背景
本次介绍一下python的pandas包操作Excel(或者CSV等),应用情景是计算不同站点小麦多年生育期内的气象因子的特征(积温、降雨、辐射等)
主要涉及以下知识点:
- 儒略日转换
- 数据框值获取与字符串加法
- 基于query函数的特定日期范围数据筛选
- 数据框在循环中的追加
- 数据框合并
数据样例
首先是气象站点数据,里面主要使用生育期信息,生育期是以儒略日(即这一年的第几天)形式,且假定每年不变

然后利用气象站点的生育期对每年小麦生育期内的气象数据进行汇总,而难点就是得到小麦生育期内的时间序列和筛选此时间序列内的数据

这里面的数据主要是温度降雨以及辐射等信息
计算指标
计算的指标如下:
温度指标:
0以上积温:生育期大于0摄氏度温度累加
最冷月平均最低气温:月平均最低气温
最冷月平均气温:月平均气温
极端最低气温:生育期最低气温
平均气温:生育期平均气温
降水指标:
平均湿润度:生育期平均湿润度 单日湿润度:k=P/ET0 降水/蒸散
总降水量:生育期总降水量
光照指标:
总日照时数:生育期总日照时数
太阳总辐射(RS):生育期总太阳辐射
时间序列为1990-2020每时间作为一个节点进行统计分析
计算过程
这里操作Excel主要使用pandas这个库,首先转换儒略日为日期,这里主要涉及根据这一年的天数推算日期
from datetime import datetime
def jd_to_time(time):
"""
time示例2020213
"""
year = int(time[:4])
day = int(time[4:])
if day > 365:
day = day - 365
year += 1
time = str(year) + str(day)
dt = datetime.strptime(time, '%Y%j').date()
fmt = '%Y/%m/%d'
return dt.strftime(fmt)
读取生育期,这里要注意的是CSV文件出现中文时编码格式多为国标的gb2312编码格式,所以读取的时候要标注。转换生育期为日期,主要涉及字符串的加减、依据变量信息的数据筛选
pheno = pd.read_csv(r'E:\科研材料\试验数据\指标计算张佳笑\气象站点对应生育期.csv', encoding = 'gb2312')
for site in pheno.station_name:
for i in range(1990, 2020):
star_date = jd_to_time(str(i) + str(*pheno.query("station_name == @site")['播种日期'].values))
end_date = jd_to_time(str(i+1) + str(*pheno.query("station_name == @site")['收获日期'].values))
然后获取小麦生育期内的数据,涉及日期的转换、query多条件筛选、日期的筛选
data = pd.read_csv(r'E:\科研材料\试验数据\指标计算张佳笑\ET0过程数据含Rs.csv', encoding = 'gb2312')
data['date'] = pd.to_datetime(data['date']) # 日期转为日期格式
for site in pheno.station_name:
wheat_data = data.query("StationName == @site & date > datetime.strptime(@star_date, '%Y/%m/%d') \
& date < datetime.strptime(@end_date, '%Y/%m/%d')")
这关键的两步完成之后就可以对小麦生育期之内的数据进行计算,先按照地点循环,循环内再循环年,之后按照每十年进行统计与数据合并,整体代码如下:
# 每十年进行统计
# 生育期内指标计算
import pandas as pd
from datetime import datetime
def jd_to_time(time):
year = int(time[:4])
day = int(time[4:])
if day > 365:
day = day - 365
year += 1
time = str(year) + str(day)
dt = datetime.strptime(time, '%Y%j').date()
fmt = '%Y/%m/%d'
return dt.strftime(fmt)
data = pd.read_csv(r'E:\科研材料\试验数据\指标计算\气象数据.csv', encoding = 'gb2312')
data['date'] = pd.to_datetime(data['date'])
pheno = pd.read_csv(r'E:\科研材料\试验数据\指标计算\气象站点对应生育期.csv', encoding = 'gb2312')
final = [] # 储存最终结果
for site in pheno.station_name:
result = {} # 储存指标计算结果
df = [] # 储存所有年份结果
for i in range(1990, 2020):
star_date = jd_to_time(str(i) + str(*pheno.query("station_name == @site")['播种日期'].values))
end_date = jd_to_time(str(i+1) + str(*pheno.query("station_name == @site")['收获日期'].values))
wheat_data = data.query("StationName == @site & date > datetime.strptime(@star_date, '%Y/%m/%d') \
& date < datetime.strptime(@end_date, '%Y/%m/%d')")
result['年份'] = i+1
result['大于0积温'] = wheat_data.query("meantem > 0")['meantem'].sum()
result['极端最低气温'] = wheat_data['mintem'].min()
result['最冷月平均气温'] = wheat_data.groupby(by = ['month']).mean()['meantem'].min()
result['最冷月平均最低气温'] = wheat_data.groupby(by = ['month']).mean()['mintem'].min()
result['生育期平均气温'] = wheat_data['meantem'].mean()
result['平均湿润度'] = wheat_data['k'].mean()
result['总降水量'] = wheat_data['rain'].sum()
result['总日照'] = wheat_data['sunhours'].sum()
result['太阳总辐射'] = wheat_data['Rs'].sum()
df.append(result.copy())
site_year = pd.DataFrame(df) # 位点所有年份结果
site_year.dropna(inplace=True) # 去除空值
# 按照每时间进行分析
stage1 = site_year.query("年份 > 1990 & 年份 < 2001").mean()
stage1['年份'] = 1
stage2 = site_year.query("年份 > 2000 & 年份 < 2011").mean()
stage2['年份'] = 2
stage3 = site_year.query("年份 > 2010").mean()
stage3['年份'] = 3
stage_merge = pd.concat([stage1, stage2, stage3], axis=1)
stage_merge.columns =[site, site, site] # 使列名变为站点名
final.append(stage_merge) # 融合所有数据
pd.concat(final, axis=1).to_excel(r'E:\科研材料\试验数据\指标计算\生育期内指标总.xlsx')
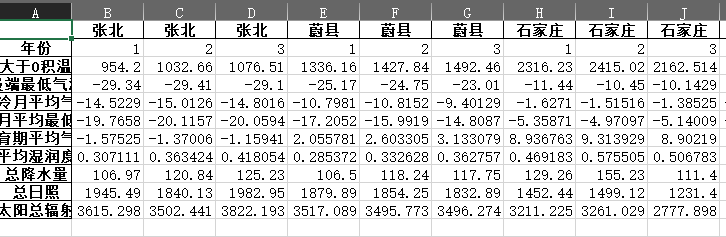
结果