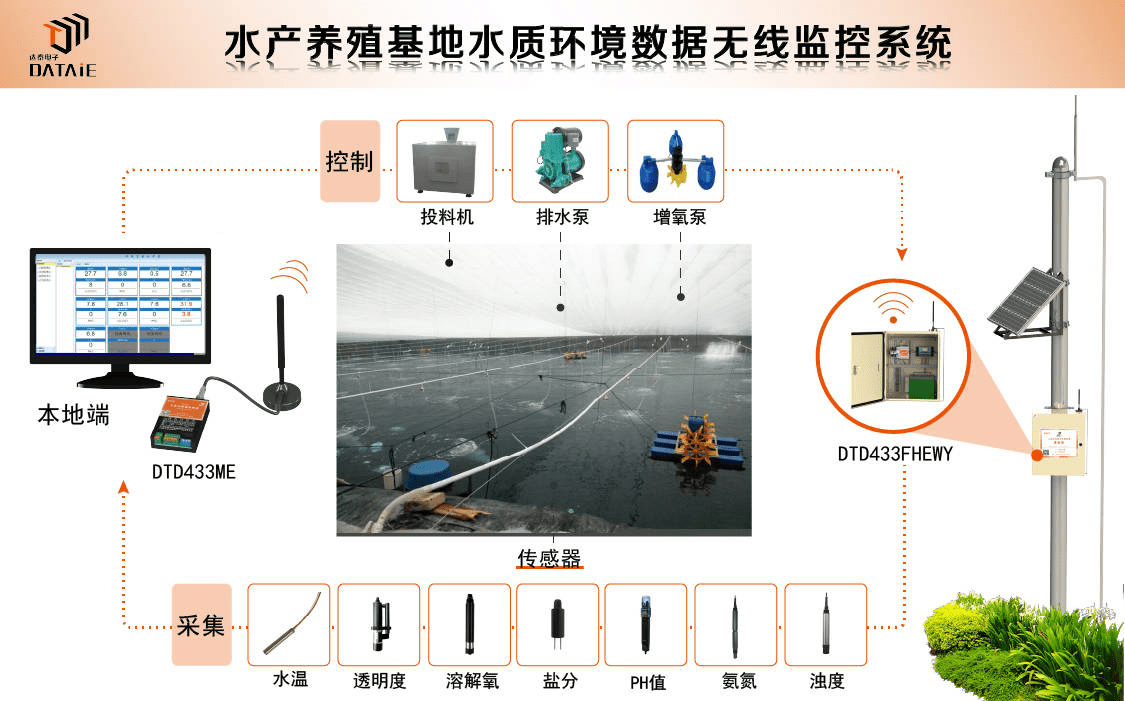
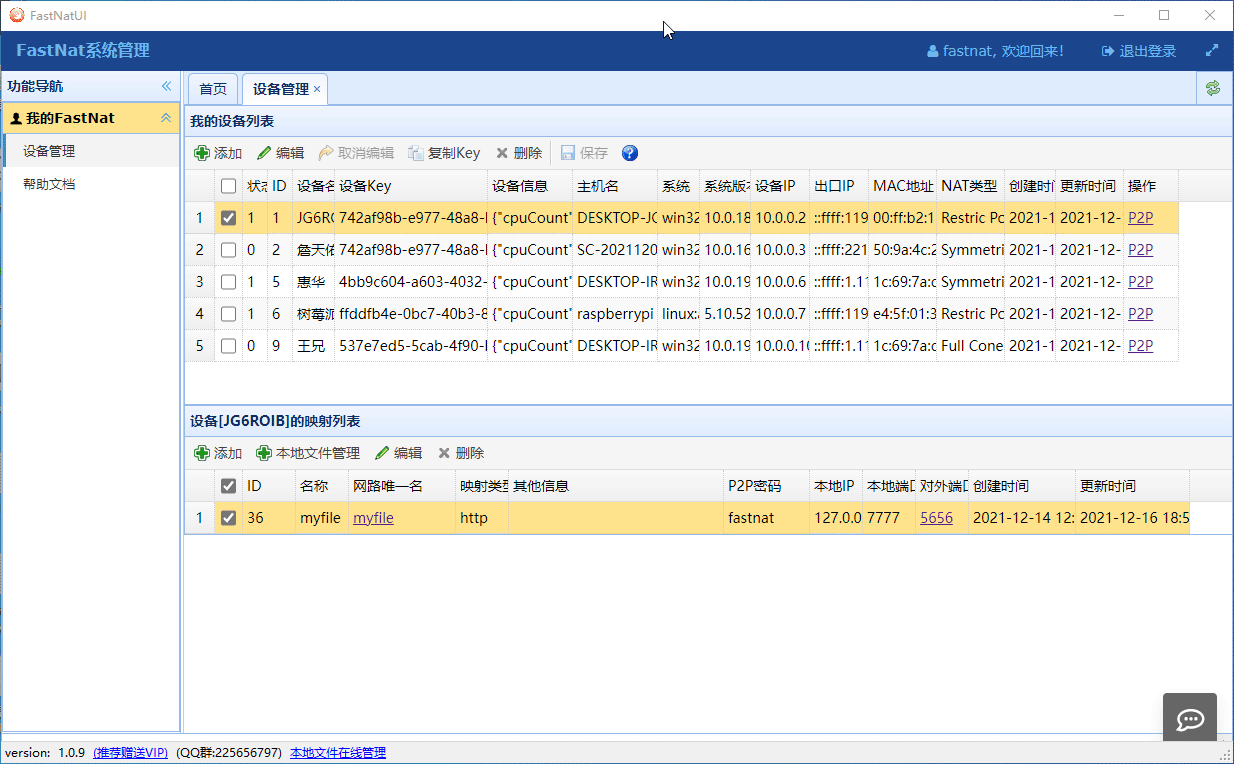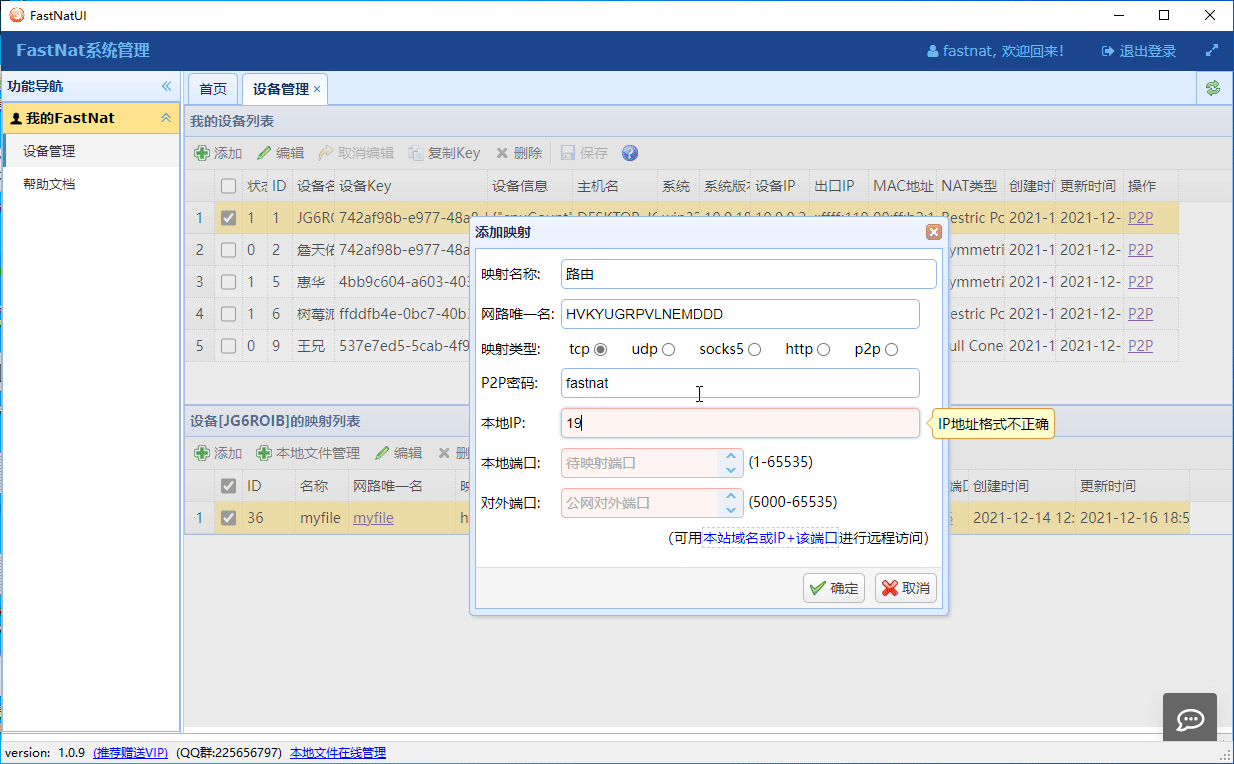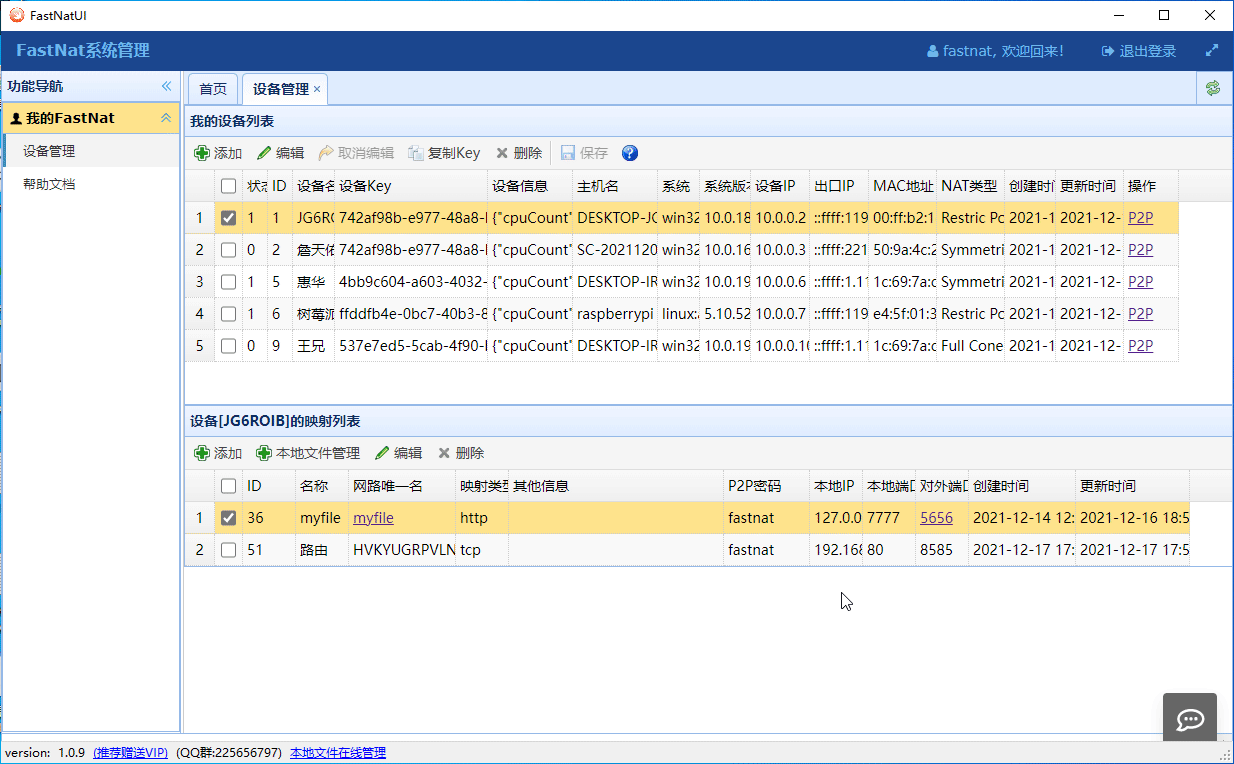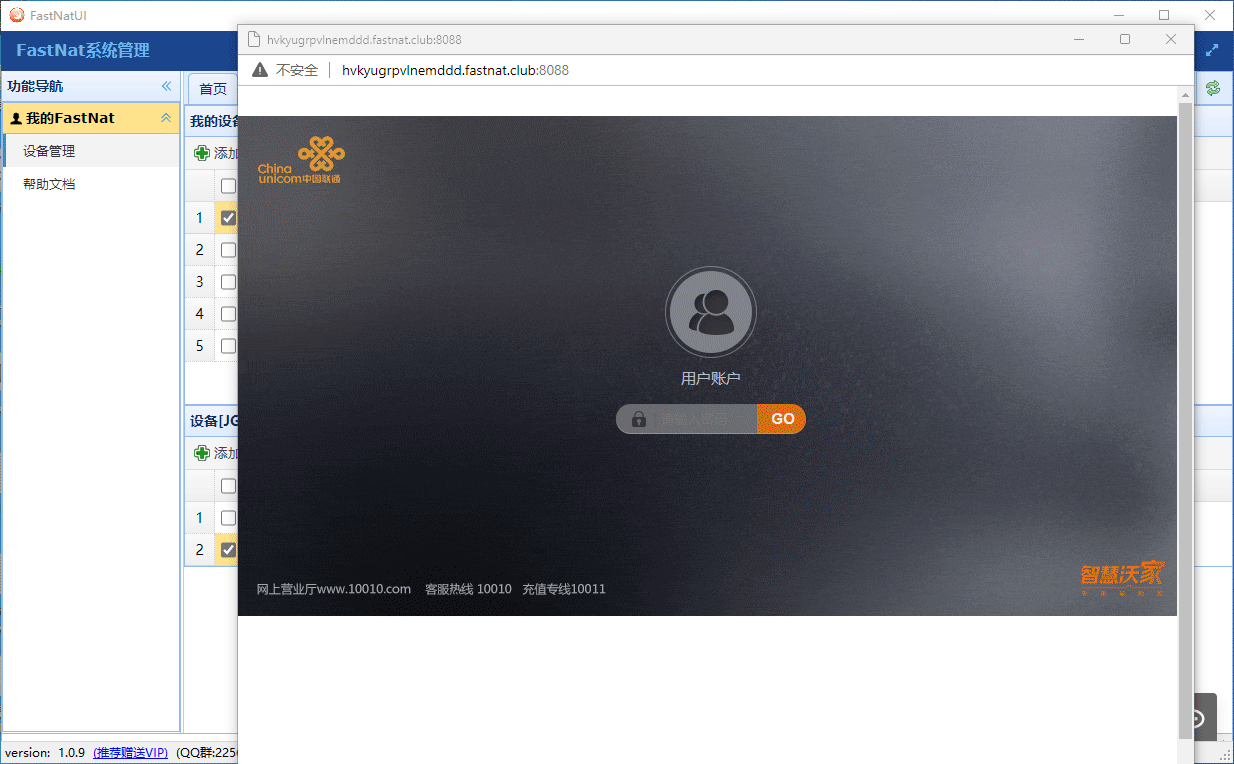
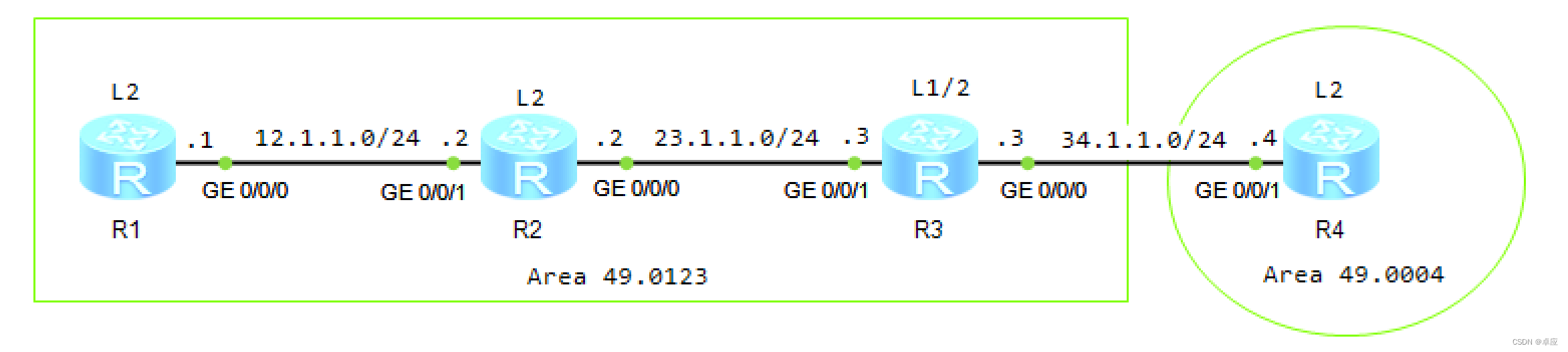
一. 行锁介绍
行锁由各个存储引擎分别实现,MyISAM存储引擎是不支持行锁的,这也是MySQL使用InnoDB作为默认存储引擎的一个重要原因,锁更细的InnoDB能支持更多的并发业务。但需要注意的是,行锁在InnoDB的实现是给索引加的锁,而不是记录。因此 使用update语句时,where条件后的字段需要建立索引,否则将使用的是表锁,因为没有索引让InnoDB去加上这个行锁,只有给整张表加上锁
二. 两阶段锁协议
行锁在需要的时候加上,但不是会立即释放,如果处在一个事务中,只有当事务提交后行锁才会释放,这就是两阶段锁协议
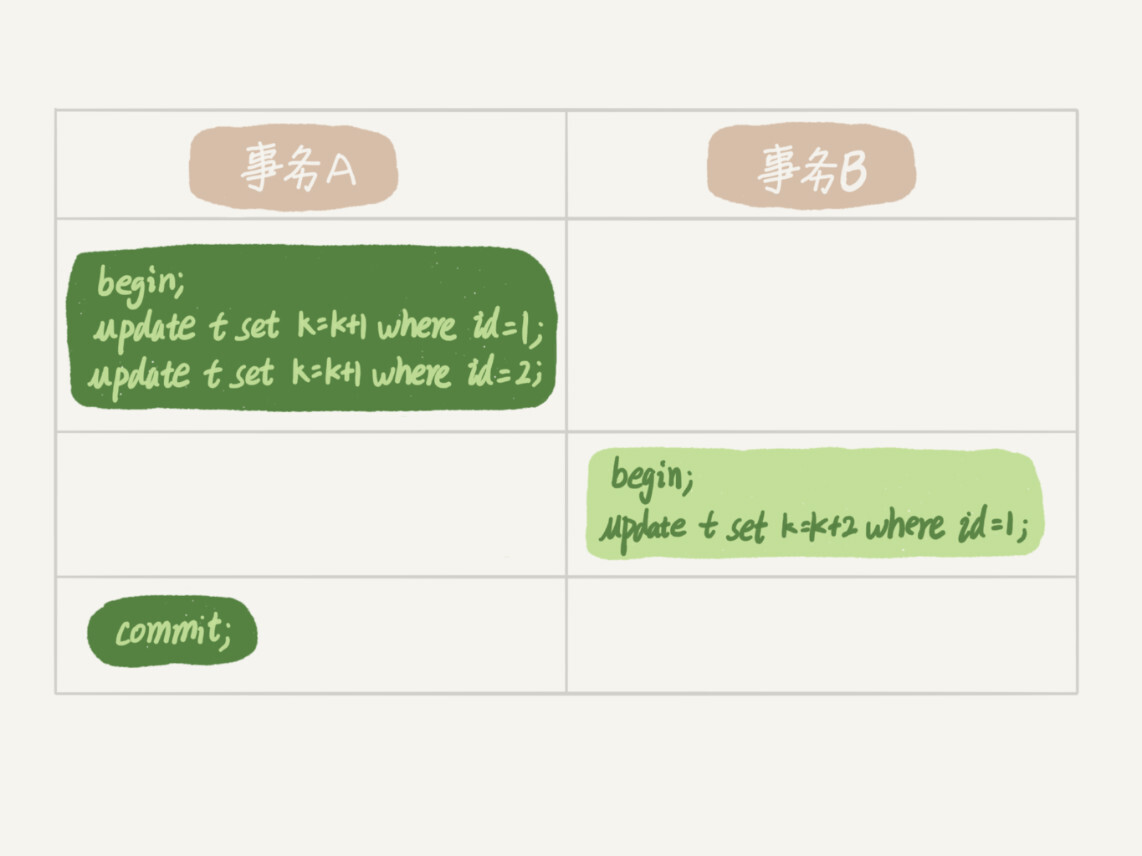
如上事务B在执行的时候会被阻塞,因为事务A在同一时刻还未提交事务,行锁依然存在。只有当事务A提价后,事务B才能继续执行。
基于以上结论,如果在一个事务中,对于使用到行锁的SQL语句,我们应该尽量放到事务最后执行,减少对其他也需要用到同一行锁的事务的影响
三. 死锁检测与锁超时机制
由于行锁是具有互斥性的,那么 当两个事务互相持有对方需要的锁资源且一直不释放自身持有的锁资源时,将造成死锁,如下图所示,此时将造成死锁。
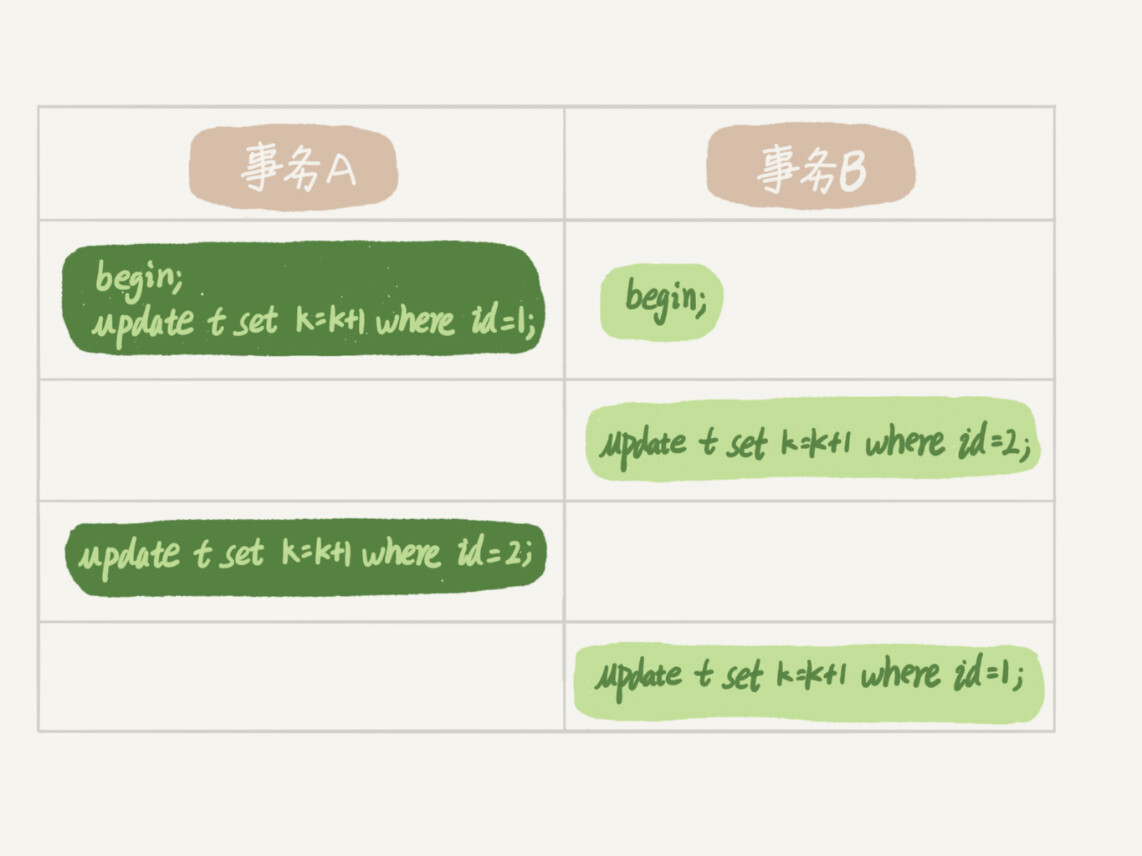
当出现死锁的时候,MySQL有两种机制去处理
锁超时机制
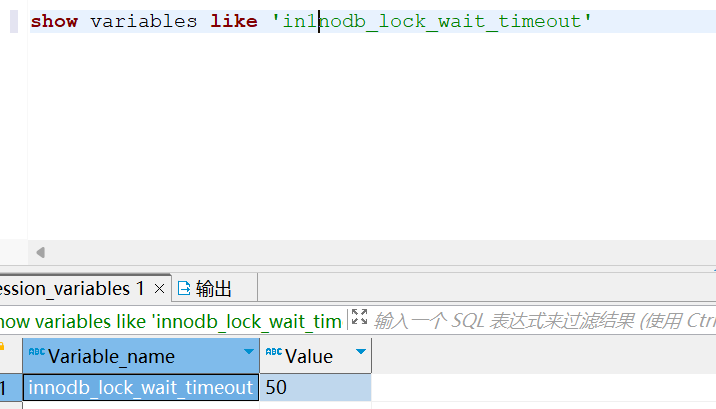
InnoDB有默认的锁超时时间,一般为50秒,可以通过执行以下SQL进行查询,当出现死锁以后,第一个被锁住的线程要过 50s 才会超时退出,然后其他线程才有可能继续执行。对于在线服务来说,这个等待时间往往是无法接受的。但是,我们又不可能直接把这个时间设置成一个很小的值,比如 1s。这样当出现死锁的时候,确实很快就可以解开,但如果不是死锁,而是简单的锁等待呢?所以,超时时间设置太短的话,会出现很多误伤。
show variables like 'in1nodb_lock_wait_timeout'
死锁检测
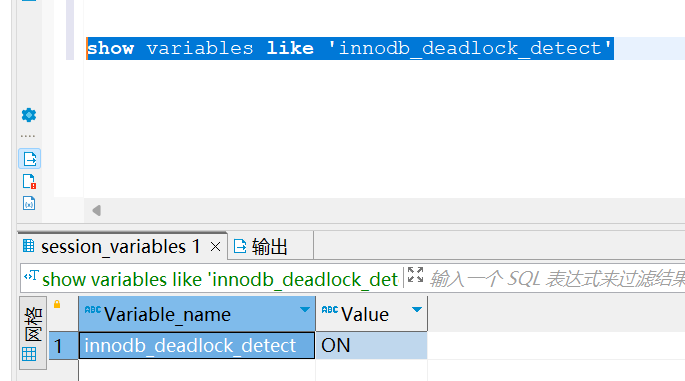
参数 innodb_deadlock_detect 的值为 on时,则表示当前启用了死锁检测。当开启时,InnoDB发现死锁后,会主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。但死锁检测需要消耗大量的CPU资源去主动检测。
每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n) 的操作。假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的 CPU 资源。因此,你就会看到 CPU 利用率很高,但是每秒却执行不了几个事务。
show variables like 'innodb_deadlock_detect'
四.热点数据更新导致的性能问题如何解决
产生原因
由于死锁检测要耗费大量的 CPU 资源,导致性能低下
尝试关闭死锁检测
如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。但是这种操作本身带有一定的风险,因为业务设计的时候一般不会把死锁当做一个严重错误,毕竟出现死锁了,就回滚,然后通过业务重试一般就没问题了,这是业务无损的。而关掉死锁检测意味着可能会出现大量的超时,这是业务有损的。
控制并发数量,不关闭死锁检测
如果并发能够控制住,比如同一行同时最多只有 10 个线程在更新,那么死锁检测的成本很低,就不会出现这个问题。例如我们可以将对一行的修改改成对多行的修改,比如一行记录记录着总金额,我们可以将一行记录拆分成多行,总金额等于多行记录之和,从而降低了锁冲突的概率。但这种修改需要对代码也做出对应的改变。类似于JAVA中的LongAdder类,将对一个值的CAS改成对数组中每个组员的CAS,提高并发效率
另外,最近重温操作系统时发现了一个免费精品好课,闪客的《Linux0.11源码趣读》,这个课给我感觉像在用看小说的心态学操作系统源码,写的确实挺牛的,通俗易懂,直指本源,我自己也跟着收获了很多。这个课在极客时间上是免费的,口碑很不错,看评论下很多人在催更和重温,强烈推荐!戳此链接领取:
https://time.geekbang.org/opencourse/intro/100310101?utm_source=linux_dk&utm_term=linux_dk