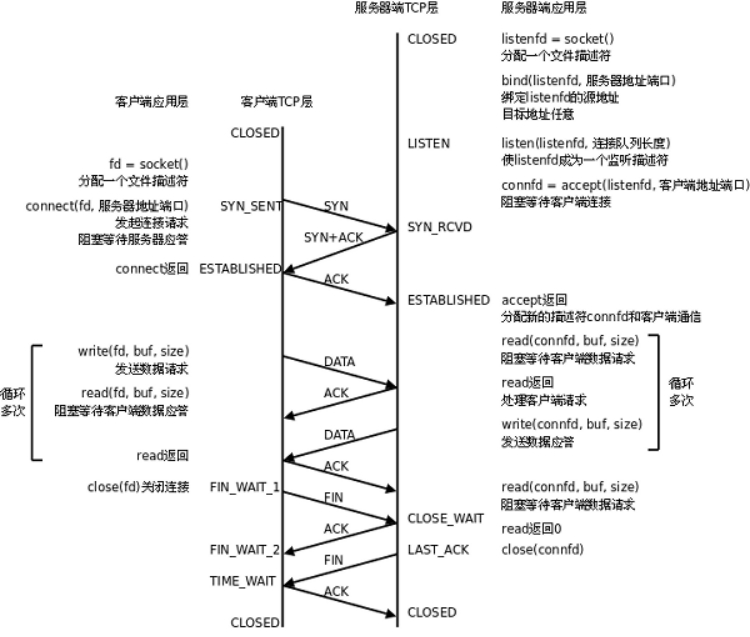
引言
Kafka 是目前非常流行的分布式消息队列系统,被广泛应用于流数据处理、日志分析、事件驱动架构等场景中。Kafka 的高吞吐量和分布式架构在应对海量数据传输方面具有显著优势。然而,Kafka 在处理消费者组时,会面临一个核心问题——重平衡(Rebalance)。重平衡是 Kafka 保持高可用性和分区数据均衡的关键机制,但在某些情况下,重平衡也可能带来性能问题和延迟。
本文将详细介绍 Kafka 的重平衡机制,分析重平衡的触发条件、重平衡过程的详细步骤以及在重平衡过程中可能出现的问题,并提供优化建议。通过图文及代码示例,帮助开发者深入理解 Kafka 的重平衡机制及其优化方法。
第一部分:什么是 Kafka 的重平衡?
1.1 重平衡的定义
重平衡(Rebalance) 是 Kafka 在消费者组内部重新分配分区(Partition)的过程。Kafka 的消费者组是一个逻辑概念,它允许多个消费者实例(Consumer)共同消费一个或多个主题(Topic)的分区。每个分区只能被一个消费者组中的一个消费者消费。因此,重平衡的目的是确保分区在消费者组中的消费者之间合理分配。
1.2 为什么需要重平衡?
Kafka 的消费者组在以下情况下需要进行重平衡:
- 消费者加入或离开消费者组:当消费者组中的消费者增减时,需要重新分配分区以平衡负载。例如,一个新的消费者加入后,原有的消费者可能需要释放部分分区以供新消费者使用。
- 消费者失效:当某个消费者因为网络、系统崩溃等原因失效时,Kafka 必须将其负责的分区重新分配给其他存活的消费者。
- 主题的分区数量发生变化:当 Kafka 的某个主题新增分区时,需要通过重平衡将这些新分区分配给消费者组中的消费者。
1.3 重平衡的触发条件
Kafka 重平衡的触发条件主要有以下几种:
- 消费者组中有消费者加入或离开:例如,某个消费者故障退出或新增消费者实例。
- 分区分配器策略变更:Kafka 提供了多种分区分配策略,如 Range、RoundRobin 等,策略改变后会触发重平衡。
- 主题分区数量增加:分区增加后,需要重平衡将新分区分配给消费者。
第二部分:Kafka 重平衡的过程
Kafka 的重平衡过程是自动触发的,并由 Kafka 的消费者协调器(Consumer Coordinator)来管理。下面我们将详细讲解 Kafka 重平衡的完整流程。
2.1 重平衡的触发
- 消费者组变更检测:Kafka 的消费者组协调器会定期检查消费者组的状态,当消费者组中的消费者加入或离开时,会通知组中的消费者进行重平衡。
- 协调者发出重平衡请求:消费者组的协调者在检测到组的变更后,向所有消费者发出重平衡的通知,要求消费者停止消费,进入重平衡状态。
2.2 停止消费
一旦重平衡触发,消费者必须立即停止消费当前正在处理的分区。Kafka 会通过心跳机制让消费者检测到重平衡的开始,消费者会暂停消费任务,并将当前消费的偏移量(offset)提交给协调器。
// 消费者代码:重平衡监听器
public class MyRebalanceListener implements ConsumerRebalanceListener {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Partitions revoked: " + partitions);
// 在重平衡期间提交偏移量,确保没有数据丢失
consumer.commitSync();
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Partitions assigned: " + partitions);
}
}
2.3 分配分区
在消费者停止消费之后,Kafka 协调者会根据消费者组的分区分配策略(如 Range、RoundRobin 等)重新计算分区的分配方案,将分区均匀分配给组内的消费者。常见的分区分配策略包括:
- Range 分配:按照分区顺序均匀分配,通常会导致部分消费者处理较多的分区。
- RoundRobin 分配:将分区轮询分配给消费者,确保每个消费者接收的分区数尽量接近。
示意图:Range 分配与 RoundRobin 分配
Range 分配:
消费者1: 分区1, 分区2
消费者2: 分区3, 分区4
RoundRobin 分配:
消费者1: 分区1, 分区3
消费者2: 分区2, 分区4
2.4 重新开始消费
一旦分区分配完成,Kafka 协调者会通知消费者组中的所有消费者新的分区分配方案。消费者将根据新的分配结果重新开始消费分配到的分区。在此过程中,消费者会从上一次提交的偏移量开始继续消费,以确保数据不会丢失。
// 消费者代码:重平衡完成后的操作
public class MyRebalanceListener implements ConsumerRebalanceListener {
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
// 从最新的偏移量开始消费
consumer.seek(partition, consumer.position(partition));
}
}
}
2.5 重平衡的完成
当所有消费者成功接收到新的分配结果并开始消费时,Kafka 的重平衡过程完成。此时,Kafka 重新进入正常的消息消费流程。
第三部分:重平衡过程中的常见问题
尽管 Kafka 的重平衡机制能够确保分区的合理分配,但在高并发或复杂场景下,重平衡过程可能会引发一些问题,影响系统的性能和稳定性。
3.1 重平衡导致的消费中断
在重平衡过程中,消费者必须停止消费并等待分区重新分配,这可能导致消费延迟或中断。尤其是在重平衡频繁发生的场景下,消费者可能长时间处于停滞状态,无法及时处理消息。
示例:频繁重平衡导致的延迟
消费者1 离开消费者组 -> 重平衡触发 -> 消费者2 暂停消费 -> 分配新分区 -> 消费者2 重新开始消费
解决方案:
- 减少消费者的波动:尽量减少消费者的频繁加入或退出,可以通过优化部署策略来减少重平衡的触发。
- 优化心跳配置:调整
session.timeout.ms和heartbeat.interval.ms参数,以减少因心跳超时引发的重平衡。
3.2 分区分配不均衡
在某些情况下,Kafka 的分区分配策略可能会导致分配不均衡,某些消费者可能会处理更多的分区,从而导致负载不均衡。例如,使用 Range 分配策略时,最后一个消费者可能会处理更多的分区。
示例:分配不均衡问题
消费者1: 分区1, 分区2
消费者2: 分区3, 分区4, 分区5 -> 消费者2 处理更多分区
解决方案:
- 使用 RoundRobin 分配策略:RoundRobin 可以更均匀地分配分区,减少消费者之间的负载差异。
- 自定义分区分配策略:开发者可以根据业务需求实现自定义的分区分配策略,确保分区更加均匀。
// 使用 RoundRobin 分配策略
Properties props = new Properties();
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
3.3 重平衡频繁触发
在高并发的环境下,如果消费者频繁加入或离开消费者组,或者由于网络问题导致消费者心跳超时,Kafka 的重平衡可能会被频繁触发。这会导致消费者组频繁停止消费,影响消息的处理效率。
解决方案:
- 调整消费者心跳参数:通过增加
session.timeout.ms和heartbeat.interval.ms的时间,可以减少因心跳超时导致的重平衡。 - 稳定的消费者部署:确保消费者实例的稳定性,减少由于实例故障或网络抖动引发的重平衡。
3.4 重平衡期间的消息丢失或重复消费
在重平衡过程中,如果消费者没有及时提交消费偏移量,可能
会导致消息的丢失或重复消费。消费者在重平衡之前没有提交的偏移量会在重平衡后失效,导致 Kafka 认为消息没有被处理过,从而再次分配给其他消费者进行处理。
解决方案:
- 及时提交偏移量:确保消费者在重平衡前正确提交偏移量,可以使用手动提交来保证偏移量的准确性。
- 使用幂等性机制:在业务逻辑中实现幂等性操作,确保即使消息被重复处理,最终结果也是正确的。
// 手动提交偏移量
consumer.commitSync();
第四部分:Kafka 重平衡的优化策略
为了避免重平衡带来的负面影响,提高 Kafka 系统的稳定性和性能,以下是一些优化 Kafka 重平衡的建议和策略。
4.1 减少重平衡的触发频率
频繁的重平衡可能导致消费者长时间停滞,影响系统的吞吐量。减少重平衡的触发频率可以显著提升 Kafka 的性能。
- 优化消费者部署:避免频繁地启动和停止消费者实例,保持消费者的稳定性。
- 增加心跳超时时间:适当增加
session.timeout.ms和heartbeat.interval.ms的时间,可以减少因为心跳超时导致的重平衡。
// 优化心跳参数
Properties props = new Properties();
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000"); // 30秒的会话超时时间
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "10000"); // 10秒的心跳间隔
4.2 使用自定义的分区分配策略
Kafka 提供了多种分区分配策略,但在某些业务场景中,开发者可以根据需求实现自定义的分区分配策略,确保分区分配的灵活性和均衡性。
// 实现自定义分区分配策略
public class CustomPartitionAssignor implements PartitionAssignor {
@Override
public String name() {
return "custom-partition-assignor";
}
@Override
public Map<String, List<TopicPartition>> assign(Cluster cluster, Map<String, ConsumerGroupMetadata> groupMetadata, Map<String, List<TopicPartition>> partitionsPerConsumer) {
// 自定义分区分配逻辑
}
}
4.3 优化分区数和消费者数的匹配
Kafka 的分区数与消费者数量直接影响重平衡的性能。如果分区数与消费者数量不匹配,可能会导致分区分配不均衡或重平衡延迟。因此,优化分区数与消费者数量的匹配关系可以提升重平衡的效率。
- 消费者数量不应超过分区数:如果消费者数超过分区数,某些消费者将无法分配到分区,从而浪费资源。
- 分区数应尽量为消费者数的倍数:确保每个消费者可以均匀分配到分区。
4.4 使用消费者组管理工具
Kafka 提供了一些消费者组管理工具,帮助开发者监控和管理消费者组的状态。通过这些工具,可以实时监控消费者组的状态,检测重平衡问题,并采取相应的优化措施。
# 查看消费者组状态
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-consumer-group
第五部分:Kafka 重平衡的代码示例
以下是一个完整的代码示例,展示了如何使用 Kafka 消费者组并处理重平衡。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Properties;
import java.util.Collection;
public class KafkaRebalanceExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-consumer-group");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"), new MyRebalanceListener(consumer));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed record with key %s and value %s%n", record.key(), record.value());
// 处理消息
}
consumer.commitSync(); // 手动提交偏移量
}
}
}
class MyRebalanceListener implements ConsumerRebalanceListener {
private KafkaConsumer<String, String> consumer;
public MyRebalanceListener(KafkaConsumer<String, String> consumer) {
this.consumer = consumer;
}
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Partitions revoked: " + partitions);
consumer.commitSync(); // 提交偏移量,避免重平衡导致消息丢失
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Partitions assigned: " + partitions);
}
}
第六部分:总结与展望
6.1 总结
Kafka 的重平衡机制是消费者组中不可避免的一部分,通过重平衡,Kafka 可以动态调整分区分配,确保消费者组的高可用性和负载均衡。然而,频繁的重平衡可能导致性能问题、延迟甚至消息丢失。因此,理解 Kafka 重平衡的触发条件和过程,并针对重平衡问题进行优化,是保障 Kafka 系统高效稳定运行的关键。
本文详细介绍了 Kafka 重平衡的工作原理,重平衡的触发条件、分区分配策略、常见问题及优化建议。通过代码示例,开发者可以更好地理解如何管理 Kafka 重平衡过程中的各个环节,减少重平衡带来的负面影响。
6.2 展望
随着分布式系统的发展,Kafka 在处理高并发、海量数据传输时表现优异。未来,Kafka 可能会进一步优化其重平衡机制,引入更加灵活、智能的分区分配算法,减少重平衡带来的性能损耗。开发者应持续关注 Kafka 的新特性和优化方案,提升系统的稳定性和性能。