LINUX内核链表
一、传统链表的缺陷
传统的双向循环链表概念简单,操作方便,但存在有致命的缺陷,用一句话来概括就是:
每一条链表都是特殊的,不具有通用性。换句话说,对于每一种不同的数据,所构建出来的传统链表都是跟这些数据相关的,所有的链表操作函数也都是数据相关的,换一种数据节点,则所有的操作函数都需要一一重写编写,这种缺陷对于一个具有成千上万种数据节点的工程来说是灾难性的,是不可接受的。
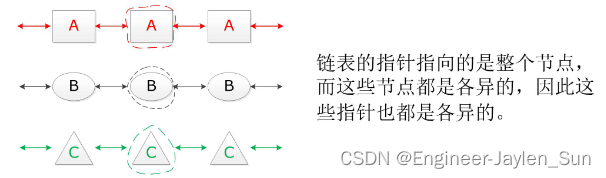
如上图所示因为每个结构体数据类型不同,因此指向整个结构体的指针便不同,然而链表的操作本质上是对指针的操作,因此一个指向了一个既包含了数据又包含了组织逻辑的特殊的指针节点 p 是不具有通用性的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GIFIelAn-1676430823535)(pic/11_special_list_pointer.png)]](https://img-blog.csdnimg.cn/5080998ff665413db7c1fe9c299d5060.png)
二、内核链表
Linux 内核链表的思路把传统链表中的“链”抽象出来,使之成为一条只包含前后指针的纯粹的双循环链表,这样的链表由于不含有特殊的数据,因此它实质上就是链表的抽象表示,类似于一条通用的绳子,在实际应用中只需将这条绳子“嵌入”一个具体的节点当中:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-se8zxHPj-1676430823535)(pic/12_purely_list_node.png)]](https://img-blog.csdnimg.cn/44f878ee92b34f8799dbc975f5525c3b.png)
这样,链表的逻辑就被单独地剥离开来了,链表的操作不再跟具体的数据相关,我们对链表的所有操作都统一为对 Linux 标准抽象链表的操作,他可以适用到任意类型的节点之中。这样做的另一个好处是,使得复杂的数据结构背景变得更易受控,一个节点在系统中的关系网跟一个人在社交网络中的关系网类似。
Linux 内核链表的突出优点是:由于可以非常方便地将其标准实现(即“小结构”)镶嵌到任意节点当中,因而任何数据组成的链表的所有操作都被完全统一。另外,即使在代码的维护过程之中要对节点成员进行升级修改,也完全不影响该节点原有的链表结构。
在Linux内核中,提供了一个用来创建双向循环链表的结构 list_head。虽然 linux内核是用C语言写的,但是list_head的引入,使得内核数据结构也可以拥有面向对象的特性,通过使用操作list_head 的通用接口很容易实现代码的重用,有点类似于C++的继承机制(希望有机会写篇文章研究一下C语言的面向对象机制)。
首先找到list_head 结构体定义,整个结构没有数据域,只有两个指针域。kernel/inclue/linux/types.h 如下:
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
该结构体定义了一个只包含两个指向本身的指针的结构体 list_head,这个结构体就是所谓的“小结构体”,他就是 Linux 内核链表的核心,他将会被“镶嵌”到其他的“大结构体”中,使他们组成链表。
1. 链表初始化
内核提供多种方式来初始化链表:宏初始化和接口初始化。
宏初始化
静态初始化一个 list_head 结构体
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
//举例
//-----------------------------------------------------------------------
LIST_HEAD(mylist);
//这行代码等价于
struct list_head a = LIST_HEAD_INIT(mylist);
也就等价于
struct list_head a = {&mylist, &mylist};
也就是相当于定义了一个 list_head 并且将之初始化为自己指向自己:
接口初始化(常用)
接口操作就比较直接明了,基本上和宏实现的意图一样。直接将链表头指针的前驱和后继都指向自己
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
前面说了 list_head 只有指针域,没有数据域,如果只是这样就没有什么意义了。所以我们需要创建一个宿主结构,然后再再此结构包含 list 字段,宿主结构,也有其他字段(进程描述符,页面管理结构等都是采用这种方法创建链表的)。假设定义如下:
typedef struct node // 包含了具体数据的“大结构体”
{
int data;
struct list_head list; // 被镶嵌在 struct node 中的“小结构体”
}listnode, *linklist
linklist myhead; //节点链表头
初始化链表并创建新的节点示例
//初始化链表
linklist *init_list(void)
{
myhead = malloc(sizeof(listnode));
if (myhead != NULL)
{
INIT_LIST_HEAD(&myhead->list); //使用内核代码,head指向一个初始化的头节点
}
return myhead;
}
// 创建一个新节点
linklist new_node(int data)
{
linklist new = malloc(sizeof(listnode));
if(new != NULL)
{
new->data = data;
//new->list.prev = NULL;
//new->list.next = NULL;
INIT_LIST_HEAD(&new->list);
}
return new;
}
这样链表就初始化完毕,链表头的 prev 和 next指针分别指向 mylist 自己:
2. 添加节点
内核相应的提供了 list_add( ) 和 list_add_tail( ) 两种添加节点的接口, 两个接口都和__list_add() 相关:
__list_add
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
list_add
list_add 定义如下,最终调用的是__list_add 函数,根据注释可知,list_add 是头部插入,总是在链表的头部插入一个新的节点。
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
list_add_tail
list_add_tail 定义如下,最终调用的也是 __list_add 函数,将一个新节点new 插入到节点 head 的前面,因为对于一个双向循环链表而言,插入到 head 的前面就相当于插入到以 head 为首的链表的末端,因此取名为 add_tail.
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
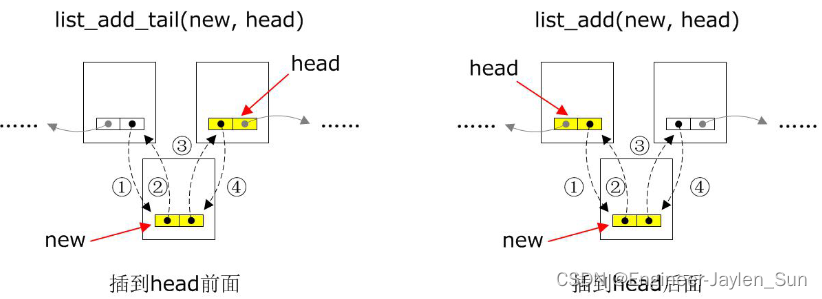
插入节点示例
//创建一个新的客户端节点,并将它放在链表的末端
linklist new = new_node(connfd);
list_add_tail(&new->list, &myhead->list);
3. 删除节点 list_del()
“删除”一个节点实则是将一个节点从链表中剔除,这和之前的传统链表的删除操作是完全一样的。只不过在传统链表中,当将一个节点剔除之后,我们会将他的两边的指针置空,但是看到 Linux 源码并非简单地将 entry->next 和 entry->prev 置空,而是分别给他们喂了两个“POISON(毒药)”:将他们分别赋值为LIST_POISON1 和 LIST_POISON2,这两个宏被定义在 include/Linux/poison.h 之中:
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
利用list_del(struct list_head *entry)接口就可以删除链表中的任意节点了,但需注意,前提条件是这个节点是已知的,既在链表中真实存在,切prev,next指针都不为NULL。
4. 链表遍历
内核是通过过下面这个宏定义来完成对list_head链表进行遍历的,如下 :
list_for_each
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
//上面这种方式是从前向后遍历的,同样也可以使用下面的宏反向遍历:
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
list_for_each_safe
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
//上面这种方式是从前向后遍历的,同样也可以像list_for_each_prev 使用下面的宏反向遍历:
/**
* list_for_each_prev_safe - iterate over a list backwards safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_prev_safe(pos, n, head) \
for (pos = (head)->prev, n = pos->prev; \
pos != (head); \
pos = n, n = pos->prev)
list_for_each 和 list_for_each_safe 区别
list_for_each_safe 用指针 n 对链表的下一个数据结构进行了临时存储,所以如果在遍历链表的时候需要做删除链表中的当前项操作时,用 list_for_each_safe 可以安全的删除 (用n指针可以继续完成接下来的遍历),而不会影响接下来的遍历过程,ist_for_each 是无缓存的,挨个遍历,所以在删除节点的时候,list_for_each需要注意,如果没有将删除节点的前驱后继处理好,那么将引发问题 (删除后会导致无法继续遍历),而 list_for_each_safe 通常不用关心,因此遍历删除节点时常用带 safe 版本的接口, 普通遍历访问情况可以使用不带 safe 版本的接口。
list_for_each 和 list_for_each__safe 的函数参数均是 “小结构体” 的指针, 通过指针 n、head会获得小结构体的地址定位pos。
list_for_each_entry函数的作用
在开发中还会见到 list_for_each_entry 函数该函数和 list_for_each 函数有什么区别呢? 以下具体展开说明
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_last_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_prev_entry(pos, member))
前面说了list_for_each 的函数会获得 “小结构体” 的地址指针 pos, 但是开发中最终是需要“大机构体” 指针,因此在获得 pos后,需将其传入list_entry(ptr, type, member) 函数进一步获得“大结构体” 指针,因此linux 内核中将 list_for_each 函数和list_entry 整合成了一个函数接口 list_for_each_entry.
宿主机构体遍历示例
以下为一个多线程服务器模型
/**
* @brief 服务端遍历查找退出的客户端节点,并删除
*
*/
void del_client(int quitor)
{
struct list_head *pos, *n;
list_for_each_safe(pos, n, &head->list) //迭代删除链表节点
{
client *tmp = list_entry(pos, client, list); //获得大结构体指针
if (tmp->fd == quitor)
{
list_del(pos); //
free(tmp);
break;
}
}
}
/**
* @brief 转发客户端的信息给到系统的其他客户端节点
*
* @param msg
* @param sender
*/
void broad_cast(const char *msg, int sender)
{
struct list_head *pos;
// 遍历整个客户链表
list_for_each(pos, &head->list)
{
client *tmp = list_entry(pos, client, list);
// 如果是发送者本身,直接跳过
if (tmp->fd == sender)
continue;
// 如果时别人,那么将msg发送给他
write(tmp->fd, msg, strlen(msg));
}
}
5. 节点的替换和移位
待研究…
6. 宿主结构体
找出宿主结构** list_entry **(ptr, type, member);
在使用内核链表时,处理的都是“小结构体”,即 struct list_head{ },回顾一下上面那些链表操作函数,他们之所以是通用的,是因为他们的参数统统都是这种小结构体类型,都是基于list_head这个链表进行的,涉及的结构体也都是:
struct list_head {
struct list_head *next, *prev;
};
但是真正的数据并不存在于这些小结构体里面,而是存在于包含他们在内的“大结构体”里面,请看一个更接近现实的内核链表节点内存示意图:
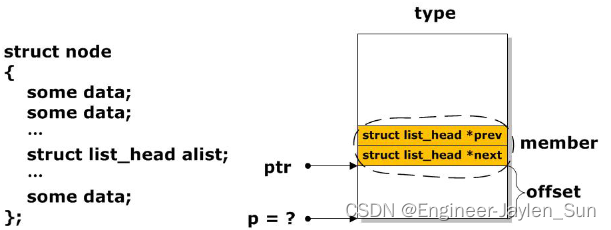
那如何根据 “小结构体” list_head 获得大结构体的地址呢?
从图中可以看出 ptr 是小结构体指针,type 是大结构体的类型(即 struct node),member 是小结构体在大结构体中的成员名(即 alist),如果我们要从 ptr 访问大结构体中的数据 data 的话,就要先求出大结构体的基地址 p。从图示中很容易看出,大结构体的基地址 p 跟小结构体 ptr 之间实际上就相差了 offset 个字节,这个 offset 就是小结构体在大结构体中的偏移量,如果偏移量知道了,那么:p = ptr - offset
而上述偏移计算的过程在linux 内核中已经实现了相关函数接口,用list_entry() 来获取大结构体地址 , list.h中的定义如下:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
参数:
@ptr为小结构体变量成员地址索引
@type为大结构体类型
@member为小结构体的成员对象list
list.h中提供了list_entry宏来实现对应地址的转换,但最终还是调用了 container_of 宏, 以下为 container_of 的定义:
此宏在内核代码 kernel/include/linux/kernel.h中定义(此处kernel版本为4.1.52;其他版本定义可能有所不同,但基本原理一样)
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof 的定义在 kernel/include/linux/stddef.h , 如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
7. 统一的内核链表的操作接口
初始化空链表:INIT_LIST_HEAD()/LIST_HEAD_INIT()
插入节点:list_add()/list_add_tail()
删除节点:list_del()/list_del_init()
移动节点:list_move()/list_move_tail()
合并链表:list_splice()
向后遍历:list_for_each()/list_for_each_safe()/list_for_each_entry()
向前遍历:list_for_each_prev()/list_for_each_entry_prev()
判断是否为空:list_empty()
取得宿主节点指针:list_entry()
8. 代码实例
为了便于验证将 kernel/include/linux/stddef.h 和 kernel/include/linux/list.h 以及 kernel/include/linux/kernel.h 中的相关定义整理成一个新文件 kernel_list.h
**实例1:**输入一个数n, 从1到n构成 一数列,用链表的方式实现奇数和偶数的重新排列,奇数位于数列的前半部分,偶数位于数列的后半部分
/**
* @file odd_even.c
* @author jaylen
* @brief 奇偶数重排
* @version 0.1
* @date 2023-02-14
*
* @copyright Copyright (c) 2023
*
*/
#include <stdio.h>
#include <stdlib.h>
#include "kernel_list.h"
// 一个具体的大结构体
struct node
{
int data;
// 只包含链表逻辑的小结构体
struct list_head list;
};
struct node *new_node(int dat)
{
//struct node *new = malloc(sizeof(struct node));
struct node *new = calloc(1,sizeof(struct node)); //分配新节点时空间清0
if (new != NULL)
{
new->data = dat;
//bzero(&new->list, sizeof(struct list_head)); //清空新节点空间
}
return new;
}
struct node *init_list(void)
{
struct node *head = malloc(sizeof(struct node));
if (head != NULL)
{
INIT_LIST_HEAD(&head->list);
}
return head;
}
void show_list(struct node *head)
{
struct list_head *pos;
struct node *p;
list_for_each(pos, &head->list)
{
p = list_entry(pos, struct node, list);
printf("%d\t", p->data);
}
printf("\n");
}
void rearrange(struct node *head)
{
struct list_head *pos, *tmp;
struct node *p;
int flag = 0;
list_for_each_prev(pos, &head->list)
{
p = list_entry(pos, struct node, list);
if (p->data % 2 == 0 && flag != 0) //偶数
{
list_move_tail(pos, &head->list); // 将p指向的节点移到头节点之前 pos指向p->list
pos = tmp; //移动后从上一次保存的位置开始往前指,避免死循环
}
else
{
tmp = pos; //移动后保存pos
}
flag = 1;
}
}
int main(int argc, char const *argv[])
{
struct node *head;
head = init_list();
int n;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
struct node *new = new_node(i);
list_add_tail(&new->list, &head->list);
}
show_list(head);
rearrange(head);
show_list(head);
return 0;
}
演示结果:
sevan@sevan-vm:kernel_list$ ./odd_even
5
1 2 3 4 5
1 3 5 4 2
关于内核链表后续应用继续研究…
参考链接:在kernel中的链表,其他的链表真的弱爆了
https://cloud.tencent.com/developer/article/1805773
《LINUX环境编程图文指南》