JMM
- 一、JMM——原子性-(synchronized)
- 二、JMM——可见性-问题
- 2.1 退不出的循环
- 2.2 可见性——解决
- 2.3 可见性
- 三、JMM——有序性-问题
- 3.1 诡异的结果
- 3.2 解决方法
- 3.3 有序性理解
- 3.4 happens-before
JMM 即 Java Memory Model,简单地说,JMM定义了一套在多线程读写共享数据(成员变量、数组)时,对数据的可见性、有序性、和原子性的规则和保障。它定义了主存(共享内存)、工作内存(线程私有)抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、 CPU 指令优化等。
一、JMM——原子性-(synchronized)
语法
synchronized(对象){
要作为原子操作代码
}
用synchronized解决并发问题
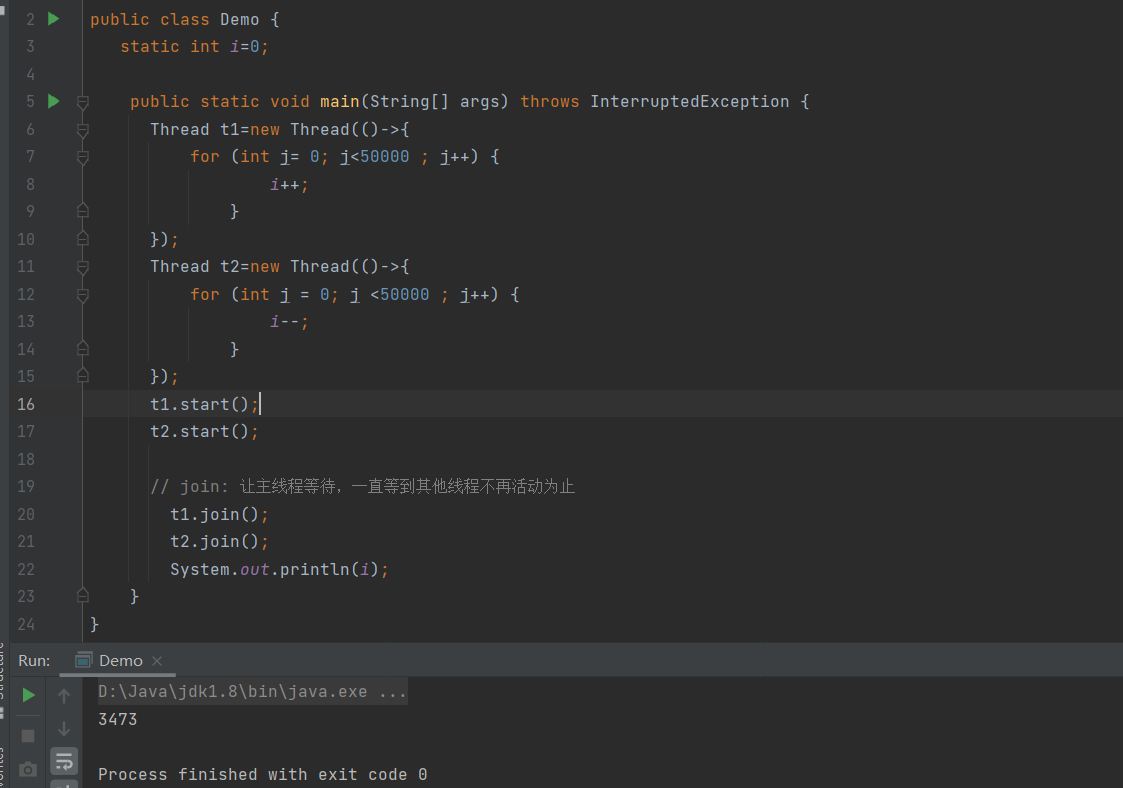
public class Demo {
static int i=0;
static Object obj=new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i= 0; i<50000 ; i++) {
synchronized (obj) {
i++;
}
}
});
Thread t2=new Thread(()->{
for (int j = 0; j <50000 ; j++) {
synchronized (obj) {
i--;
}
}
});
t1.start();
t2.start();
// join: 让主线程等待,一直等到其他线程不再活动为止
t1.join();
t2.join();
System.out.println(i);
}
}
建议用synchronized对对象加锁的力度稍微大些(上述写法需对对象锁进行50000操作,较耗时),可将代码做如下调整:
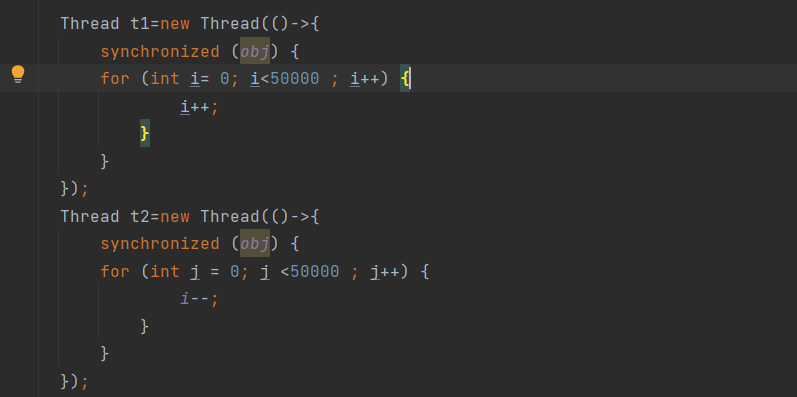
如何理解呢:可以将obj想象成一个房间, 线程t1, t2想象成两个人。
当线程t1执行到synchronized(obj)时就好比t1进入了这个房间,并反手锁住了门,在门内执行count++代码。
这时候如果t2也运行到了synchronized(obj)时,它发现i ]被锁住了,只能在i门外等待。
当tl执行完synchronized{}块内的代码,这时候才会解开门上的锁,从obj房间出来。t2 线程这时才可以进入obj房间,反锁住门,执行它的count–代码。
上例中tl和t2线程必须用synchronized锁住同-个obj对象,如果1锁住的是ml对象,t2 锁住的是m2对象,就好比两个人分别进入了两个不同的房间,没法起到同步的效果
实际开发中,具体业务具体分析,如果业务很短多应使锁的粒度应该尽可能的小,这样便可缩短其他线程等待时间,以敬可能的提高并发效率
JMM——原子性-问题
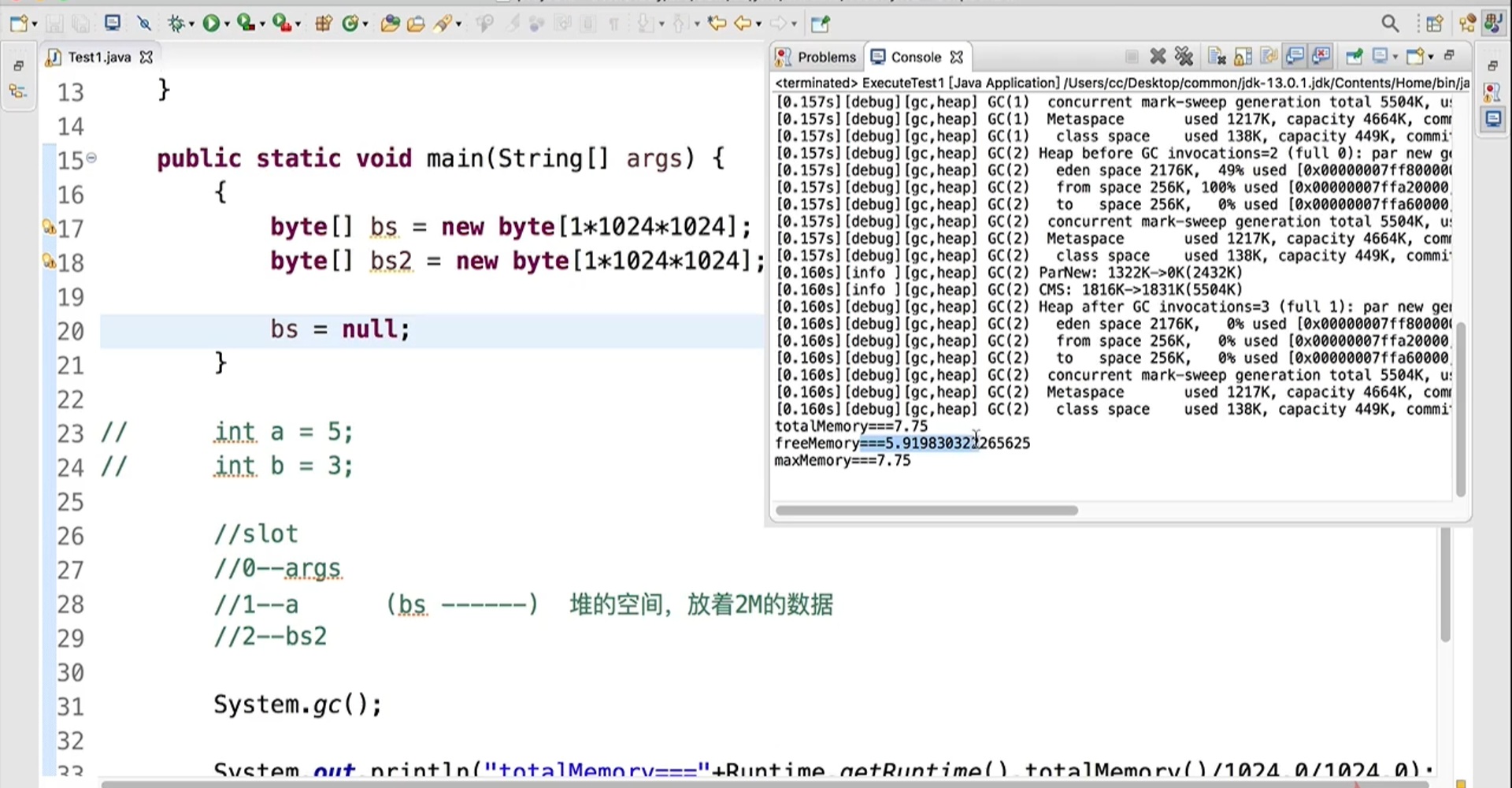
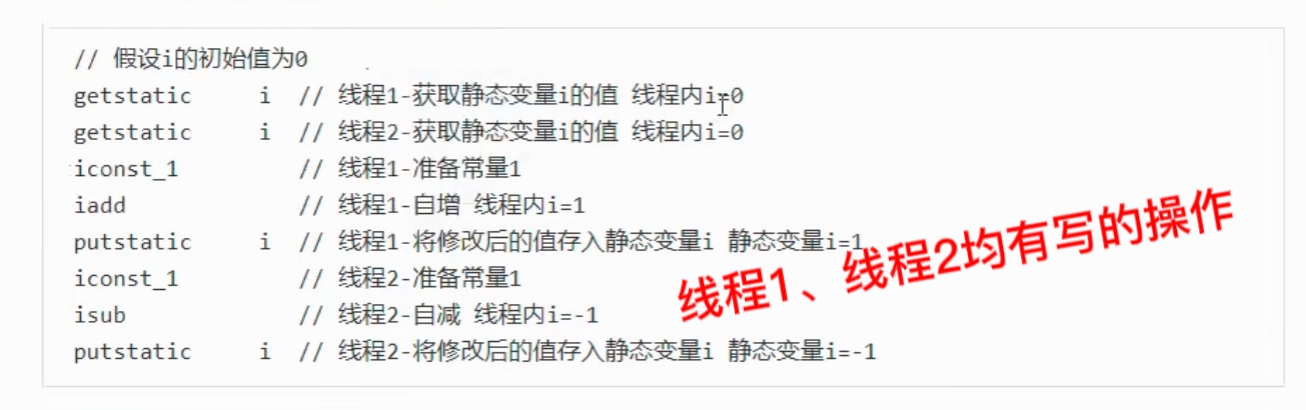
问题提出:两个线程对初始值为0的静态变量,一个做自增,一个做自减,各做5000次,结果是0吗?
以上的结果可能是正数、负数、零。【Java中对静态变量的自增,自减并不是原子操作;在多线程环境下这些操作可能会被CPU进行交错执行】
例如相对于i++而言(i为静态变量)====>静态变量的i++需要将静态变量和常数都放在操作数栈用iadd来完成自增,并非在局部变量表中直接执行 ,实际产生如下的JVM指令:
getsatic i // 获取静态常量i的值
iconst i // 准备常量1
iadd // 加法【局部变量自增调用iinc】
putstatic i // 将修改后的值存入静态变量i
对应i–也是类似:
getsatic i // 获取静态常量i的值
iconst i // 准备常量1
isub // 加法
putstatic i // 将修改后的值存入静态变量i
而Java的内存模型分为如下两部分(主内存、工作内存),完成静态变量的自增,自减需要在主存和线程内存中进行数据交换:
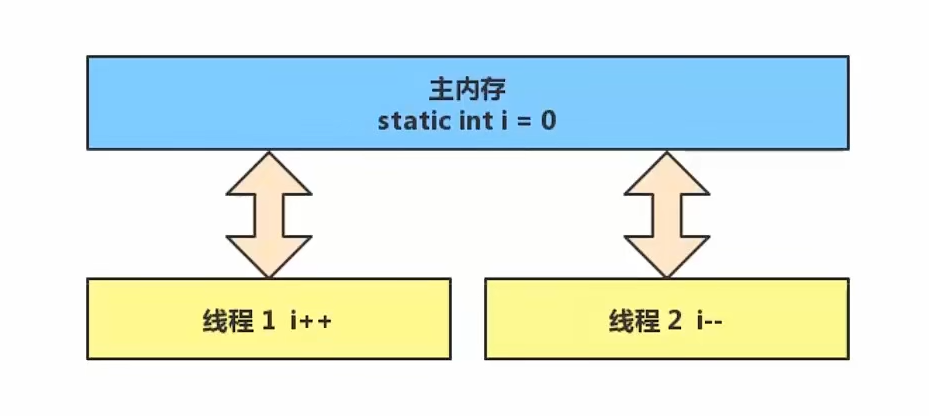
静态变量(共享的变量)放在主存中;线程则是在工作内存中
① 若为单线程以上8行代码是顺序执行(不会交错)没有问题:

② 但多线程下这8行代码可能交错运行
操作系统的线程模型都是一种抢先多任务模型,线程会轮流拿到CPU的使用权;CPU会以时间片为单位,在时间片1把使用权交给线程1运行,在时间片2再把线程分给线程2运行===>多个线程轮流使用CPU
出现负数的情况:【第一个线程执行getstatic获取到静态变量的初始值(i=0),恰巧在此时刻时间排片被用完,CPU将其剔出,于是CPU开始执行线程2的代码…】

出现正数的情况:

二、JMM——可见性-问题
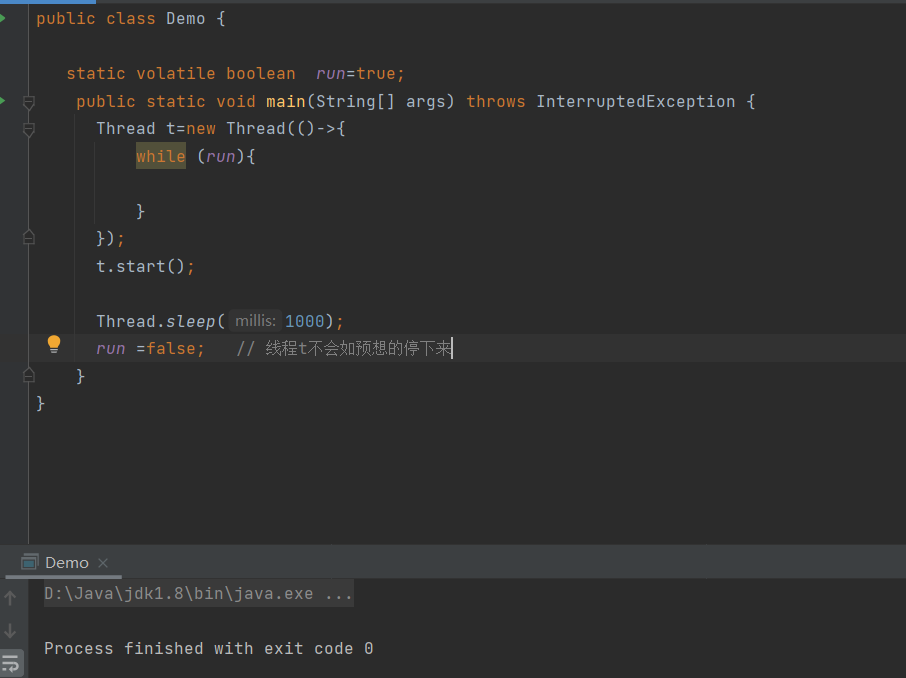
2.1 退不出的循环
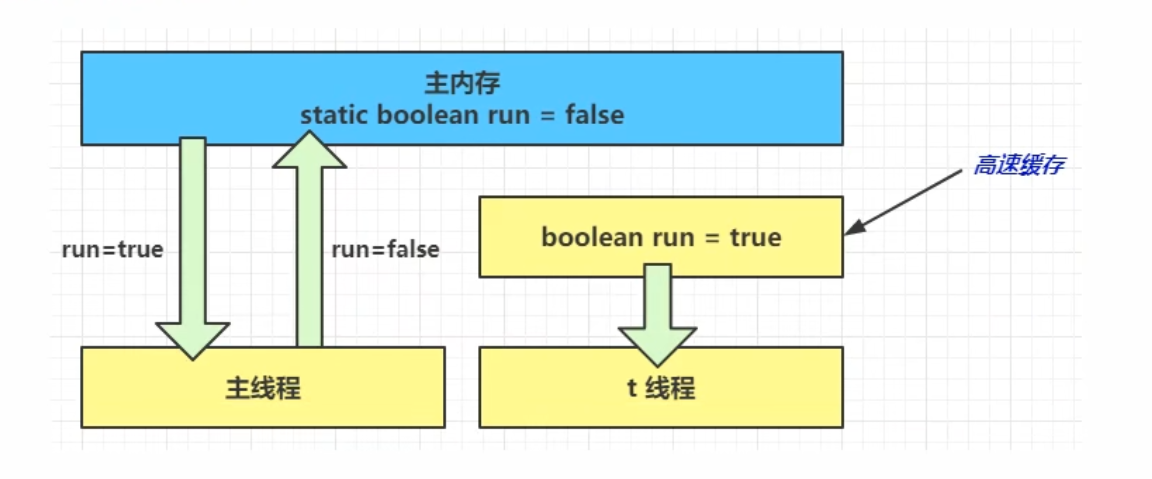
观察现象,main线程对run变量的修改对于t线程不可见,导致了t线程无法停止(程序始终不能停止下来)
1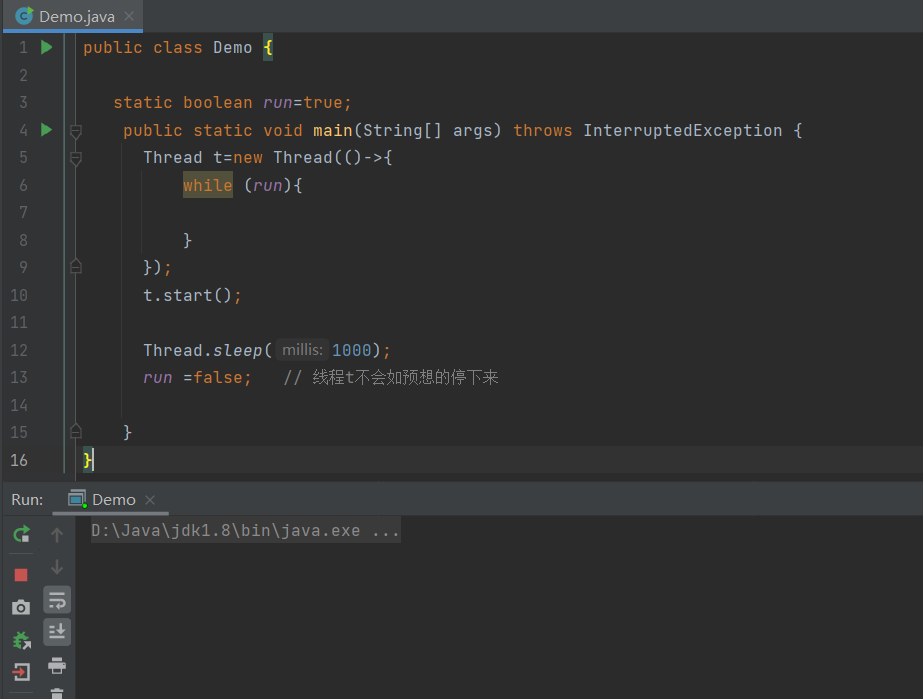
分析原因如下:
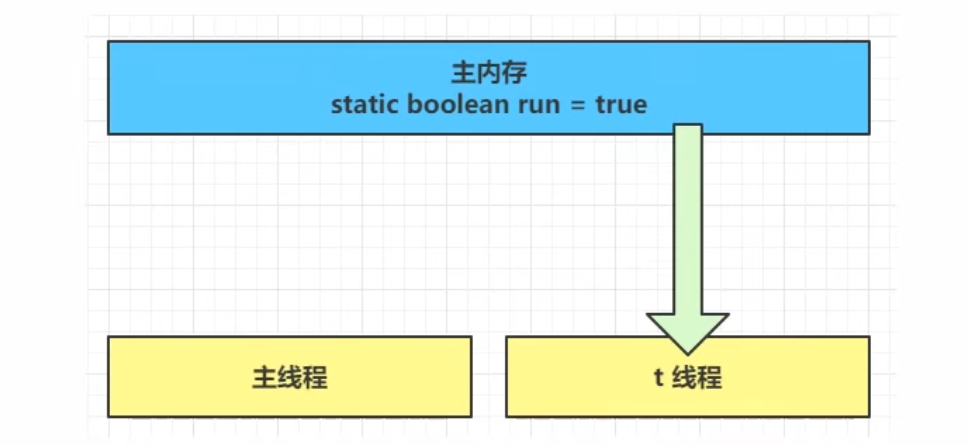
① 初始状态,t线程刚开始从主内存读取了run的值到工作内存
② 因为t线程要频繁从内存中读取run的值,JIT编译器会将run的值缓存至自己工作内存中的高速缓存中(做进一步优化),减少对主存中run的访问,提高效率
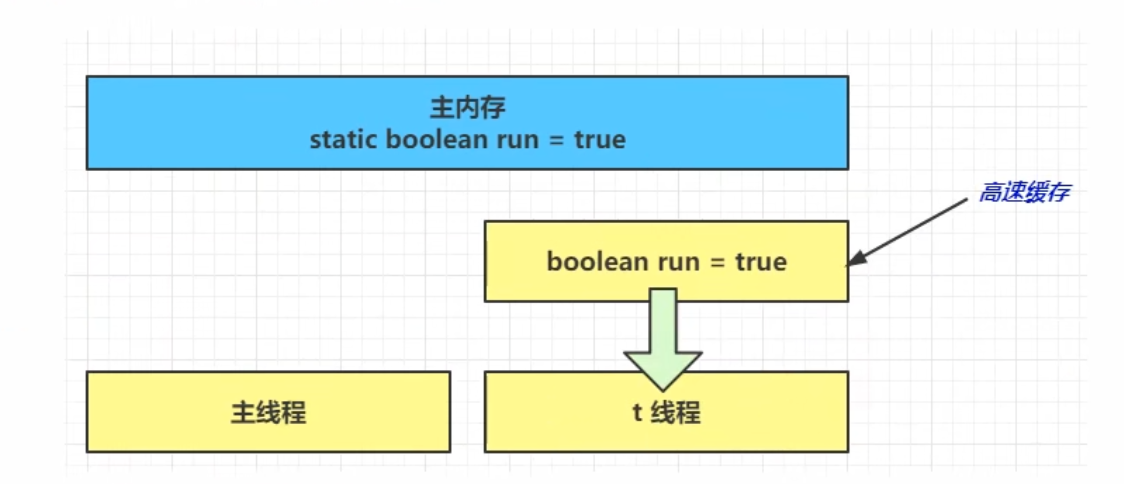
② 1秒之后,main线程修改了run的值,并同步至主存,而t是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
2.2 可见性——解决
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中的高速缓存中查找变量的值,必须到主存中获取它的值,线程操做volatile变量都是直接操作主存===>volatile修饰的变量每次都到主存中读取
2.3 可见性
上述例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对volatile 变量的修改对另一个线程可见,不能保证原子性,仅用在一个写线程, 多个读线程的情况:
上例从字节码理解是这样的:

加上volatile关键字后,程序运行1s后便可结束
比较之前线程安全时所举的例子:两个线程一个i++一个i–(不可保证原子性)
注意:synchronized语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是synchronized是属于重量级操作,性能相对更低
如果在前面示例的死循环中加入System. out.printla()会发现即使不加volatile修饰符,线程t也能正确看到对run变量的修改了,原因是什么?
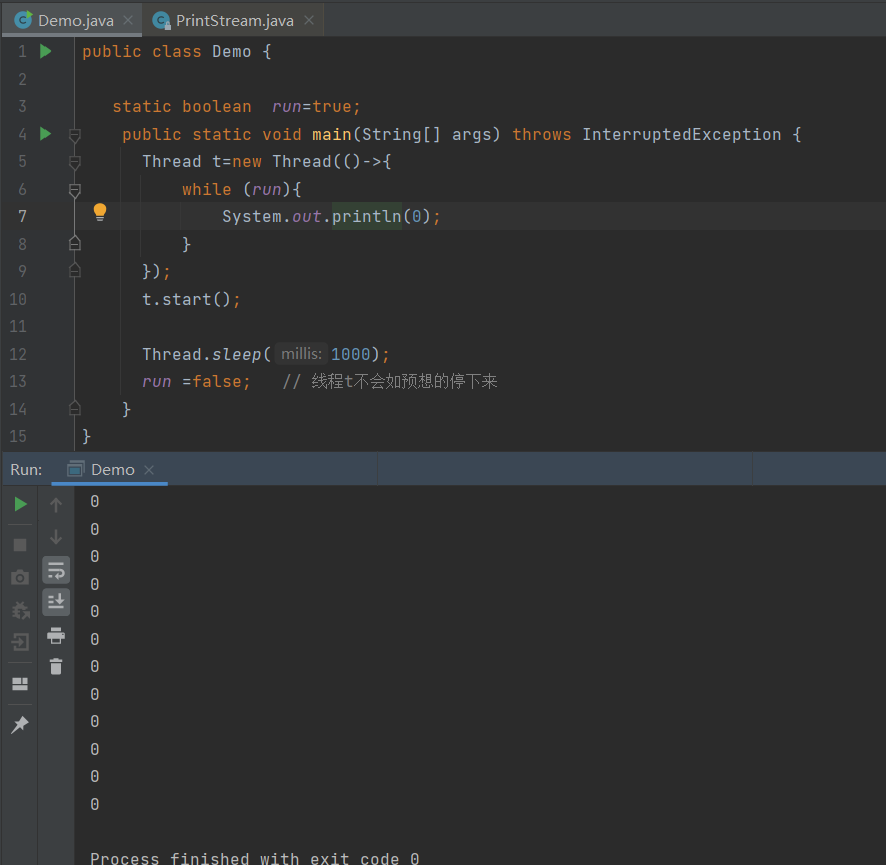
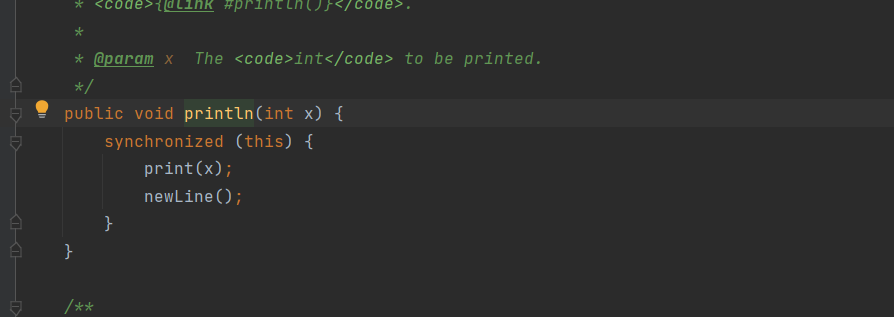
查看println()方法源码后发现具有synchronized关键字,要对当前打印输出流做同步
三、JMM——有序性-问题
3.1 诡异的结果
int num=0;
boolean ready=false;
// 线程1执行此方法
public void actor1(I_Result r){
if(ready){
r.r1=num+num;
}else {
r.r1=1;
}
}
// 线程2执行此方法
public void actor2(I_Result r){
num=2;
ready=true;
}
I Result是一个对象,有一个属性r1用来保存结果,问,可能的结果有几种?
情况1: 线程1先执行,这时ready= false,所以进入else 分支结果为1
情况2: 线程2先执行num=2,但没来得及执行ready= true,线程1执行,还是进入else分支,结果为1
情况3: 线程2执行到ready=true,线程1执行,这回进入if分支,结果为4 (因为num已经执行过了)
除以上情况,结果还有可能为0: 线程2执行ready=true(num=2的赋值有可能还没执行),切换到线程1,进入if分支,相加为0,再切回线程2执行num=2
这种现象在Java内存模型中称为指令重排,是JIT编译器在运行时的一些优化,这个现象需要通过大量测试才能发现:可借助java并发压测工具jcstresshttps://wiki.openjdk.java.net/display/CodeTools/jcstress
3.2 解决方法
volatile修饰的变量,可以禁用指令重排
3.3 有序性理解
同一个线程内,JVM会在不影响正确性的前提下,可以调整语句的执行顺序,思考以下代码
static int i
static int j
// 在某个线程内执行如下赋值操作
i = ...; // 较为耗时的操作(假如i的赋值可能需要做一些计算)
j = ...;
假如i的赋值可能需要做一些计算,j的可能马上会运算完毕;这种情况下JVM会对指令进行调整。因此以上操作无论是先执行i还是先执行j,对最终的结果不会产生影响。所以,上面代码真正执行时,即可以是
i = ...; // 较为耗时的操作
j = ...;
也可以是
j = ...;
i = ...; // 较为耗时的操作
这种特性称之为【指令重排】,多线程下指令重排会影响正确性,例如著名的double-checked locking模式实现单例
实现要点:单例类且为懒惰初始化===>单例是否创建,若没有创建则new单例对象;若已创建,则直接拿到上次已创建好的单例对象(为实现懒惰初始化也应考虑线程安全问题)
public final class Singleton {
private Singleton() {
}
private static Singleton INSTANCE = null;
public static Singleton getINSTANCE() {
// 实例没创建,才会进入内部的synchronized代码块
if (INSTANCE == null){
synchronized (Singleton.class){
//也许有其他线程已经创建实例,所以再判断一次
if (INSTANCE == null){
INSTANCE=new Singleton();
}
}
}
return INSTANCE;
}
}
以上的实现特点:
● 懒惰实例化
● 首次使用getINSTANCE()才使用synchronized加锁,后续使用无需加锁
但在多线程下,上面的代码存在问题(发生指令重排), INSTANCE=new Singleton();对应的字节码为:

其中4、7两个步骤时不固定的,也许jvm会优化为:先将引用地址赋值给INSTANCE变量后,再执行构造方法,如果两个线程t1、t2按如下时间顺序执行:

这时t1还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么t2拿到的将是一个未初始化完毕的单例
对INSTANCE使用volatile修饰即可,可以禁用指令重排,但要注意JDK5以上版本的volatile才会真正有效
3.4 happens-before
happens-before规定了哪些写操作对其他线程的读操作可见,他是可见性与有序性的一套规则总结:
● 线程解锁m之前对变量的锁,对于接下来对m加锁的其他线程对该变量的读可见
static int i=0;
static Object obj=new Object();
new Thread(()->{
synchronized (m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized (m) {
System.out.println(x);
}
},"t2").start();
● 线程对volatile变量的写,对接下来其他线程对该变量的读可见
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
● 线程start前对变量的写,对该线程开始后对该变量的读可见
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
● 线程结束前对变量的写,对其他线程得知它结束后的读可见(比如其他线程调用t1.isAlive()或t1.join()等待它结束)
static int x;
Thread t1=new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join() // 主线程调用t1.join()等待t1结束
System.out.println(x);
● 线程t1打断t2(interrupt)前对变量的写,对于其他线程得知t2被打断后对变量的读可见(通过t2.interrupt或t2.isInterrupted)
public final class JMM {
static int x;
public static void main(String[] args) throws InterruptedException {
Thread t2 = new Thread(() -> {
while (true) {
// 与主线程类似,在被打断后继续循环,并不会影响线程的继续运行(设置一个线程的打断标记)
// 被打断后下次再进入循环条件成立
if (Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
}, "t2");
t2.start();
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// x的写操作是在打断前写的,因此得知它打断后再读取x的值必定可以拿到x最新的结果
x = 10;
// 打断t2线程(1s后)
t2.interrupt();
}, "t1").start();
// 主线程不断循环,观察t2是否被打断
while (!t2.isInterrupted()) {
// 若未打断则一直循环
Thread.yield();
}
System.out.println(x);
}
}
● 对变量默认值(0,false,null)的写,对其他线程对该变量的读可见
● 具有传递性,如果x hb->y并且y hb->z那么有x hb->z
变量都是指成员变量或静态成员变量