B-TREE
B-TREE数据结构

B-TREE特性
- 根节点的子结点个数2 <= X <= m,m是树的阶
- 假设m = 3,则根节点可有2-3个孩子
- 中间节点的子节点个数m/2 <= y <= m
- 假设m = 3,中间节点至少有2个孩子,最多3个孩子
- 每个中间节点包含n个关键字,n = 子节点个数-1,且按升序排序
- 如果中间节点有3个子节点,则里面会有2个关键字,且按升序排序
- Pi(i=1,…n+1)为指向子树根节点的指针。其中P[1]指向关键字小于Key[1]的子树,P[i]指向关键字属于(Key[i-1],Key[i])的子树,P[n+1]指向关键字大于Key[n]的子树
- P1、P2、P3为指向子树根节点的指针。P1指向关键字小于Key1的树;P2指向Key1-Key2之间的子树;P3指向大于Key2的树
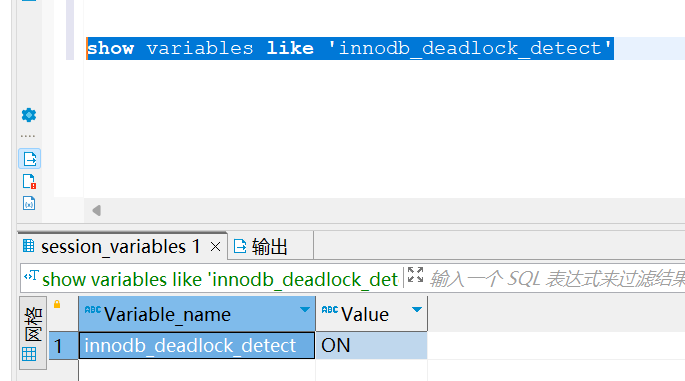
B-TREE的一次等值查找
比如我们要查找上述B-tree中的索引值为26的数据。那么首先在跟根节点中的关键字依次比较,发现15<26<33,则需要在关键字15的右边P2指针指向的磁盘3中查找。26跟磁盘3中的关键字依次比较,发现24<26<28,然后我们需要去关键字24右边P2指针指向的磁盘5中查找;最后我们在磁盘5中找到索引值为26的数据。
B+TREE
B+TREE数据结构

B+TREE特性与B-TREE的差异
- B+TREE有n个子节点的节点中含有n个关键字
- B-TREE是n个子节点的节点有n-1个关键字
- B+TREE中,所有的叶子节点中包含了全部关键字的信息,且叶子节点按照关键字的大小自小而大顺序链表,构成一个有序链表
- B-TREE的所有叶子节点不包括全部关键字
- B+TREE中,非叶子节点仅用于索引,不保存数据记录,记录存放在叶子节点中
- B-TREE中,非叶子节点既保存索引,也保存数据记录
B+TREE的一次等值查找
假设我们要查找索引为60的数据,首先在根节点进行查找,发现6<26<60<66,则我们需要在索引26的P2指针指向的磁盘3中查找;在磁盘3中查找发现26<56<60,我们就需要去索引60的P3指着指向的地址中查找;发现索引60的P3指针指向的是叶子的节点,则索引为60的数据就被我们查找到了。
B-TREE和B+TREE的范围查找
如果我们要查找的是一个范围比如索引n,11<n<21。如果是B-TREE因为叶子节点的存储时单独的那么我们需要依次查找,因为21的索引跨了一个范围,索引我们还需要回头从根节点重新查询一次。而B+TREE索引则不需要,直接拿11进行查询,查询到第一个大于它的数据,由于B+TREE的叶子节点有有序链表结构只需要在链表结构里向后依次查找直到大于21。
InnoDB存储方式
- B+TREE
- 主键索引:叶子节点存储主键及数据
- 非主键索引(二级索引、辅助索引):叶子节点存储索引以及主键
MyISAM存储方式
- B+TREE
- 主键/非主键索引的叶子节点都是存储指向数据块的指针
InnoDB vs MyISAM
- InnoDB:聚簇索引
- MyISAM:非聚簇索引
相关内容查看之前索引类型篇。
Hash索引
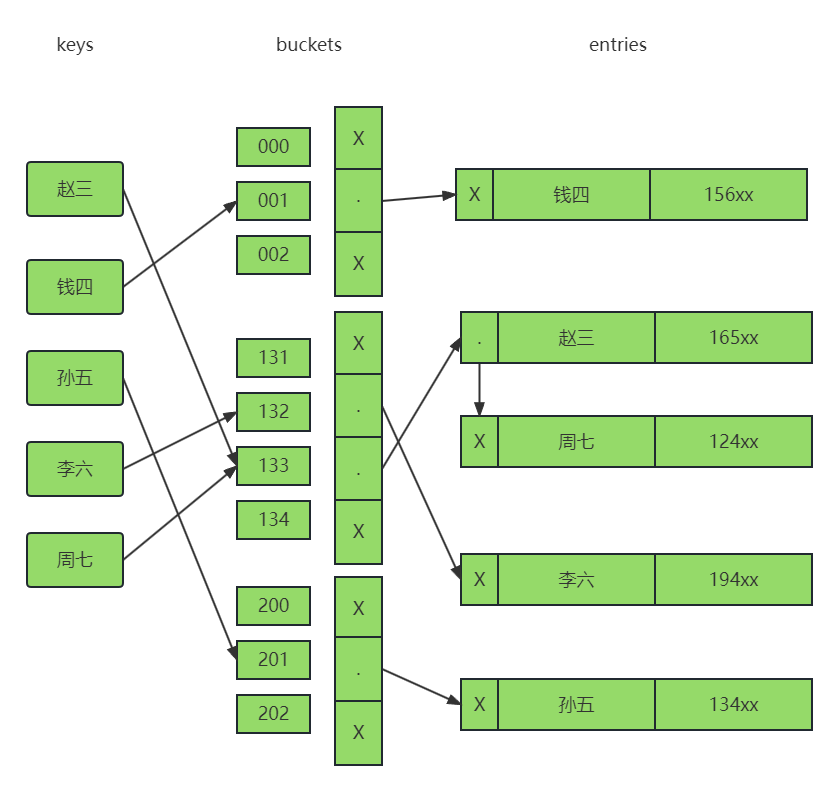
Hash索引,在存放时会用keys中的key值进行hash计算,将数据entries放入hash值与物理位置组成hash表buckets的对应位置,如果产生了hash冲突,则会在该位置创建链表进行存放。在查询的时候会将条件的值进行hash计算,将得到的值与buckets中进行匹配,从而找到我们想要查找的数据。
Hash索引的支持情况
- Memory引擎支持显式的Hash索引
- InnoDB引擎支持“自适应Hash索引”
空间索引(R-TREE索引)
- 存储GIS数据,基于R-TREE
- MySQL5.7开始InnoDB支持空间索引
目前使用不多。
全文索引
- 适应全文搜索的需求
- MySQL5.7之前,全文索引不支持中文,经常搭配Sphinx
- MySQL5.7起,内置ngram,支持中文
一般情况下应对全文搜索的需求,采用搜索引擎解决。