b*32*7*7。对其展平,shape变成b*10,得到并返回结果。
5.3 训练部分
判断gpu是否可用并配置参数,大型项目一般有config.py文件存储配置信息。
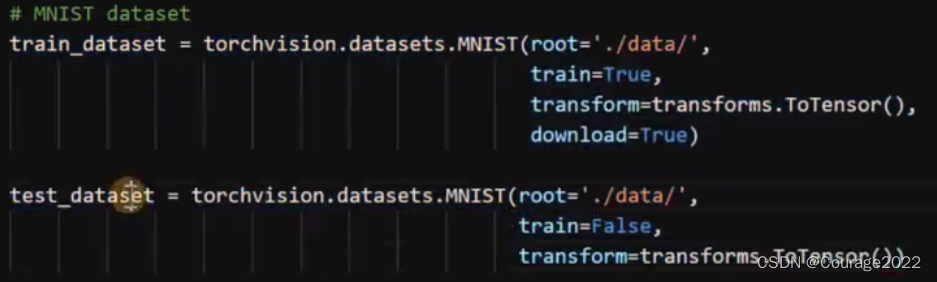
加载数据。
模型初始化:
定义损失和优化器:
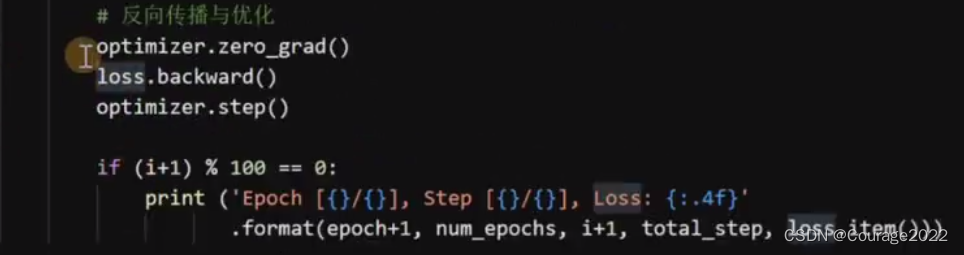
开始训练:




5.4 测试部分
5.5 模型导出
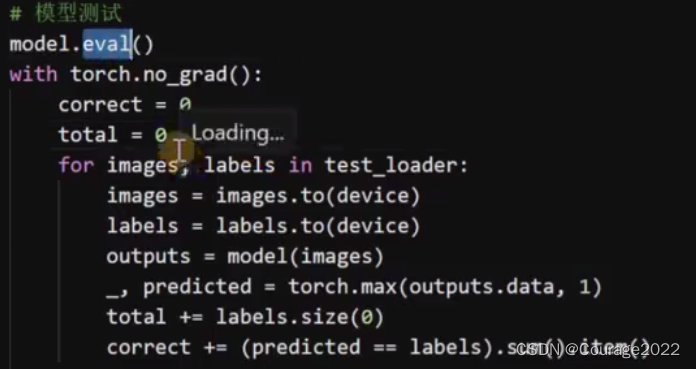
5.6 模型测试
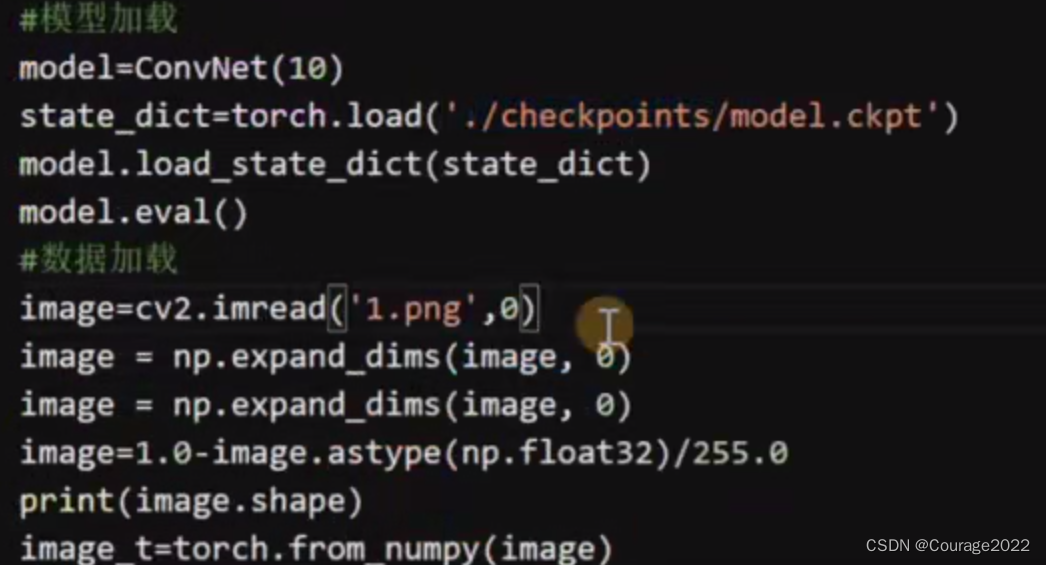

6.pytorch可视化工具tensorboard
如何调用:模块加载
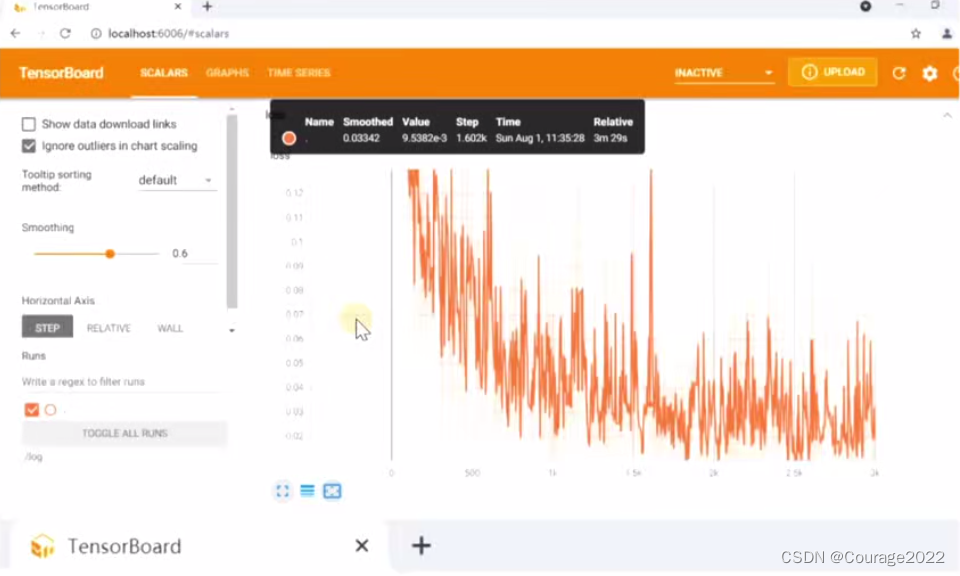
运行train.py后,会在./log文件夹下保存一个类似events.out.tfevents.xxx
如何打开这个文件呢?在终端输入 tensorboard --logdir=./log
在浏览器打开网址:
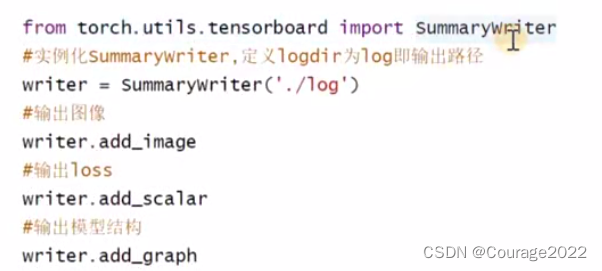
在代码中,需要先初始化tensorboard:
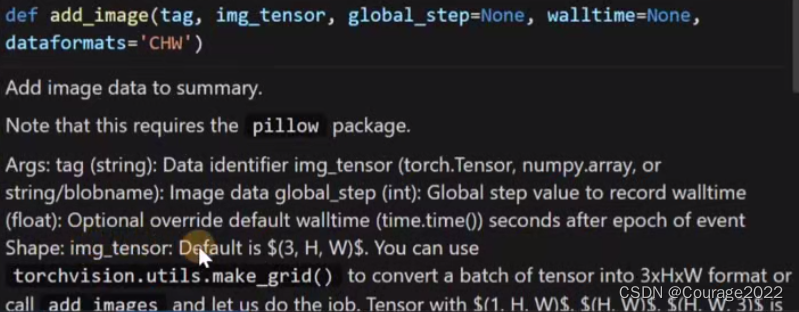
看一下里面的参数:





7.pytorch实用小工具
summary:
输出示例: