初识PO模式
PO(PageObject)是一种设计模式。简单来说就是把一些繁琐的定位方法、元素操作方式等封装到类中,通过类与类之间的调用完成特定操作。
PO被认为是自动化测试项目开发实践的最佳设计模式之一。
在学习PO模式前,可以先复习一下面向对象的编程思想。我觉得两者很像。
优点
PO模式把页面元素定位和业务操作流程分开,界面元素的变化则不需要修改业务逻辑代码
PO能提高代码的可读性,高复用性,可维护性
设计准则
1.使用公共方法来代表页面提供的服务
2.不要暴露页面的内部细节(比如元素、元素的定位方法等),隔离测试用例和业务和页面对象
3.PO本身通常不应进行断言或判断。判断和断言是测试的一部分,而不是在PO中。
4.PO不一定需要代表整个界面,而是在测试中‘用到什么写什么’
5.相同的操作,但是数据不同,带来的不同结果可以封装成不同的方法。
6.方法可以返回其他的页面对象,进行页面的关联。
以上是比较官方的PO设计准则,我们需要根据具体业务的实际情况决定是完全遵循还是部分遵循。
selenium中的分层模型
表现层:页面中可见的元素,都属于表现层。(元素定位器的编写)
操作层:对页面可见元素的操作。(点击、输入文本等)
业务层:上面2层的组合,联合到一起形成某个业务动作。
测试用例:组合了一个或多个页面的方法,操作对应的元素,完成的测试。
PO模式实战
接下来就用PO模式完成一个简单的‘百度登录模块’的测试
思路:
1.创建一个elements.py存放登录界面所有的元素定位方式(用到哪个写哪个)
2.创建一个common_driver.py存放一些共用的浏览器相关方法
3.创建一个common_basepage.py存放共用的元素操作方法
4.创建一个test_cases.py文件存放测试用例
以下为部分代码:
找到我们测试登录模块需要操作到的元素,将其定位方法写到elements.py中
#elements.py
class Elements():
'''存放用到的所有元素定位器'''
#登录前的界面元素
LOGIN_BUTTON_OUT = ('id','s-top-loginbtn')#百度首页的‘登录’按钮
LOGIN_WIN = ('id','TANGRAM__PSP_4__content')#登录窗口
USERNAME_INPUT = ('id','TANGRAM__PSP_11__userName')#输入账号栏
PASSWORD_INPUT = ('id','TANGRAM__PSP_11__password')#输入密码栏
LOGIN_BUTTON_IN = ('id','TANGRAM__PSP_11__submit')#登录界面的‘登录’按钮
#登录后的界面元素
USER_INFO = ('css selector','#s-top-username > span.user-name.c-font-normal.c-color-t')#右上角的用户信息
QUIT_BOTTON = ('css selector','#s-user-name-menu>.quit')#退出登录按钮
浏览器相关操作放到common_driver.py中
# common_driver.py
from selenium import webdriver
from environment_config import Env
class Single(object):
'''
设计单例模式
'''
_instance = None #实例
def __new__(cls, *args, **kwargs):
if cls._instance is None: #此处是可以用__instance
cls._instance = super().__new__(cls)
return cls._instance
class Open_Driver(Single):
'''
打开一个浏览器
'''
driver = None
def get_driver(self,browser_type=Env.BROWSER_TYPE,headless_flag=Env.HEADLESS_FLAG):
'''
根据参数打开想要的浏览器
:param browser_type: 浏览器类型,读取Env文件中的值作为默认值
:param headless_flag: 是否有头,读取Env文件中的值作为默认值,True/False
:return: 返回一个浏览器对象
'''
if self.driver is None:
if not headless_flag:#如果是有头模式
if browser_type == 'chrome':
self.driver = webdriver.Chrome()
elif headless_flag == 'firefox':
self.driver = webdriver.Firefox()
else:
raise Exception(f'暂不支持{browser_type}浏览器')
else:#如果是无头模式
_option = webdriver.ChromeOptions()
_option.add_argument('--headless')#添加无头模式参数'--headless'
if browser_type == 'chrome':
self.driver = webdriver.Chrome(options=_option)
elif headless_flag == 'firefox':
self.driver = webdriver.Firefox(options=_option)
else:
raise Exception(f'暂不支持{browser_type}浏览器')
self.driver.maximize_window()#窗口最大化
self.driver.implicitly_wait(Env.IMPLICITLY_WAIT_TIME)#隐式等待,读取Env文件中IMPLICITLY_WAIT_TIME的值
return self.driver #返回浏览器对象
把要用到的元素操作方法写入到common_basepage.py中
# common_basepage.py
from common_driver import Open_Driver
class BasePage():
'''
存放所有界面元素操作方法
'''
def __init__(self):
self.driver = Open_Driver().get_driver()
def open_url(self,url):
'''打开网址'''
self.driver.get(url)
def get_element(self,locator):
'''
定位元素
:param locator:元素定位器,从elements中取
:return: 元素对象
'''
return self.driver.find_element(*locator)
def input_text(self,locator,text,append=False):
'''
在元素上输入文本
:param locator: 元素定位器
:param text: 要输入的文本
:param append: 是否先清空,默认清空
'''
if append:#不需要清空内容,追加写入
self.driver.find_element(*locator).send_keys(text)
else:#先清空,再写入
self.driver.find_element(*locator).clear()
self.driver.find_element(*locator).send_keys(text)
def click_element(self,locator):
'''
点击元素
:param locator: 元素定位器
'''
self.driver.find_element(*locator).click()
def ele_find_ele_input(self,locator1,locator2,text):
'''
在元素1上找元素2
:param ele1: 元素1
:param ele2: 元素2
:return: 元素2
'''
return self.driver.find_element(*locator1).find_element(*locator2).send_keys(text)
def get_element_text(self,locator):
return self.driver.find_element(*locator).text
页面对象loginpage.py
from common_basepage import BasePage
from datas import Datas
from elements import Elements
from logsuccesspage import LogSuccessPage
class LoginPage(BasePage):
def open_loginpage(self,url):
'''
打开登录页
:param url:登录页url
:return: LoginPage实例对象
'''
self.open_url(url)
return self
def login_baidu(self,username,password):
'''
登录百度账号
:param username: 用户名
:param password: 密码
:return: 登录成功后的页面对象
'''
self.click_element(Elements.LOGIN_BUTTON_OUT)#点击右上角登录
self.ele_find_ele_input(Elements.LOGIN_WIN,Elements.USERNAME_INPUT,Datas.USERNAME)#输入账号
self.ele_find_ele_input(Elements.LOGIN_WIN,Elements.PASSWORD_INPUT,Datas.PASSWORD)#输入密码
self.click_element(Elements.LOGIN_BUTTON_IN)
return LogSuccessPage()
测试用例test_cases.py
from time import sleep
import pytest
from datas import Datas
from elements import Elements
from environment_config import Env
from loginpage import LoginPage
class Test_login():
def test_login01(self):
'''
登录成功的测试
:return:
'''
test_page = LoginPage()#创建实例
test_page.open_loginpage(Env.TEST_URL)#打开测试url
new_page=test_page.login_baidu(Datas.USERNAME,Datas.PASSWORD)#登录百度账号
sleep(2)
text = new_page.get_element_text(Elements.USER_INFO)#登录成功界面
assert text == 'yvvgfffvbh'#断言用户名称是否正确
if __name__ == '__main__':
pytest.main(['-vs'])
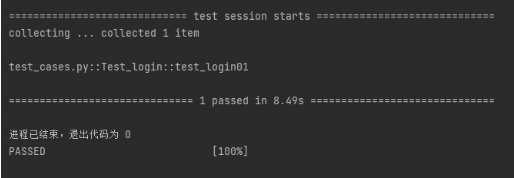
运行结果
写完花了4个小时,感受就是:
1.要理解透彻Python中的面向对象思想。
2.写完整体结构后要继续优化。
可以看到,我们所有数据都放在配置文件中,代码中不会暴露任何的界面元素或账号数据。 最后用pytest执行测试用例即可。
以上只是一个最简版的PO模型项目。只是遵循了po设计准则,并不完整。
一个完整的selenium测试项目大体上应该包括:
1.tools 工具类,格式转换、路径操作等
2.commom 基类,一些公用的方法
3.pageobjects 页面对象类
4.testcases 测试用例
5.test_datas 测试数据,yaml/Excel文件等
6.outfiles 输出文件,log和截图等
7.testreport 测试报告
项目结构并没有具体标准,分类清晰即可。重要的是在设计过程中遵循上文说到的’设计准则‘。
学习安排上
如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片进群即可自行领取。






![nginx设置重定向跳转后ip:[端口]/abc变成ip/abc而报错404](https://img-blog.csdnimg.cn/img_convert/05037283ea87ef2337b896e3b89aee14.png)