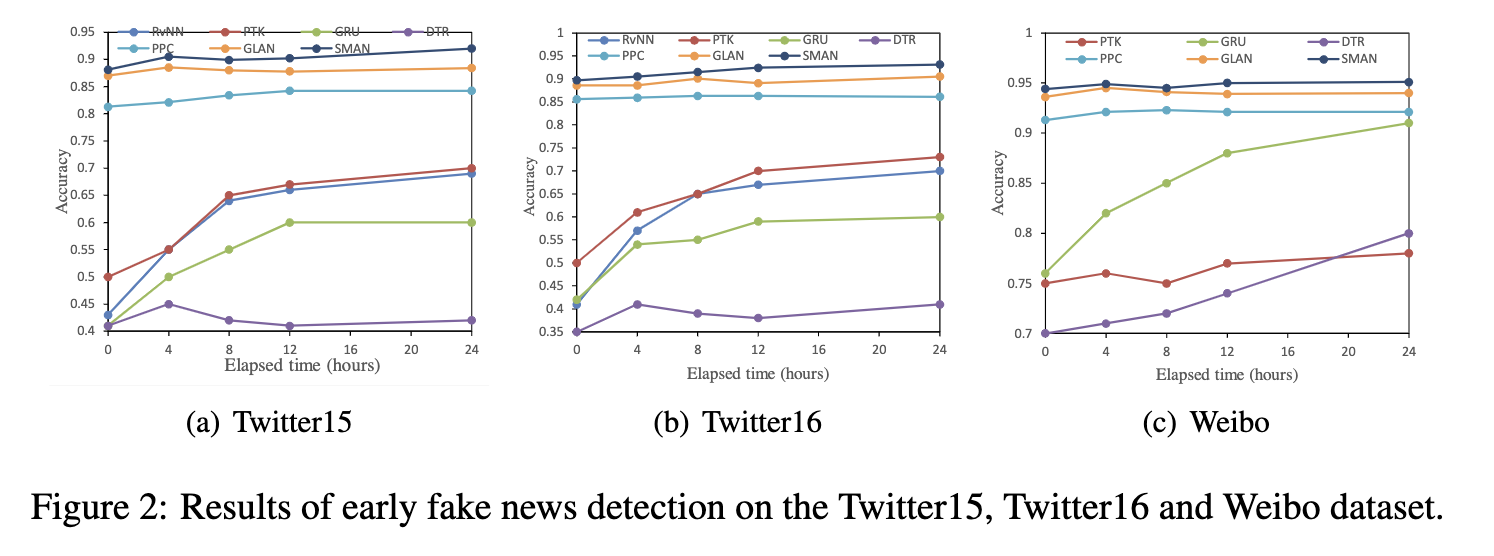
1 为什么选择kafka?
① 实时写入,实时读取
② 消息队列适合,其他数据库受不了
2 ods层
1)存储原始数据
埋点的行为数据 (topic :ods_base_log)
业务数据 (topic :ods_base_db)
2)业务数据的有序性: maxwell配置,指定生产者分区的key为 table
3 dwd+dim层
① 事实表存Kafka
② 维度表存Hbase,基于热存储加载维表的join方案:
随机查
长远考虑
适合实时读写
DIM:事实数据根据维度ID查询相应的维度数据
HBase:√
Redis:用户表数据量大,内存使用量太大
HDFS(Hive):太慢,效率低
Mysql:维表数据属于业务库,实时计算查询MySQL会给业务库增加压力--从库 √
ClickHouse:QPS高、列存
3.1 动态分流
将事实表写入kafka的dwd层,将维度表写入hbase。为了避免因表的变化而重启Flink任务,在mysql存一张表来动态配置。
DIM层编程:
1.消费Kafka topic_db主题数据(包含所有的业务表数据)
2.过滤维表数据(根据表名做过滤)
3.将数据写入Phoenix(每张维表对应一张Phoenix表)
按照当前的思路,如果增加一张维表,需要修改代码,重新编译,关闭以前的程序并启动新程序!
讨论1:如何做到只重启,不修改代码?
读配置文件(Mysql,Redis,HBase):只在启动的时候加载
讨论2:如何做到不重启?
动态加载:
1、 每隔一段时间自动加载(Java中的定时任务) 定时任务写于open方法中
2、 实时监控抓取配置信息数据:
① 配置信息写到MySQL --> FlinkCDC抓取
② 配置信息写到File --> Flume+Kafka+Flink消费
③ 广播流+connect:广播状态大小问题 √
④ Keyby+connect:容易数据倾斜
FlinkCDC实时抓取MySQL内配置信息:
① 读取一张配置表
② 维护这张配置表: source来源 sink写到哪 操作类型 字段 主键 扩展
③ 实时获取配置表的变化
④ CDC工具 -- FlinkCDC
⑤ 使用了SQL的方式,去同步这张配置表,SQL的数据格式比较方便
扩展思路:推送的方式,ZK通知机制
3.2 怎么写HBase
① 借助phoenix
② 没有做维度退化,维表数据量小、变化频率慢
③ 最大的维表:用户维表,百万日活,2000万注册用户为例,1条平均1k:2000万*1k=约20G,使用Phoenix创建的盐表,避免数据热点问题 – https://developer.aliyun.com/article/532313
4 dwm层
4.1 为什么要加一个dwm层?
DWM层主要服务DWS,因为部分需求直接从DWD层到DWS层中间会有一定的计算量,而且这部分计算的结果很有可能被多个DWS层主题复用,所以部分DWD层会形成一层DWM。
– 访问UV计算
– 跳出明细计算
– 订单宽表
– 支付宽表
4.2 事实表与事实表join
① 事实表与事实表的双流Join,使用了Interval Join
② Join不上的数据怎么办?
在Flink中的流join大体分为两种 ,一种是基于时间窗口的join(Time Windowed Join),比如join、coGroup等。另一种是基于状态缓存的Join(Temporal Table Join),比如IntervalJoin。
IntervalJoin相比较窗口join,IntervalJoin使用更简单,而且避免了应该匹配的数据处于不同窗口的问题。intervalJoin目前只有一个问题,就是还不支持left join。
由于订单主表与订单从表之间的关联不需要left join,所以intervalJoin是较好的选择。
4.3 事实表与维度表join
维度关联采用了热存储加载的join方案,实际上就是在流中查询存储在hbase中的数据表。但是即使通过主键的方式查询,hbase速度的查询也是不及流之间的join。外部数据源的查询常常是流式计算的性能瓶颈,所以在这个基础上还能进行一定的优化。
1)旁路缓存模式
旁路缓存模式是一种非常常见的按需分配缓存的模式。 如图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则查询数据库,同时把结果写入缓存以备后续请求使用。

2)异步IO
Flink 在1.2中引入了Async I/O,在异步模式下,将IO操作异步化,单个并行可以连续发送多个请求,哪个请求先返回就先处理,从而在连续的请求间不需要阻塞式等待,大大提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,解决了与外部系统交互时网络延迟成为了系统瓶颈的问题。

异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,单个并行可以连续发送多个请求,提高并发效率。
这种方式特别针对涉及网络IO的操作,减少因为请求等待带来的消耗。
4.4 怎么保证缓存一致性
当我们获取到维表更新的数据,也就是拿到维度表操作类型为update时:
1)更新Hbase的同时,删除redis里对应的之前缓存的数据
2)redis设置了过期时间:24小时
5 dws层
5.1 为什么选择ClickHouse
1)适合大宽表、数据量多、聚合统计分析 =》 快
2)宽表已经不再需要join,很合适
5.2 轻度聚合
1)DWS层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。
2)开一个小窗口,5s的滚动窗口
3)同时减轻了写ClickHouse的压力,减少后续聚合的时间
4)几张表? 表名、字段
访客、商品、地区、关键词
6 ads层
6.1 实现方案
为可视化大屏服务,提供一个数据接口用来查询ClickHouse中的数据。

6.2 怎么保证ClickHouse的一致性?
ReplacingMergeTree只能保证最终一致性,查询时的sql语法加上去重逻辑
7 监控
Prometheus + Grafana