文章目录
- 【半监督医学图像分割 2022 MICCAI】CLLE 论文翻译
- 摘要
- 1. 简介
- 2. 方法
- 2.1 半监督框架概述
- 2.2 监督局部对比学习
- 2.3 下采样和块划分
- 3. 实验
- 4. 结论
【半监督医学图像分割 2022 MICCAI】CLLE 论文翻译
论文题目:Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
中文题目:基于半监督对比学习的医学图像标签高效分割
论文链接:https://arxiv.org/abs/2109.07407
论文代码:https://github.com/xhu248/semi_cotrast_seg
发表时间:2021年9月
论文团队:美国圣母大学&广东省人民医院
引用:Hu X, Zeng D, Xu X, et al. Semi-supervised contrastive learning for label-efficient medical image segmentation[C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part II 24. Springer International Publishing, 2021: 481-490.
引用数:40(截止时间:2023年1月27号)
摘要
摘要深度学习方法在医学图像分割任务中的成功与否,很大程度上依赖于大量标注数据的监督训练。
另一方面,生物医学图像的注释需要领域知识,可能是费力的。
近年来,对比学习在学习图像的潜在表征方面表现出了巨大的潜力。
现有的工作已经探索了它在生物医学图像分割中的应用,其中只有一小部分数据被标记,通过基于自我监督对比学习的训练前阶段,不使用任何标签,然后只对标记的部分数据进行监督微调阶段。
在本文中,我们建立了通过在训练前阶段包含有限的标签信息,可以提高对比学习的性能。
我们提出了一种有监督的局部对比损失,利用有限的像素级注释来迫使具有相同标签的像素聚集在嵌入空间周围。这样的损耗需要像素级的计算,对于大的图像来说,这可能是昂贵的,我们进一步提出了两种策略,下采样和块划分,以解决这个问题。
我们评估了我们的方法在两个公共生物医学图像数据集的不同模式。对于不同数量的标记数据,我们的方法始终优于最先进的基于对比的方法和其他半监督学习技术
1. 简介
准确的语义分割结果对医学应用具有重要价值,为医生提供疾病诊断和治疗的解剖结构信息。
随着卷积神经网络的出现,有监督深度学习在许多生物医学图像分割任务中取得了最先进的性能,包括不同的器官和不同的模式[6,13,15,16]。
这些方法都需要大量已知像素或体素类的标记数据来指导训练。
然而,很难收集密集标记的医学图像,因为标记医学图像需要特定领域的知识,像素级的注释可能很耗时
为了解决这个问题,人们提出了各种各样的方法。其中一个分支是数据增强,它通过生成对抗网络(generative adversarial networks, GAN)[9]进行数据合成[3,5,8]或通过简单的线性组合[18]对标记数据集进行扩展。
但是,由于人工生成的图像和标签的缺陷,数据扩增只能对分割性能的提高起到有限的作用。
作为一种更好的替代方法,基于半监督学习的方法[2,12,14,19]可以有效地利用标记数据和未标记数据。
近年来,对比学习[7,10]在自监督分类问题上取得了最新的进展,它通过将相似图像的嵌入特征在潜在空间内强制接近,而将不同图像的嵌入特征隔离开来。
从无标签数据中提取对下游任务有用的特征的强大能力使其成为标签高效学习的一个很好的候选者。
而,现有的对比学习方法大多以图像分类为目标。
另一方面,语义分割需要像素级的分类。[4, 17]首次尝试在只标记部分数据时使用对比学习来提高分割的准确性。对于[4],采用两步自监督对比学习方案,在训练前阶段从无标记数据中学习全局和局部特征。
具体来说,它首先用编码器路径将2D切片投影到潜在空间,并计算全局对比度损失,类似于用于图像分类问题的方法。
然后在训练好的编码器的基础上加入解码器块,并利用中间特征映射进行像素级的局部对比学习。
在特征图的固定位置上只选择少量的点。
接下来,在微调阶段,在对数据标注部分的监督下,对来自对比学习的预训练模型进行训练。
在这样的框架中,标签信息从未在训练前阶段使用。然而从直觉上来说,通过包含这些信息来提供一定的监督,通过对比学习可以更好地提取特征。
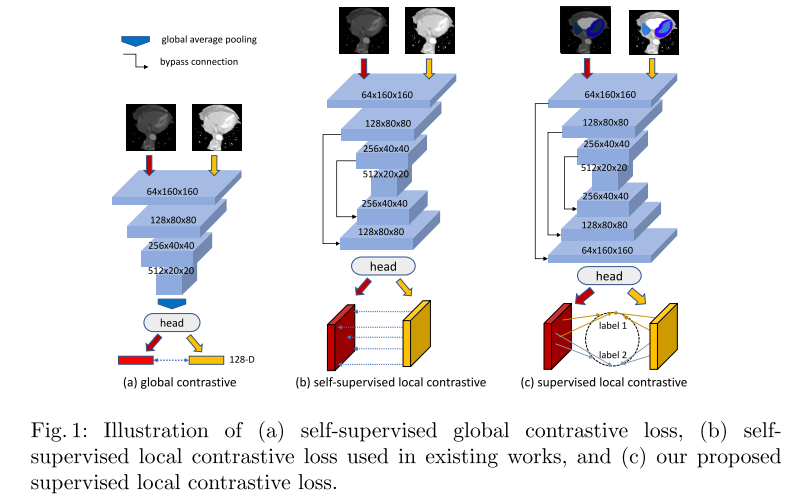
遵循这一理念,在本工作中,我们提出了一个由自我监督的全局对比和监督的局部对比组成的半监督框架,以利用可用的标签。
与文献中的无监督局部对比相比,有监督局部对比能更好地增强同一类内特征之间的相似性,并能区分不具有监督局部对比的特征。
此外,我们采用了下采样和块分割两种策略来解决由于监督局部对比度损失而带来的高计算复杂度。
我们对两个不同模式的公共医学图像分割数据集进行了实验。我们发现,对于不同数量的标记数据,我们的框架总能产生比最先进的方法更高的分割结果。
2. 方法
2.1 半监督框架概述
深度分割网络的结构骨干通常由编码器E和解码器d两部分组成。编码器包括几个下采样块,用于从输入图像中提取特征,解码器路径部署多个上采样块,以恢复像素级预测的分辨率。
在训练前阶段,我们的框架包含一个自我监督的全局对比学习步骤,该步骤只使用未标记的数据来训练E并捕获图像级特征,然后是一个监督的局部对比学习步骤,该步骤使用有限的标记数据来进一步训练E和D并捕获像素级特征。
整体对比学习类似于文献中使用的方法(如SimCLR[7]),为了完整起见,我们在这里通过图1(a)中的插图对其进行了简要描述。给定一个输入批B = {x1, x2,…, xb},其中xi表示一个输入2D切片,对B中的每幅图像随机进行两次图像变换组合aug(·),形成一对增广图像,与现有的对比学习方法相同。这些增广图像构成一个增广图像集a。设ai, i∈i ={1…2b}表示A中的一个增广图像,设j(i)为A中另一个图像的索引,该图像由B中ai的同一张图像衍生而来,即ai和aj(i)是一个增广对。整体对比损失则表现为以下形式
L
g
=
−
1
∣
A
∣
∑
i
∈
I
log
e
x
p
(
z
i
⋅
z
j
(
i
)
/
τ
)
∑
k
∈
I
−
{
i
}
e
x
p
(
(
z
i
⋅
z
k
)
/
τ
)
L_g=-\frac{1}{|A|}\sum_{i\in I}\log \frac{exp(z_i\cdot z_{j(i)}/\tau)}{\sum_{k\in I-\{i\}}exp((z_i\cdot z_k)/\tau)}
Lg=−∣A∣1i∈I∑log∑k∈I−{i}exp((zi⋅zk)/τ)exp(zi⋅zj(i)/τ)
其中,
z
i
z_i
zi是归一化的输出特征,在编码E中增加了头部h1(·)。头部通常是一个多层感知器,增强了从E中提取特征的表示能力。
τ
\tau
τ是温度常数。仅仅教编码器提取图像级的特征是不够的,因为分割需要预测输入图像中的所有像素。在完成全局对比学习后,我们将译码器路径D附加到编码器上,并使用监督局部对比损耗对整个网络进行再训练。这就是我们的工作与现有工作的不同之处,详细情况将在下一节中描述。两步预训练阶段最终会生成一个模型,用于后续对标注数据的微调阶段的初始化,以提高分割的准确性。
2.2 监督局部对比学习
局部对比学习的目标是训练解码器提取有特色的局部表示。设fl(xi) = h2(Dl(E(ai))是增强输入ai的第l个最上层解码器块Dl的输出特征映射,其中h2是一个两层逐点卷积。对于feature map f(ai),局部对比损耗定义为
l
o
s
s
(
a
i
)
=
−
1
∣
Ω
∣
∑
(
u
,
v
)
∈
Ω
1
∣
P
(
u
,
v
)
∣
log
∑
u
p
,
v
p
∈
P
(
u
,
v
)
e
x
p
(
f
u
,
v
l
⋅
f
u
p
,
v
p
l
/
τ
)
∑
u
′
,
v
′
∈
N
(
u
,
v
)
e
x
p
(
f
u
,
v
l
⋅
f
u
′
,
v
′
l
/
τ
)
loss(a_i)=-\frac{1}{|\Omega|}\sum_{(u,v)\in \Omega}\frac{1}{|P(u,v)|}\log \frac{\sum_{u_p,v_p}\in P(u,v)exp(f^l_{u,v}\cdot f^l_{u_p,v_p}/\tau)}{\sum_{u^\prime,v^\prime}\in N(u,v)exp(f^l_{u,v}\cdot f^l_{u^\prime,v^\prime}/\tau)}
loss(ai)=−∣Ω∣1(u,v)∈Ω∑∣P(u,v)∣1log∑u′,v′∈N(u,v)exp(fu,vl⋅fu′,v′l/τ)∑up,vp∈P(u,v)exp(fu,vl⋅fup,vpl/τ)
f
u
,
v
l
∈
R
c
f_{u,v}^l\in R^c
fu,vl∈Rc,其中c为通道号,表示特征图的第uth列和第vth行特征。Ω是
f
u
,
v
f_{u,v}
fu,v中用来计算损失的点的集合。P(u, v)和N(u, v)分别表示fu,v(ai)的正集和负集。则整体局部对比损失为
L
l
=
1
∣
A
∣
∑
a
i
∈
A
l
o
s
s
(
a
i
)
L_l=\frac{1}{|A|}\sum_{a_i\in A}loss(a_i)
Ll=∣A∣1ai∈A∑loss(ai)
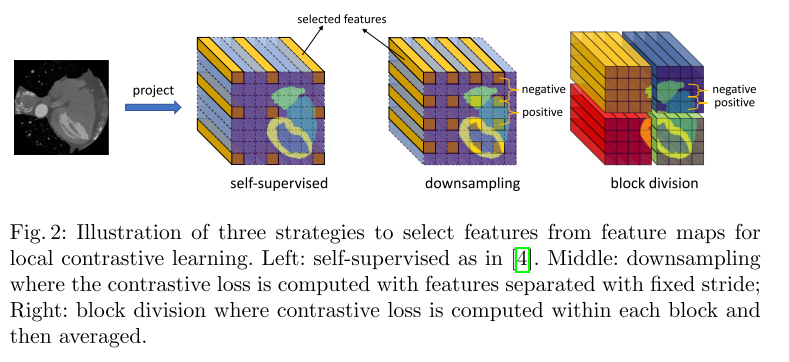
在自监督设置下,[4]仅从feature map中选取9或13个点,如图2(b)所示。在没有标注信息的情况下,P(u, v)只包含在成对图像的特征图上来自同一位置的点,即fu,v(aj(i)),负集为A中所有图像Ω减去正集的并集。
SimCLR认为,将对比学习应用于图像分类任务时,提高精度最大的数据增强是空间变换,如crop和cutout。而在自监督设置中,变换aug(·)只能包含颜色畸变、高斯噪声、高斯模糊等强度变换。这是因为经过空间变换后,f(ai)和f(aj(i))相同位置的特征可能来自不同的点或区域,但在计算(2)时仍然被视为相似。而且,在没有任何监督的情况下,Ω中选择的点可能都对应于背景区域,这样模型就不能有效地学习局部特征。
受[11]的启发,由于数据集包含有限的标记数据,无论如何都可以在微调阶段使用,我们可以通过监督局部对比学习在训练前阶段使用它。
观察到U-Net函数的最后一个逐点卷积类似于分类网络的全连通层,我们将1x1卷积层之前的特征映射 f 1 ∈ R c × h × h f^1\in R^{c\times h\times h} f1∈Rc×h×h视为所有像素对潜空间的投影,其中c等于通道数,也是潜空间的维数,h为输入图像维数。给定特征映射中的点(u, v),正集P(u, v)的定义是指a的特征映射中所有与(u, v)具有相同注释的特征,负集则是指a的特征映射中被标记为不同类别的所有特征。
另外,背景像素的两个嵌入特征构成了大部分的正对,比较这两个特征对对后的分割任务受益较少。因此,对于监督设置,我们将Ω的定义更改为只包含带有非背景注释的点。请注意,背景像素仍然包含在负集合N(u, v)中。监督对比度损失的形式与(2)相同,除了上面讨论的Ω,P(u, v),N(u, v)的新含义之外。在标签的指导下,监督对比丢失提供了来自同一类的特征的相似度和类间特征的不相似度的附加信息。
2.3 下采样和块划分
当我们尝试利用分割标注时,feature map的大小与输入图像相同。虽然我们只考虑不属于背景的点,但|p (u, v)|仍然可以非常大,即O(h2),输入图像维数h × h,则叠加局部对比度损失的总体计算复杂度为O(h4)。
例如“MMWHS”中的镜像大小为“512×512”。甚至在我们将切片重塑为160×160之后,负集的大小大约是104,计算损失所需的总乘法大约是108。为了解决这个问题,我们提出了两种策略来减少负集的大小,如图2所示。
第一种方法是对feature map进行固定步幅下样。该方法的思想是邻近像素包含冗余信息,它们的嵌入特征在潜在空间中看起来非常相似。
随着步数s的增加,P(u, v)的大小和损失函数的计算复杂度分别降低了s2和s4的1 / 4。
因为较大的步幅会导致较少的负对,而负对的数量对于对比学习很重要[10]。 在这项工作中,我们将步幅设置为4,这是在我们的实验平台上不会导致内存不足(OOM)问题的最小值。
3. 实验
数据集和预处理。我们评估了我们的方法在两个公共医学图像分割数据集的不同模式,MRI和CT。(1)海马数据集来自MICCAI 2018医学分段十项全能挑战赛[1]。260个单模态MRI三维扫描体,具有前、后海马体的标注。(2) MMWHS[20]来自MICCAI 2017挑战赛,包含20个3D心脏CT容积。该标注包括心脏的7个结构:左心室、左心房、右心室、右心房、心肌、升主动脉、肺动脉。在预处理方面,我们将整个体积的强度归一化。然后我们调整同一数据集中所有卷的切片大小,使用双线性插值将它们统一起来。两个重塑数据集的分辨率为64×64, MMWHS为160 × 160。
实验设置。与[4]类似,我们选择的分割网络骨干网是2D U-Net,编码器和解码器路径都有三个块,实现基于PyTorch库。对于这两个集合,我们将数据分为三个部分,训练集Xtr,验证集xl和测试集Xts。海马的|Xtr|: |Xvl|: |Xts|的比例为3:1:1,MMWHS的比例为2:1:1。
然后在Xtr中随机选取一定数量的样本作为标记体积,其余的视为未标记体积。我们将数据集分割了4次以生成4个不同的折叠,并使用Xts上的平均骰子分数作为比较的指标。
我们选择Adam作为对比学习和接下来的分割训练的优化器。对比学习的学习率为0.0001,分割训练的学习率为0.00001。对比学习的训练纪元为70,分割训练的训练纪元为120。海马数据集和MMWHS数据集分别在两台NVIDIA GTX 1080和Tesla P100上进行了实验。
我们实现了该方法的四个变体:两步全局对比度和下采样监督局部对比度(global+local(stride))和块划分(global+local(block));而对于消融研究而言,这两种方法均无全局对比(local(stride)和local(block))。
为了进行比较,我们实现了两种最新的基于对比的方法:全局对比学习方法7和自我监督全局和局部对比学习方法[4](global + local(self))。请注意,我们使用了整个训练数据,但没有任何标签用于全局对比和自我监督的局部对比,而只有标记的训练数据用于我们的监督的局部对比。
我们进一步实现了三种无对比基线方法:随机初始化从头开始训练(random)、基于数据增强的方法Mixup[18]和最先进的半监督学习方法TCSM[14]。
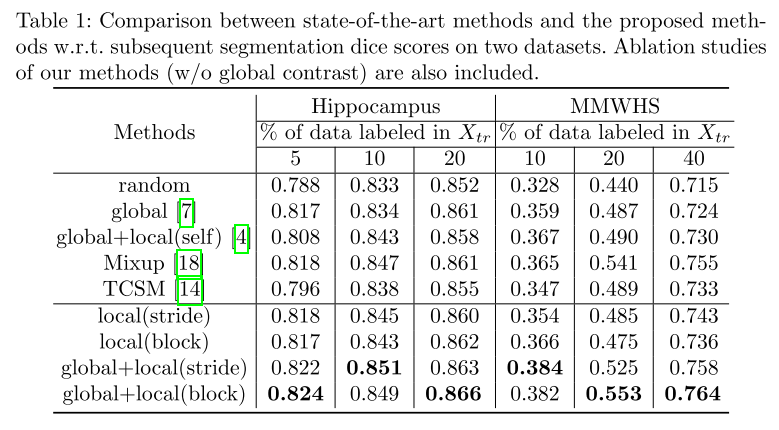
表1列出了所有方法的平均骰子分数。首先,与随机方法相比,所有对比学习方法都能获得更高的骰子分数,这意味着当标签有限时,对比学习是一个可行的初始化方法。
其次,我们注意到,提出的监督局部对比度单独(local(stride)和local(block))产生的分割结果与现有的基于对比度的方法相比较。
考虑到前者只使用标记数据,而后者利用所有卷,监督对比损耗有效地教会模型由相同类共享的像素级表示。
最后,将有监督的局部对比度和全局对比度相结合,半有监督的分割效果比目前的算法有了很大的提高。
结果表明,无监督全局对比度提取的图像级表示与有监督局部对比度提取的像素级表示是互补的。
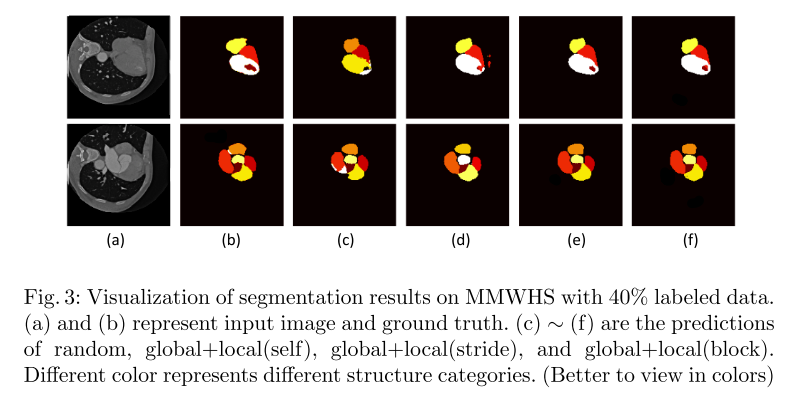
最后,我们的方法、最先进的(global+local(self)[4])和随机方法在带有40%标记数据的MMWHS上的分割结果如图3所示。从图中我们可以清楚地看到,我们的方法表现最好。
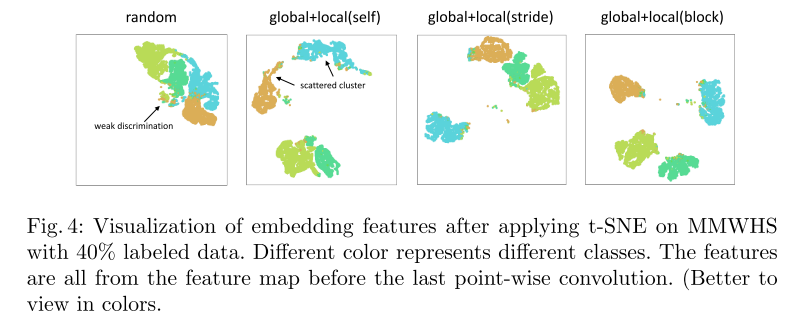
在相同的设置下,这些方法应用t-SNE后的嵌入特征如图4所示。从图中我们可以看出,与random方法相比,global+local(block)方法对于同一类的特征是紧密聚类的,对于不同类的特征是明显分开的,而最先进的方法则更加分散。这与表1中的结果一致,其中global+local(block)方法获得了最高的Dice(最右边的一列)。
4. 结论
有限的标注一直是深度学习医学图像分割方法发展的障碍。针对这一挑战,在本研究中,我们提出了一种监督局部对比损失来学习像素级的表示。在此基础上,提出了两种降低损失计算复杂度的策略。在两个只有部分标签的公共医学图像数据集上进行的实验表明,当将提出的监督局部对比度与全局对比度相结合时,得到的半监督对比学习在最先进的图像分割性能上得到了显著改善。










![[oeasy]python0083_十进制数如何存入计算机_八卦纪事_BCD编码_Binary_Coded_Decimal](https://img-blog.csdnimg.cn/img_convert/e194124de5ee4b1b66804238a379c7bb.png)