Kaldi语音识别技术(五) ----- 特征提取
文章目录
- Kaldi语音识别技术(五) ----- 特征提取
- 一、识别流程
- 二、MFCC特征提取概述
- 三、文件格式
- 文件格式说明
- 提取部分数据
- 修复提取数据
- 提取剩余部分数据
- 四、特征提取
- 特征提取—C++
- 特征提取—并行提取
- 特征提取—特征查看
- 五、CMVN
- CMVN—脚本
- CMVN—命令
一、识别流程
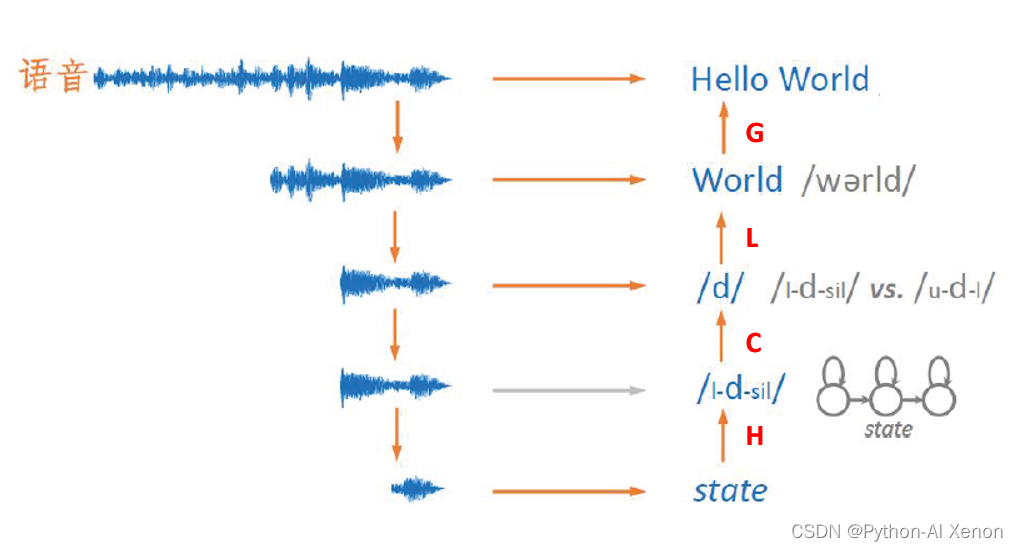
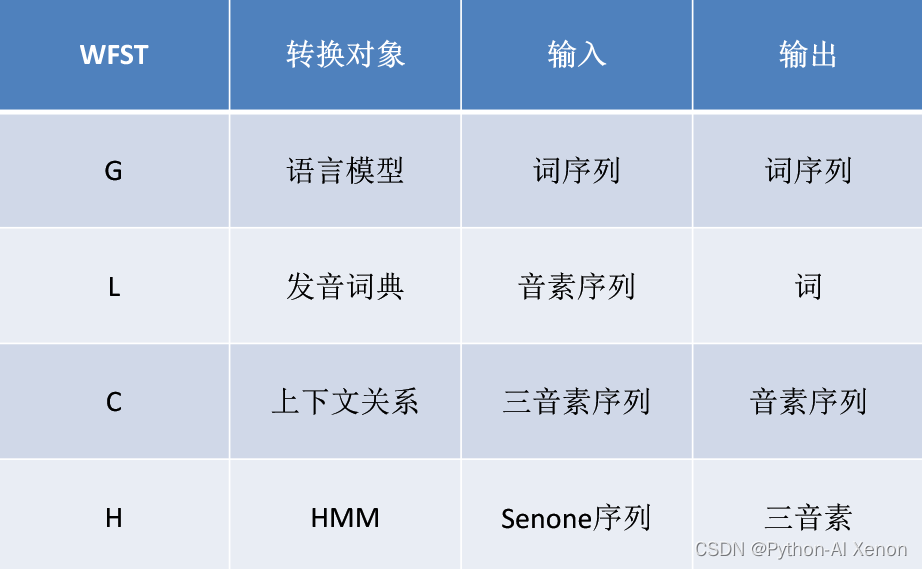
在之前的文章中我们已经完成了L.fst和G.fst的生成,在这里简单对Kaldi语音识别的整体进行一个回顾。
二、MFCC特征提取概述
人通过声道产生声音,声道的shape决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素(phoneme)进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCC就是一种准确描述这个包络的一种特征。所谓特征提取,也就是提取语音信号中有助于理解语言内容的部分而丢弃掉其它的东西(比如背景噪音和情绪等等)。
MFCC(Mel频率倒谱系数:Mel-Frequency Cepstral Coefficients)是一种在自动语音和说话人识别中广泛使用的声学特征。它是在1980年由Davis和Mermelstein搞出来的。从那时起。在语音识别领域,MFCC在人工特征方面可谓是鹤立鸡群,一枝独秀,从未被超越啊(至于说Deep Learning的特征学习那是后话了)。
语音的产生过程如下:语音信号是通过肺部呼出气体,然后通过声门的开启与闭合产生的周期信号。再通过声道(包括舌头牙齿)对信号调制后产生。区分语音的关键就是声道的不同形状。不同的形状就对应不同的滤波器,从而产生了不同的语音。如果我们可以准确的知道声道的形状,那么我们就可以得到不同的音素(phoneme)的表示。声道的形状体现在语音信号短时功率谱的包络(envelope)中,因此好多特征提取方法需要准确的表示包络信息。
MFCC特征提取流程如下:
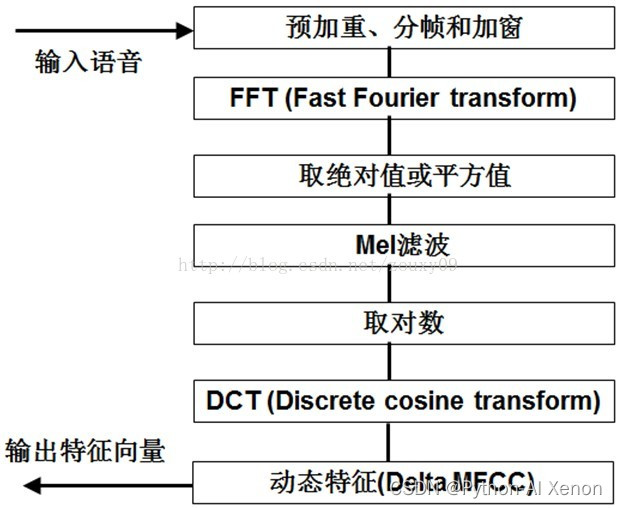
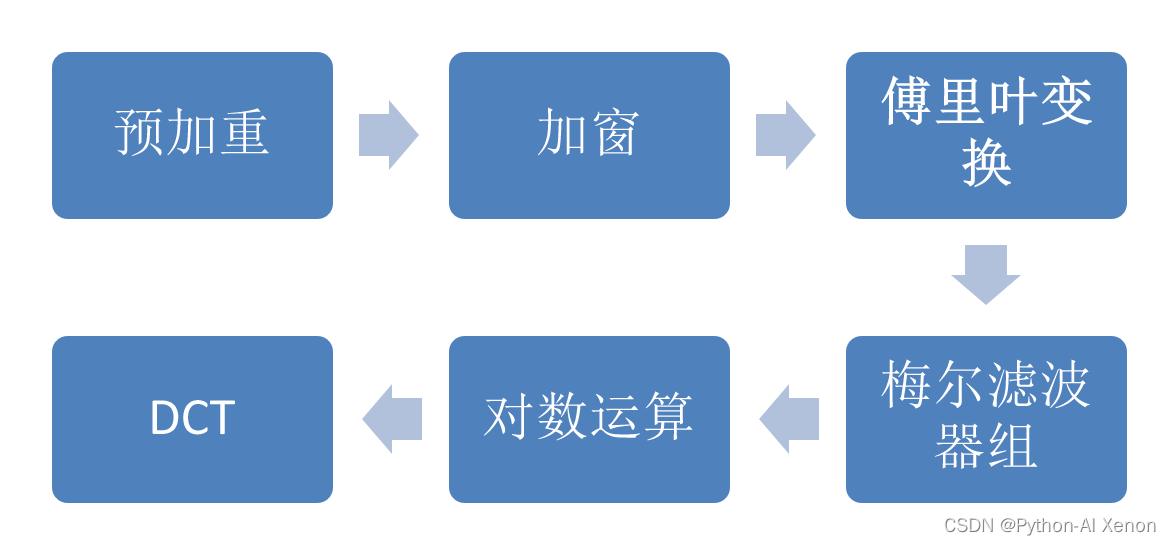
MFCC使得特征更具区分性:
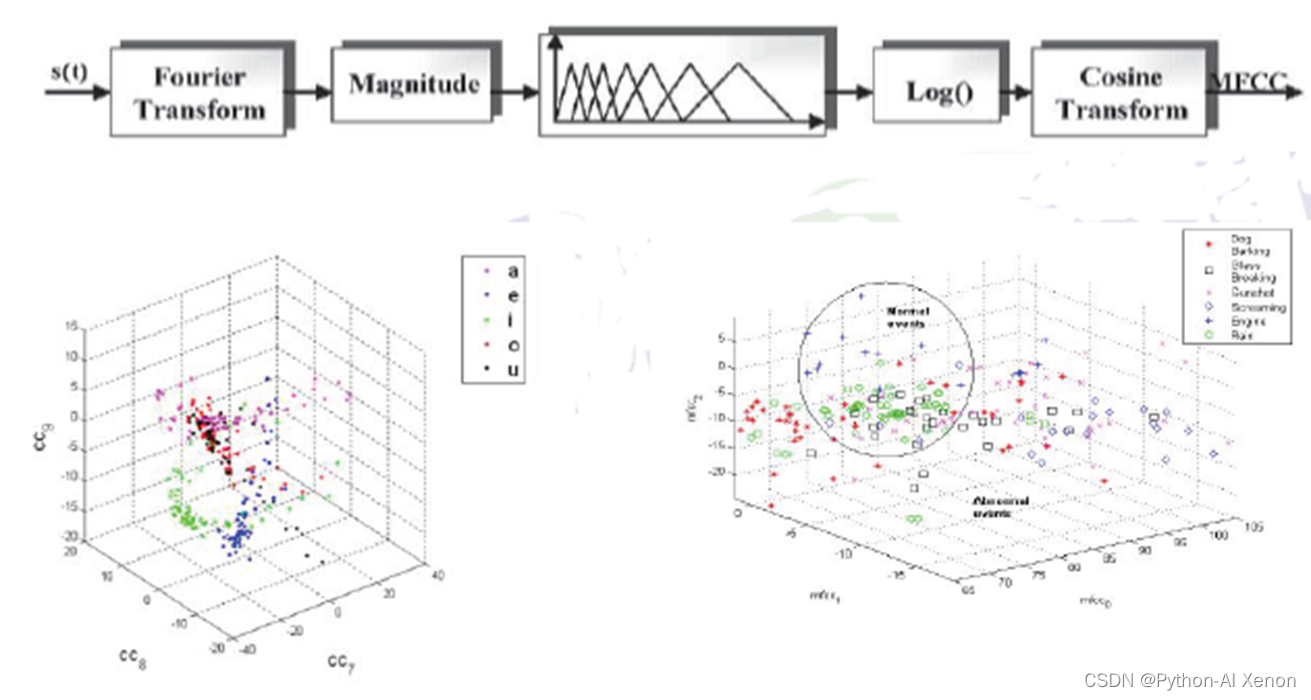
预加重
人的发音特性,每个发音段到高频部分能量就降下来了。同时,人们认为高频的信息对识别音素有帮助,人们为了使用这个高频特征来去识别音素,就需要把高频能量往上提。主要通过加一个一阶高通滤波器来实现,以提升高频部分。
加窗
把音频分为一小段一小段,每20ms一段
窗长 假设为20ms 只看20ms的内容
窗移 假设为10ms 每次窗移动10ms
有重叠
离散傅里叶变化(FFT)
需要把一个窗口的数据,从时域上转化为频域上来处理。
需要在频域上判断:
1、任何信号都可以看成不同频率正弦波的叠加。
2、如果现在有一个纯的正弦波,在频谱上判断,就在对应的频率上有一个亮点(能量),没有其他的频率成分,就一个。
3、频率的取值范围是0-正无穷
梅尔滤波器
根据人耳的特性设计的这一个特征
人耳是对低频很敏感,低频只要变一点,人耳都可以听出来声音的不同(500Hz—800Hz,可以听出不同),但是如果频率变的很高,高频变一点,人耳就听不出来不同(2000Hz—3000Hz)
人耳机制:低频敏感,高频很不敏感
正常的傅里叶变化频率的取值范围是0-正无穷,需要把这个信息映射到梅尔频域上(普通频域 - > 梅尔滤波器 - > 梅尔频域)
基于人耳特性
梅尔频率,低频分辨率高,高频分辨率低
梅尔滤波器
低频 分布密集,均匀分布
高频 滤波器越来越大,log形式
逆傅里叶变换
对频域再做一个傅里叶变换,把它反过来
逆傅里叶变换如果是对称的话,做的就是离散余弦变换(DCT)
做了DCT之后,取前12维度信息,就是我们看到的数据
MFCC的第一维度是能量(12+1 = 13维度)
CMVN均值方差归一化
针对每个发音人的倒谱(特征)的均值和方差,以降低不同发音人统计特性,达到普适性。
把每一维度的数都换成均值为0、方差为1的正态分布。即,减均值/方差
运行准备
. ~/kaldi/path.sh
cd ~/kaldi/data
mkdir H
cp -R /root/kaldi/kaldi_file ./
三、文件格式
文件格式说明
scp 不存放真实数据,只存放路径(基本文件wav.scp)
ark 生成的特征文件(二进制),用语存放真实数据
提取部分数据
提取部分音频信息用于训练集和测试集
提取方法 subset_data_dir.sh [--speakers|--shortest|--first|--last|--per-spk] <srcdir> <destdir>
./utils/data/subset_data_dir.sh ../kaldi_file/ 100 ./H/kaldi_file_test
参数详解:
第一个参数:存放4个基本文件的文件夹(wav.scp,utt2spk,spk2utt,text)
第二个参数:要提取的数量
第三个参数:提取后存放的文件夹

使用介绍: https://blog.csdn.net/qq_36782366/article/details/103543480
修复提取数据
在制作4个基本文件时,text的文件可能因各种因素(如空内容)比其他3个文件少,可以使用以下命令(根据text文件)删除(utt2spk,spk2utt,text)多余的内容,达到一致性
./utils/data/fix_data_dir.sh ./H/kaldi_file_test
参数详解:
kaldi_file_test 存放4个基本文件的文件夹(wav.scp,utt2spk,spk2utt,text)

提取剩余部分数据
提取了指定数量的部分音频信息后,需要将剩余未提取的提取出来
1、获取已提取音频信息的utt
cd ./H/kaldi_file_test
awk -F ' ' '{print($1)}' text >./H/utt_id.txt

2、查找剩余音频text
将已提取的utt与全部的音频text中的第一列(utt)匹配比对,并取反,得到未提取的音频信息
mkdir train
grep -v -F -w -f kaldi_file_test/utt_id.txt kaldi_file/text > ./train/text
3、复制所有的音频信息(除text之外)
cp kaldi_file/{utt2spk,spk2utt,wav.scp} train/
4、修复提取数据
cd ..
./utils/fix_data_dir.sh ./H/train/
四、特征提取
特征提取—C++
compute-mfcc-feats
用法:compute-mfcc-feats scp:xxx.scp ark:xxx.ark
compute-mfcc-feats scp:kaldi_file/wav.scp ark:all.ark
参数详解:
第一个参数为传入的wav.scp文件(音频路径)
第二个参数为生成的特征文件
1、查看ark文件
ark为二进制文件,无法直接查看。可通过命令将ark文件生成文本文件查看:
copy-feats ark:all.ark ark,t:all.txt

2、直接生成文本文件
compute-mfcc-feats scp:kaldi_file/wav.scp ark,t:all2.txt
特征提取—并行提取
准备配置文件
在~/kaldi/data文件夹中创建一个conf/mfcc.conf配置文件,可在配置文件配置以下2个参数
–user-energy true表示提取出的mfcc特征含能量信息(第一列),false表示不含能量信息
–sample-frequency 视频的采样率
如果提取特征时不含配置文件,默认的user-energy为true, sample-frequency为16000
cd ~/kaldi/data
vim conf/mfcc.conf
# 添加以下信息后保存退出
--use-energy=false # only non-default option.
--sample-frequency=16000
make_mfcc.sh
在data文件夹中运行以下命令:
./steps/make_mfcc.sh --cmd "run.pl" --mfcc-config conf/mfcc.conf --nj 2 H/kaldi_file_test/ H/mfcc/exp/ H/mfcc/
注:由于本脚本第20行要判断是否有path.sh 所以需要将~/kaldi/utils/path.sh 复制到data目录中。
参数详解:
–cmd run.pl单机运行;queue.pl集群运行
–mfcc-config 是否使用自定义的配置文件,如使用该参数则需要在该参数后添加自定义的配置文件, mfcc的配置文件是写死的,在与make_mfcc同级的conf/mfcc.conf
–nj 开几个线程提取特征(根据自身资源合理设置)
train_make_mfcc/kaldi_file/ 主要是wav.scp,utt2spk,spk2utt
train_make_mfcc/exp/ 日志文件
train_make_mfcc/mfcc/ :
1、raw_mfcc_kaldi_file.N.ark 最终输出的特征文件
2、raw_mfcc_kaldi_file.N.ark.txt 使用copy-feats生成的文本文件
3、raw_mfcc_kaldi_file.N.scp 路径
上述的N为N个线程,即有N个线程就会单独生成N个.ark和.scp文件

特征提取—特征查看
这里为了方便讲解,只提一句音频的特征
在data文件夹中创建文件夹用于存放特征:H/mfcc/
cd ~/kaldi/data/H
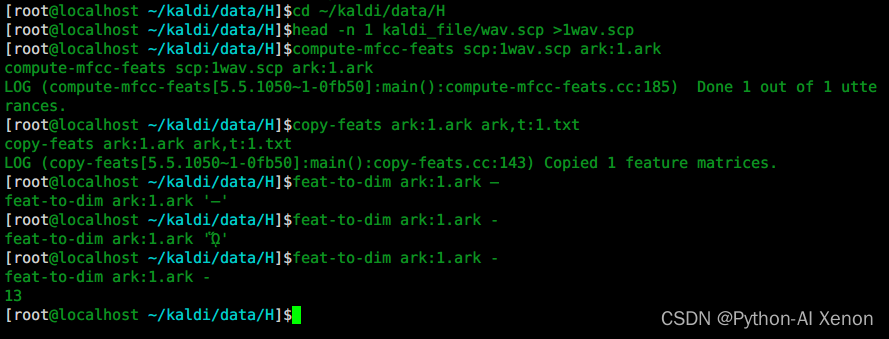
head -n 1 kaldi_file/wav.scp >1wav.scp
提取MFCC特征:
compute-mfcc-feats scp:1wav.scp ark:1.ark
生成文本格式的MFCC特征:
copy-feats ark:1.ark ark,t:1.txt
查看特征值维度:
feat-to-dim ark:1.ark -
五、CMVN
CMVN—脚本
compute_cmvn_stats.sh
注:这个脚本只能做每个人的发音特征的CMVN
cd ~/kaldi/data
./steps/compute_cmvn_stats.sh H/kaldi_file_test H/mfcc/exp/ H/cmvn/
参数详解:
第一个参数:提取特征后在原数据文件夹中生成的scp文件(含feats.scp文件夹)
第二个参数:输出日志
第三个参数:输出的cmvn文件

CMVN—命令
在每个人的发音特征上做CMVN
compute_cmvn_stats
compute-cmvn-stats --spk2utt=ark:kaldi_file_test/spk2utt scp:kaldi_file_test/feats.scp ark,scp:cmvn/per.ark,cmvn/per.scp
参数详解:
第一个参数:要提取特征的文件的spk2utt文件
第二个参数:提取特征后在原数据文件夹中生成的scp文件
第三个参数:输出的cmvn和scp文件

在所有人的发音特征上做CMVN
compute_cmvn_stats , H文件夹下执行
compute-cmvn-stats scp:kaldi_file_test/feats.scp cmvn/global.cmvn
参数详解:
第一个参数:提取特征后在原数据文件夹中生成的scp文件
第二个参数:输出的cmvn文件

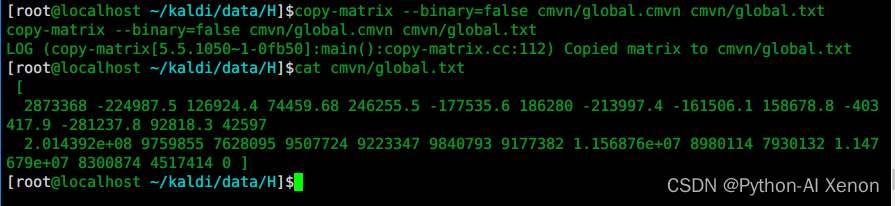
查看global.cmvn
copy-matrix --binary=false cmvn/global.cmvn cmvn/global.txt
cat cmvn/global.txt
在特征上做CMVN
apply-cmvn --utt2spk=ark:train_compute-mfcc-feats/utt2spk --norm-means=true
--norm-vars=false scp:train_compute-mfcc-feats/cmvn_train_compute-mfcc-feats.scp scp:train_compute-mfcc-feats/raw_mfcc_train_compute-mfcc-feats.1.scp ark,t:after_cmvn.ark
参考文章:
MFCC特征提取教程
梅尔频率倒谱系数(MFCC) 学习笔记
初识语音识别及 Kaldi 的安装使用