基本特性
- 代表不可变字符序列
- final不可被继承
- 实现了Serializable、Comparable等接口
- jdk8及以前使用final char[]存储,jdk9开始改为使用byte[]存储
- 通过字面量方式给一个字符串变量赋值,此时字符串对象在字符串常量池里面
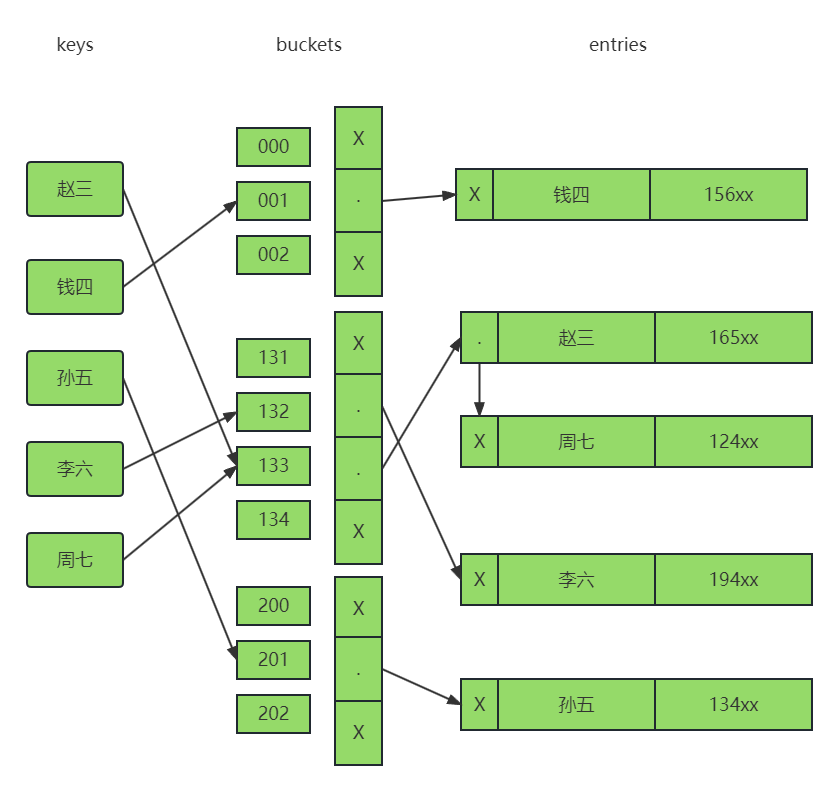
字符串常量池
字符串常量池不会存储内容相同的字符串。
- 字符串常量池是一个固定大小的HashTable,默认长度是1009。
- 如果字符串非常多,就会造成Hash冲突,导致链表过长,而链表过长会影响String.intern的性能。
- 可以使用-XX:StringTableSize设置HashTable的长度。
- 在jdk6中,长度是固定的,所以常量池的字符串过多就会导致性能下降,StringTableSize设置没有要求。
- 在jdk7中,长度默认60013,StringTableSize设置没有要求。
- 在jdk8中,长度默认60013,可以根据实际需求设置,1009是可以设置的最小值。
查看StringTableSize的值
jinfo -flag StringTableSize pid
验证字符串常量池不重复
System.out.println();
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10"); // 假设执行到这里字符串个数是N
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10"); // 执行到这里字符的数量还是N
内存分配
在Java语言中,有8种基本数据类型和String类型,这些类型为了在运行过程中速度更快、更加节省内存,都提供了常量池的概念。
常量池类似一个Java系统级别的缓存,8种基本数据类型的常量池都是系统协调,String常量池比较特别:
- 使用字面量方式声明的String对象会直接存储在常量池中
- 使用new方式创建的字符串对象,可以使用intern()方法放入到常量池中
存储在哪里
jdk6及以前,字符串常量池在永久代。
jdk7开始,将字符串常量池移到了Java堆。在调优时,仅需要调整堆大小。
jdk8开始,字符串常量池还是在堆中。
创建了几个对象
String s=“a”+“b”+“c”;创建了几个对象?
反编译出来的代码
String s = "abc";
原因分析
在编译期间,应用了编译器优化中一种被称为常量折叠(Constant Folding)的技术,会将编译期常量的加减乘除的运算过程在编译过程中折叠。编译器通过语法分析,会将常量表达式计算求值,并用求出的值来替换表达式,而不必等到运行期间再进行运算处理,从而在运行期间节省处理器资源。
编译期常量的特点就是它的值在编译期就可以确定,并且需要完整满足下面的要求,才可能是一个编译期常量:
- 被声明为final
- 基本类型或者字符串类型
- 声明时就已经初始化
- 使用常量表达式进行初始化
上面的前两条比较容易理解,需要注意的是第三和第四条,通过下面的例子进行说明:
final String s1 = "hello " + "Hydra";
final String s2 = UUID.randomUUID().toString() + "Hydra";
编译器能够在编译期就得到s1的值是hello Hydra,不需要等到程序的运行期间,因此s1属于编译期常量。而对s2来说,虽然也被声明为final类型,并且在声明时就已经初始化,但使用的不是常量表达式,因此不属于编译期常量,这一类型的常量被称为运行时常量。再看一下编译后的字节码文件中的常量池区域:

另外值得一提的是,编译期常量与运行时常量的另一个不同就是是否需要对类进行初始化,下面通过两个例子进行对比:
public class IntTest1 {
public static void main(String[] args) {
System.out.println(a1.a);
}
}
class a1{
static {
System.out.println("init class");
}
public static int a=1;
}
// init class
// 1
public static final int a=1;
// 1
加深对final关键字的理解
public static void main(String[] args) {
final String h1 = "hello";
String h2 = "hello";
String s1 = h1 + "Hydra";
String s2 = h2 + "Hydra";
System.out.println((s1 == "helloHydra")); // true
System.out.println((s2 == "helloHydra")); // false
}
加深对final关键字的理解 - 2
public static void main(String[] args) {
String s1 = "my ";
String s2 = "name ";
String s3 = "is ";
String s4 = "Hydra";
String s = s1 + s2 + s3 + s4;
}
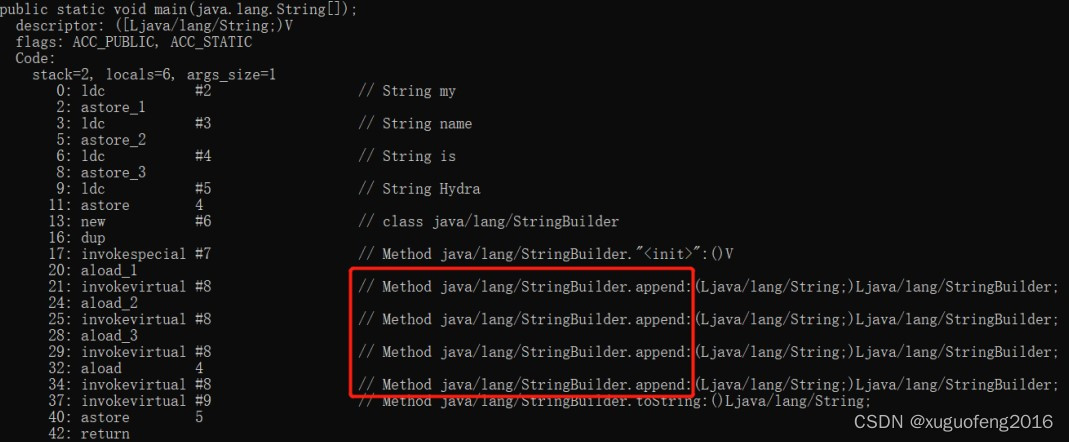
字符串拼接
概述
- 常量与常量的拼接结果在常量池,原理是编译期优化
- 只要其中有一个变量,结果就是在堆中创建对象,使用的是StringBuilder拼接
- 如果拼接的结果调用了intern()方法,则将常量池中还没有的字符串对象放入池中,并返回此对象地址
示例1
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop"; // 编译期优化
String s5 = s1 + "hadoop"; // 出现变量拼接,在堆中创建String对象
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true
System.out.println(s3 == s5); // false
System.out.println(s3 == s6); // false
System.out.println(s3 == s7); // false
System.out.println(s5 == s6); // false
System.out.println(s5 == s7); // false
System.out.println(s6 == s7); // false
// 判断字符串常量池是否存在s6字符串,如果是,则返回常量池的字符串地址
// 如果不存在,则在常量池保存这个字符串,并返回对象地址
String s8 = s6.intern();
System.out.println(s3 == s8); // true
示例2
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); // false
示例3
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); // true
StringBuilder和字符串拼接比较
通过StringBuilder的append方法追加字符串效率高于String的拼接方式。
因为StringBuilder只使用同一个StringBuilder对象。
但是每一次字符串拼接都会创建新的StringBuilder和字符串,效率低,且内存占用多。
如果在创建StringBuilder的时候就指定一个容量,性能会更好:
StringBuilder sb = new StringBuilder(highLevel);
intern方法
概述
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned.
如何使用
如果不是使用双引号声明的String对象,可以使用intern()方法将其放入常量池或从常量池获取并返回常量池地址。
也就是说,如果在任意字符串上调用该方法,那么其返回结果所指向的实例,必须和直接以常量形式出现的字符串实例完全相同。
示例1
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2); // false
String s3 = new String("1") + new String("2");
s3.intern();
String s4 = "12";
System.out.println(s3 == s4); // 6:false;7/8:true
示例2
new String(“ab”)创建几个对象?
查看字节码,是两个:
- 堆里面的字符串对象,使用new关键字创建
- 字符串常量池的ab字符串,字节码指令ldc
示例3
new String(“a”) + new String(“b”)创建几个对象?
6个:
- new StringBuilder()
- new String(“a”)
- 常量池中的a
- new String(“b”)
- 常量池中的b
- StringBuilder的toString()方法会new String(“ab”)创建字符串对象,但是这个ab不会在字符串常量池创建
intern方法使用
在jdk1.6中:
- 如果常量池存在,则不放入,返回已经存在的池里面的对象的地址
- 如果常量池不存在,会把对象复制一份,放入常量池,返回池里面的对象的地址
在jdk1.7/1.8中:
- 如果常量池存在,则不放入,返回已经存在的池里面的对象的地址
- 如果常量池不存在,会把对象引用地址复制一份,放入常量池,返回池里面的引用
示例1
String s3 = new String("1") + new String("1");
String s4 = "11";
String s5 = s3.intern();
System.out.println(s3 == s4); // false
System.out.println(s5 == s4); // true
示例2
String s = new String("a") + new String("b");
String s2 = s.intern();
System.out.println(s2 == "ab"); // 6:true;7/8:true
System.out.println(s == "ab"); // 6:false;7/8:true
String的垃圾回收
打印StringTable统计信息
-XX:+PrintStringTableStatistics
G1的String去重
许多Java应用:
- 堆存活数据集合里面String占了25%
- 堆存活数据集合里面重复String占了13.5%
- String对象的平均长度是45
许多大规模Java应用的瓶颈在于内存,在这些类型的应用里面,Java堆中存活的数据集合差不多25%是String对象,差不多一半的字符串是重复的。
s1.equals(s2)==true这样的情况下,重复的String对象会造成资源浪费。这个将在G1垃圾收集器中实现自动持续对重复的String对象进行去重,这样就能避免资源浪费。
实现
- 垃圾收集器工作时,会访问堆上的存活对象,对每一个对象检查是否是候选的需要去重的String对象
- 如果是,把这个对象的一个引用插入到队列等待去重线程处理
- 去重线程删除这个对象,然后尝试引用其他的String对象
- 使用一个hashtable记录所有的被String对象使用的不重复的char数组,去重时,会检查这个hashtable判断堆上是否已经存在一个相同的char数组
- 如果存在,String对象会被调整引用那个数组,释放原来数组的引用,最终旧数组会被垃圾收集器回收
- 如果查找失败,char数组会插入到hashtable中,这样以后就可以共享这个数组
参数
- UserStringDeduplication - 切换去重开关状态
- PrintStringDeduplicationStatistics - 打印去重统计信息
- StringDeduplicationAgeThreshold - 年龄上限