目录
一、项目背景
二、项目需求分析
三、项目涉及的知识点
四、项目实现的基础理论
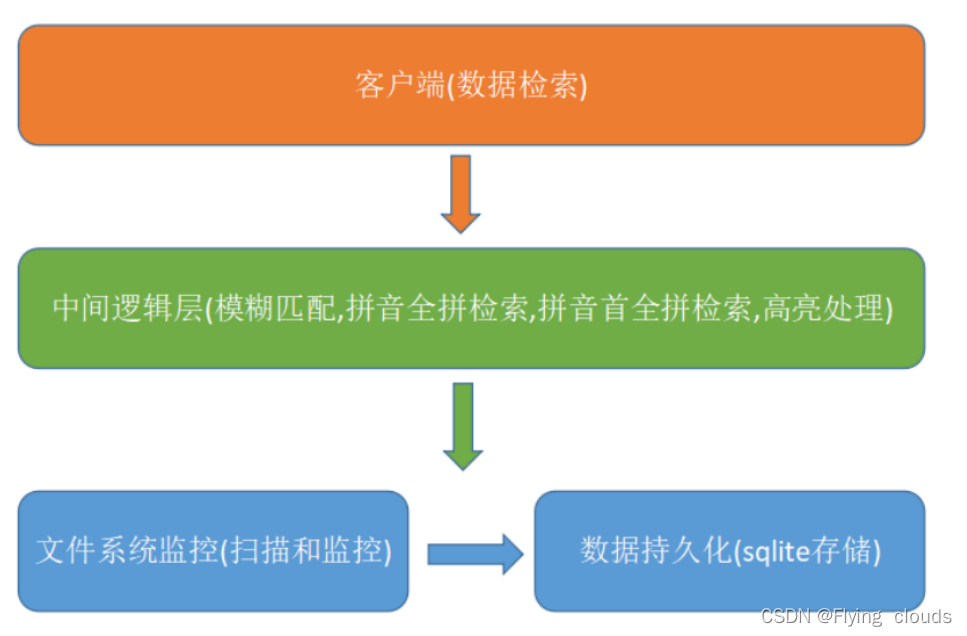
五、项目框架
六、增加系统工具模块
6.1、扫描本地的文件的功能
七、增加数据管理模块
7.1、先了解数据库sqlite
7.2 封装sqlite数据库管理类
7.3、封装数据管理类
7.3.1增加搜索功能
7.3.2 利用RAII机制解决表结果的自动释放
八、新增扫描模块
8.1、同步函数,同步数据库和本地
8.2、新增实时扫描功能
8.3 扫描管理类的单例化
九、对sqlite进行静态链接库的使用
1、生成静态链接库
2、使用生成静态链接库
十、新增监控模块
2、在扫描管理类中添加互斥量和条件变量
3、升级扫描线程和监控线程
十一、中间逻辑层实现
1、实现拼音全拼和首字母的搜索
2、实现高亮搜索
2.1 实现高亮搜索的关键是实现分割函数
十二、客户端的实现
项目中遇到的问题:
对比Everything
一、项目背景


所以我就想着能不能自己来写一个快速搜索工具呢?
二、项目需求分析
-
1、支持文档的常规搜索
-
2、支持拼音全拼搜索
-
3、支持拼音首字母搜索
-
4、支持搜索关键字高亮显示
-
5、扫描和监控(用户感知不到)
三、项目涉及的知识点
四、项目实现的基础理论

五、项目框架
六、增加系统工具模块
sysutil.h 和 sysutil.cpp
6.1、扫描本地的文件的功能
这个函数最终的功能是希望能把遍历的目录给保存下来(保存到数据库中)
能够扫描本地的文件首先要知道一些系统的函数:
//功能是搜索与指定的文件名称匹配的第一个实例,若成功则返回第一个实例的句柄,否则返回-1L
long _findfirst( char *filespec, struct _finddata_t *fileinfo );
//_findnext函数提供搜索文件名称匹配的下一个实例,若成功则返回0,否则返回-1
int _findnext( long handle, struct _finddata_t *fileinfo );
//_findclose用于释放由_findfirst分配的内存,可以停止一个_findfirst/_findnext序列
int _findclose( long handle );//系统工具 -- 体现为函数
void DirectionList(const string& path, vector<string>& sub_dir, vector<string>& sub_file)
{
struct _finddata_t file;
//"C:\\Users\\86188\\Desktop\\项目1\\项目—文档快速搜索工具\\TestDoc"
string _path = path;
//"C:\\Users\\86188\\Desktop\\项目1\\项目—文档快速搜索工具\\TestDoc"
_path += "\\*.*";
long handle = _findfirst(_path.c_str(), &file);
if (handle == -1)
{
//printf("扫描目录失败.\n");
ERROR_LOG("扫描目录失败");
return;
}
do
{
if (file.name[0] == '.')
continue;
//cout<<file.name<<endl;
if (file.attrib & _A_SUBDIR)
sub_dir.push_back(file.name);
else
sub_file.push_back(file.name);
if (file.attrib & _A_SUBDIR)
{
//文件为目录(文件夹)
//"C:\\Users\\86188\\Desktop\\项目1\\项目—文档快速搜索工具\\TestDoc"
string tmp_path = path;
//"C:\\Users\\86188\\Desktop\\项目1\\项目—文档快速搜索工具\\TestDoc"
tmp_path += "\\";
//"C:\\Users\\86188\\Desktop\\项目1\\项目—文档快速搜索工具\\TestDoc"
tmp_path += file.name;
//目录递归遍历
DirectionList(tmp_path, sub_dir, sub_file);
}
} while (_findnext(handle, &file) == 0);
_findclose(handle);
}七、增加数据管理模块
7.1、先了解数据库sqlite
SQlite简介
- 不需要一个单独的服务器进程或操作的系统(无服务器的)。
- SQLite 不需要配置,这意味着不需要安装或管理。(使用简单)
- 一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件。
- SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配- 置时小于250KiB。
- SQLite 是自给自足的,这意味着不需要任何外部的依赖。
- SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
- SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。
- SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。
//打开数据库
int sqlite3_open(const char *filename, sqlite3 **ppDb);
//关闭
int sqlite3_close(sqlite3*);
//执行操作 后面的创建表,插入数据其实就是把sql的内容换了而已
int sqlite3_exec(sqlite3*, const char *sql, sqlite_callback,
void *data, char **errmsg);
int sqlite3_get_table(
sqlite3 *db, /* An open database */
const char *zSql, /* SQL to be evaluated */
char ***pazResult, /* Results of the query */
int *pnRow, /* Number of result rows written here */
int *pnColumn, /* Number of result columns written here */
char **pzErrmsg /* Error msg written here */
);
void sqlite3_free_table(char **result);
有了这些函数,我们就可以把这些函数封装成一个类 SqliteManager
7.2 封装sqlite数据库管理类
//封装数据库sqlite
class SqliteManager
{
public:
SqliteManager();
~SqliteManager();
public:
void Open(const string& database); //打开或者创建一个数据库
void Close(); //关闭数据库
void ExecuteSq1(const string& sql);//执行SQL 创建表,插入,删除都是通过执行sql语句
void GetResultTable(const string& sql, char**& ppRet, int& row, int& col);
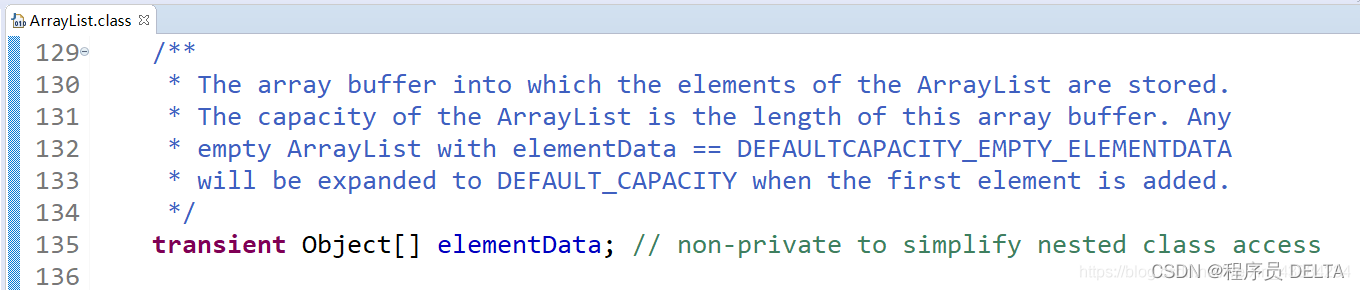
private:
sqlite3* m_db;
};SqliteManager::SqliteManager() :m_db(nullptr)
{}
SqliteManager::~SqliteManager()
{
Close();//关闭数据库
}
void SqliteManager::Open(const string& database)
{
int rc = sqlite3_open(database.c_str(), &m_db);
if (rc != SQLITE_OK)
{
//fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(m_db));
ERROR_LOG("Can't open database: %s\n", sqlite3_errmsg(m_db));
exit(1);
}
else
{
//fprintf(stderr, "Opened database successfully\n");
TRACE_LOG("Opened database successfully\n");
}
}
void SqliteManager::Close()
{
int rc = sqlite3_close(m_db);
if (rc != SQLITE_OK)
{
//fprintf(stderr, "Can't close database: %s\n", sqlite3_errmsg(m_db));
ERROR_LOG("Can't close database: %s\n", sqlite3_errmsg(m_db));
exit(1);
}
else
{
//fprintf(stderr, "Close database successfully\n");
TRACE_LOG("Close database successfully\n");
}
}
void SqliteManager::ExecuteSq1(const string& sql)
{
char* zErrMsg = 0;
int rc = sqlite3_exec(m_db, sql.c_str(), 0, 0, &zErrMsg);
if (rc != SQLITE_OK)
{
//fprintf(stderr, "SQL error: %s\n", zErrMsg);
ERROR_LOG("SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
//fprintf(stdout, "Operation sql successfully\n");
TRACE_LOG("Operation sql successfully\n");
}
}
void SqliteManager::GetResultTable(const string& sql, char**& ppRet, int& row, int& col)
{
char* zErrMsg = 0;
int rc = sqlite3_get_table(m_db, sql.c_str(), &ppRet, &row, &col, &zErrMsg);
if (rc != SQLITE_OK)
{
//fprintf(stderr, "SQL Error: %s\n", zErrMsg);
ERROR_LOG("SQL Error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
//fprintf(stdout, "Get Result table successfully\n");
TRACE_LOG("Get Result table successfully\n");
}
}
7.3、封装数据管理类
方便我们对数据库的操作,因为我们最后并不是要去对数据库进行操作,而是让本地文件和数据库的文件进行持续的对比,
确保本地文件和数据库的文件是同步的,也可以简单理解为我们并不直接去操作数据库
//封装数据管理类
class DataManager
{
public:
DataManager();
~DataManager();
public:
void InitSqlite(); //初始化数据库
void InsertDoc(const string &path, const string &doc);
void DeleteDoc(const string &path, const string &doc);
void GetDoc(const string &path, multiset<string> &docs);
private:
SqliteManager m_dbmgr;
};DataManager::DataManager()
{
m_dbmgr.Open(DOC_DB);
InitSqlite(); //创建表
}
DataManager::~DataManager()
{}
void DataManager::InitSqlite()
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "CREATE TABLE if not exists %s(\
id integer primary key autoincrement,\
doc_name text,\
doc_path text)", DOC_TB);
m_dbmgr.ExecuteSql(sql);
}
void DataManager::InsertDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "INSERT INTO %s values(null, '%s', '%s')",
DOC_TB, doc.c_str(), path.c_str());
m_dbmgr.ExecuteSql(sql);
}
void DataManager::DeleteDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "DELETE FROM %s where doc_path='%s' and doc_name='%s'",
DOC_TB, path.c_str(), doc.c_str());
m_dbmgr.ExecuteSql(sql);
}
void DataManager::GetDoc(const string &path, multiset<string> &docs)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "SELECT doc_name from %s where doc_path='%s'",
DOC_TB, path.c_str());
char **ppRet = 0;
int row = 0, col = 0;
m_dbmgr.GetResultTable(sql, ppRet, row, col);
for(int i=1; i<=row; ++i)
docs.insert(ppRet[i]);
//释放表结果
sqlite3_free_table(ppRet);
}7.3.1增加搜索功能
这里的搜索是用到了like模糊匹配
void DataManager::Search(const string &key, vector<pair<string,string>>
&doc_path)
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "SELECT doc_name, doc_path from %s where doc_name like
'%%%s%%'",
DOC_TB, key.c_str());
char **ppRet;
int row, col;
m_dbmgr.GetResultTable(sql, ppRet, row, col);
for(int i=1; i<=row; ++i)
{
doc_path.push_back(make_pair(ppRet[i*col], ppRet[i*col+1]));
}
sqlite3_free_table(ppRet);
}7.3.2 利用RAII机制解决表结果的自动释放
增加一个AutoGetResultTable类
我们会发现,在管理数据的时候,只要获取了表,就需要在最后面进行一步释放表结果的操作
我们万一忘记释放表结果就会导致内存泄漏,也就是说搜一次就会泄漏一次,如果搜的次数多的话,势必会导致内存资源被耗光
手动释放表结果还是有点麻烦的,而且我们也不能保证每次都记得去释放
所以我们就想着能不能让他自动的去释放呢?
这时候就想到了智能指针的思想
class AutoGetResultTable
{
public:
AutoGetResultTable(SqliteManager& db, const string& sql, char**& ppRet, int& row, int& col);
~AutoGetResultTable();
private:
SqliteManager& m_db;
char** m_ppRet;
};
AutoGetResultTable::AutoGetResultTable(SqliteManager& db, const string& sql,
char**& ppRet, int& row, int& col)
:m_db(db), m_ppRet(nullptr)
{
//获取数据库表的函数在数据库类中,所以必须要有一个数据库类对象才能去调
m_db.GetResultTable(sql, ppRet, row, col);
m_ppRet = ppRet;
}
AutoGetResultTable::~AutoGetResultTable()
{
if (m_ppRet)//如果这个指针不空的话,说明就需要进行释放
sqlite3_free_table(m_ppRet);
}
小小问题:我们在写这个类的时候怎么知道要传哪些参数呢?我们怎么知道要有哪些成员呢?
本身这个类就是要解决的释放空间,那么我们要是不把空间保存下来,拿什么去释放呢?所以在类中就把ppRet给保留了。
有了智能指针以后,获取表实现起来就简单了点

八、新增扫描模块
ScanManager.h 和 ScanManager.cpp
8.1、同步函数,同步数据库和本地
//同步本地数据和数据库数据
void ScanManger::ScanDirectory(const string& path)
{
//1 扫描本地文件
vector<string> local_dir;
vector<string> local_file;
DirectionList(path, local_dir, local_file);
multiset<string> local_set;
local_set.insert(local_file.begin(), local_file.end());
local_set.insert(local_dir.begin(), local_dir.end());
//2 扫描数据库文件
multiset<string> db_set;
DataManager& m_dbmgr = DataManager::GetInstance();//注意一定使用引用接收
m_dbmgr.GetDoc(path, db_set);
//3 同步数据
auto local_it = local_set.begin();
auto db_it = db_set.begin();
while (local_it != local_set.end() && db_it != db_set.end())
{
if (*local_it < *db_it)
{
//本地有,数据库没有,数据库插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
else if (*local_it > *db_it)
{
//本地没有,数据库有,数据库删除文件
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
else
{
//两者都有
++local_it;
++db_it;
}
}
while (local_it != local_set.end())
{
//本地有,数据库没有,数据库插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
while (db_it != db_set.end())
{
//本地没有,数据库有,数据库删除文件
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
}8.2、新增实时扫描功能
之前写的扫描是在搜索之前先进行了扫描,当程序跑起来之后,就无法再去同步数据库了,比如我们运行程序以后,这时候我们删除了一个文件,数据库是同步不了数据的,这就是个问题。我们要想同步就必须要把程序重启一下,这显然是不妥当的。
那有什么办法能实时的进行同步呢?
我们想要实时的进行一直扫描,就需要多线程的思想,让一个线程去专门扫描
在ScanManger的构造函数当中新增创建扫描线程
ScanManger::ScanManger(const string &path)
{
//扫描对象
thread ScanObj(&ScanManger::ScanThread,this,path);
ScanObj.detach();
}线程的函数就是一直在做着扫描的工作,当然一直在while(1)效率肯定不高,后面会使用条件变量来让扫描不那么盲目
void ScanManger::ScanThread(const string& path)
{
//这个线程就是一直在扫描
while (1)
{
ScanDirectory(path);
}
}8.3 扫描管理类的单例化
为什么要单例化?
因为我们的扫描是的时候是需要先去实例化一个对象,那么要是别人也实例化一个对象的话会怎么样呢?
比如:
那就可能再去创建线程去接着扫描,在这个程序之下,整个系统只需要产生一个对象就行了,多个对象进行扫描肯定是不好的,
而一个类只产生一个对象就是叫做单例化
我们这里使用的是懒汉模式:
class ScanManager
{
public:
static ScanManager& GetInstance(const string &path);
protected:
ScanManager(const string &path);
ScanManager(ScanManager &);
ScanManager& operator=(const ScanManager&);
private:
//DataManager m_dbmgr;
};ScanManager& ScanManager::GetInstance(const string &path)
{
static ScanManager _inst(path);
return _inst;
}九、对sqlite进行静态链接库的使用
1、生成静态链接库


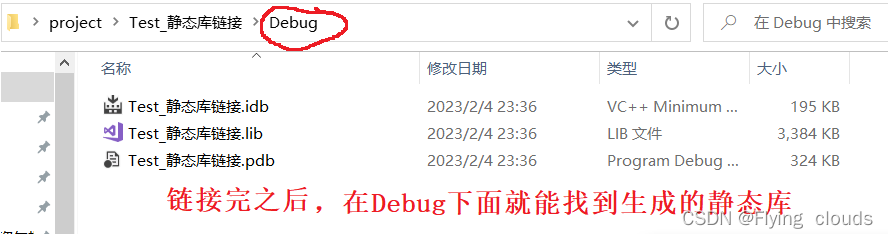
2、使用生成静态链接库

十、新增监控模块
只有扫描而没有监控的话,监控线程就会一直死循环的扫描,文件少的时候还没啥大问题,文件多的话麻烦就大了
我们应该再设置一个监控线程,当本地文件发生变化的时候再去通知扫描线程开始工作

#include<windows.h>
HANDLE FindFirstChangeNotification(
LPCTSTR lpPathName, // pointer to name of directory to watch
BOOL bWatchSubtree, // flag for monitoring directory or
// directory tree
DWORD dwNotifyFilter // filter conditions to watch for
);
BOOL FindNextChangeNotification(
HANDLE hChangeHandle // handle to change notification to signal
);
DWORD WaitForSingleObject(
HANDLE hHandle, // handle to object to wait for
DWORD dwMilliseconds // time-out interval in milliseconds
);2、在扫描管理类中添加互斥量和条件变量
#include<mutex>
#include<condition_variable>
class ScanManager
{
//...............
mutex m_mutex;
condition_variable m_cond;
};unique_lock<mutex> lock(m_mutex); 这个锁对象是构造函数加锁,析构函数解锁
3、升级扫描线程和监控线程
void ScanManger::ScanThread(const string& path)
{
//初始化扫描
ScanDirectory(path);//防止第一次扫描的时候数据库里没有东西
while (1)
{
unique_lock<mutex> lock(m_mutex);
m_cond.wait(lock); //条件阻塞等待,阻塞的时候不占CPU资源
ScanDirectory(path);
}
}void ScanManger::WatchThread(const string& path)
{
//true表示的是监控子目录
HANDLE hd = FindFirstChangeNotification(path.c_str(), true,
FILE_NOTIFY_CHANGE_FILE_NAME | FILE_NOTIFY_CHANGE_DIR_NAME);
if (hd == INVALID_HANDLE_VALUE)
{
//cout<<"监控目录失败."<<endl;
ERROR_LOG("监控目录失败.");
return;
}
while (1)//监控成功,监控到了就要通知别人
{
WaitForSingleObject(hd, INFINITE); //永不超时等待
m_cond.notify_one();//通知扫描线程去干活
FindNextChangeNotification(hd);//接下来继续监控
}
}十一、中间逻辑层实现
1、实现拼音全拼和首字母的搜索
//汉字转拼音
string ChineseConvertPinYinAllSpell(const string &dest_chinese);
//汉字转拼音首字母
string ChineseConvertPinYinInitials(const string &name);void DataManager::InitSqlite()
{
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "CREATE TABLE if not exists %s(\
id integer primary key autoincrement,\
doc_name text,\
doc_name_py text,\
doc_name_initials text,\
doc_path text)", DOC_TB);
m_dbmgr.ExecuteSql(sql);
}void DataManager::InsertDoc(const string &path, const string &doc)
{
//汉字转拼音
string doc_py = ChineseConvertPinYinAllSpell(doc);
//汉字转首字母
string doc_initials = ChineseConvertPinYinInitials(doc);
char sql[SQL_BUFFER_SIZE] = {0};
sprintf(sql, "INSERT INTO %s values(null, '%s', '%s','%s', '%s')",
DOC_TB, doc.c_str(), doc_py.c_str(), doc_initials.c_str(),
path.c_str());
m_dbmgr.ExecuteSql(sql);
}2、实现高亮搜索
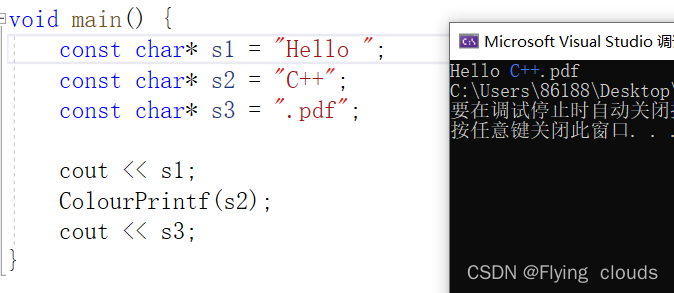
// 颜色高亮显示一段字符串
void ColourPrintf(const char* str)
{
// 0-黑 1-蓝 2-绿 3-浅绿 4-红 5-紫 6-黄 7-白 8-灰 9-淡蓝 10-淡绿
// 11-淡浅绿 12-淡红 13-淡紫 14-淡黄 15-亮白
//颜色:前景色 + 背景色*0x10
//例如:字是红色,背景色是白色,即 红色 + 亮白 = 4 + 15*0x10
WORD color = 9 + 0 * 0x10;
WORD colorOld;
HANDLE handle = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_SCREEN_BUFFER_INFO csbi;
GetConsoleScreenBufferInfo(handle, &csbi);
colorOld = csbi.wAttributes;
SetConsoleTextAttribute(handle, color);
printf("%s", str);
SetConsoleTextAttribute(handle, colorOld);
}2.1 实现高亮搜索的关键是实现分割函数


关键是原始字符串上怎么和py字符串上同步,这是个挑战



十二、客户端的实现


项目中遇到的问题:

但是我想的高亮就是应该是
 这种能让C++这个单独亮起来,别的颜色不变,这时候我就想着怎么能把这个字符串给分割开,就又去想自己写个函数去实现一下,后面边写边上网查,就发现原来有专门的高亮显示函数,就学习了一下这个函数并用上了
这种能让C++这个单独亮起来,别的颜色不变,这时候我就想着怎么能把这个字符串给分割开,就又去想自己写个函数去实现一下,后面边写边上网查,就发现原来有专门的高亮显示函数,就学习了一下这个函数并用上了
2、刚开始没想到要有监控线程
当时为了能够实现实时扫描的功能,我想到了要用创建出一个工作线程去专门扫描,但是这个时候做出来是一直while(1),死循环的去扫,开始的时候文件比较少,扫描速度比较快,知道会占CPU资源很多,但是因为好歹是结果对着的就没在意,后面测试的时候文件比较多之后便发现了问题:文件一多扫描一次就需要比较长的时间,而且确实很耗CPU资源,这就是个问题。
刚开始相的解决方案是一个线程慢的话能不能多几个线程去同时扫描数据库,把数据库分成几部分,每个线程负责一个小部分,但是实现的话是思考了一段时间没有成功,后面才想到,我们可以从本质上解决,不让线程一直无脑的扫描,这样时间就大大减少了,然后经过思考和尝试以及上网查资料。。。
后来才想到怎么能利用之前学过的使用懒汉思想,类似于写实拷贝的,就是当本地文件发生改变了扫描线程再去工作,不改变就一直原地等着,让出cpu资源,这时候就想到了条件变量,因为条件变量有通知的功能,从而想到了再创建一个专门监控的线程





![[oeasy]python0083_十进制数如何存入计算机_八卦纪事_BCD编码_Binary_Coded_Decimal](https://img-blog.csdnimg.cn/img_convert/e194124de5ee4b1b66804238a379c7bb.png)