一、NTP时间同步服务
1、NTP介绍
NTP服务器【Network Time Protocol(NTP)】是用来使计算机时间同步化的一种协议,它可以使计机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精准度的时间校正(LAN上与标间差小于1毫秒,WAN上几十毫秒),且可介由加密确认的方式来防止恶毒的协议攻击。时间按NTP服器的等级传播。按照离外部UTC源的远近把所有服务器归入不同的Stratum(层)中。
ntpd(Network Time Protocol daemon)是 Linux 操作系统的一个守护进程,用于校正本地系统与钟源服务器之间的时间,完整的实现了 NTP 协议。ntpd 与ntpdate 的区别是 ntpd 是步进式的逐渐校正时间,不会出现时间跳变,而 ntpdate是断点更新。
部分操作系统采用 chrony 作为默认 NTP 服务,请确认 ntpd 正在运行并设置为开机自启动。在CentOS8.0中默认不再支持ntp软件包,时间同步将由chrony来实现。
使用 systemctl is-active ntpd.service 命令,可查看 ntpd 是否正在运行。
使用 systemctl is-enabled ntpd.service 命令,可查看 ntpd 是否开机自启动。
NTP 服务的通信端口为 UDP 123,设置 NTP 服务之前,请确保您已经开放UDP 123 端口。
2、主要结构
(1) 时间来源
现在的标准时间是由原子钟报时的国际标准时间UTC(Universal Time Coordinated,世界协调时),所以NTP获得UTC的时间来源可以是原子钟、天文台、 卫星,也可以从Internet上获取。
(2) 传播
在NTP中,定义了时间按照服务器的等级传播,按照离外部UTC源远近将所有的服务 器归入不同的Stratum(层)中,例如把通过GPS取得发送标准时间的服务器叫 Stratum-1的NTP服务器,而Stratum-2则从Stratum-1获取时间,Stratum-3从 Stratum-2获取时间,以此类推,但Stratum层的总数限制在15以内。所有这些服务 器在逻辑上形成阶梯式的架构相互连接,而Stratum-1的时间服务器是整个系统的基 础,这种阶梯式的架构示意图如下图所示:
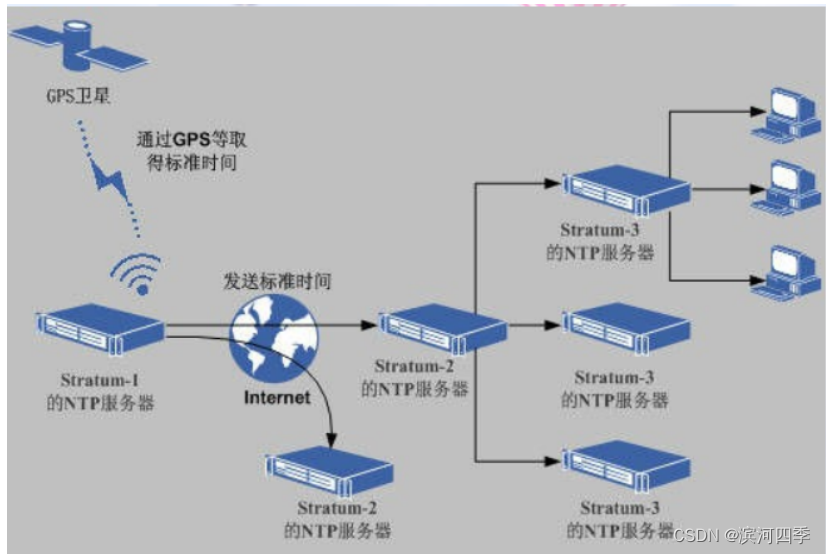
计算机主机一般同多个时钟服务器连接,利用统计学的算法过滤来自不同服务器的时 间,以选择最佳的路径和来源以便校正主机时间。即使在主机长时间无法与某一时钟 服务器联系的情况下,NTP服务依然可以有效运转。
3、架构和安装
架构
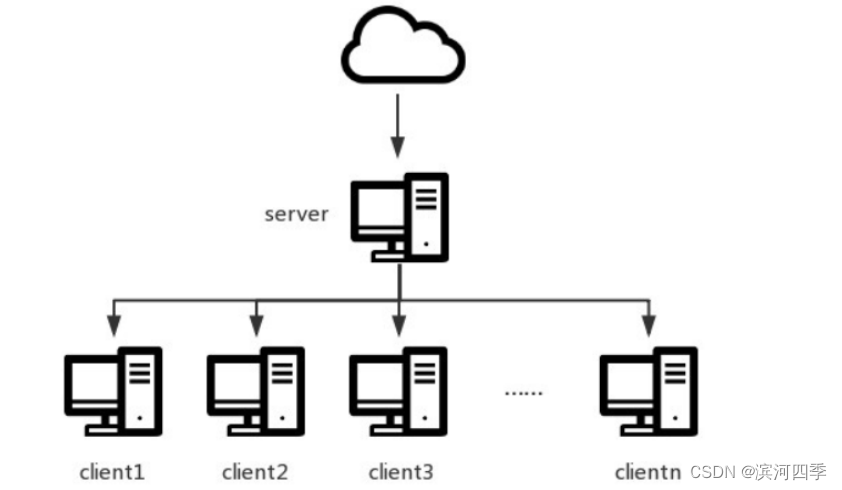
如上图所示,对于一些服务依赖于时间的集群(如hadoop集群),需要有一部主机 作为ntp服务器,其他客户端主机从这部主机进行时间同步,另外ntp服务主机从更 高一层的服务器获得时间信息。
安装配置
NTP服务主机规划
centos7.x 虚拟机两台
服务端:192.168.198.140
客户端: 192.168.198.138
服务端配置
服务端和客户端都分别按照ntp服务:
yum install –y ntp
查看是否安装成功:
rpm -qa |grep ntp
配置文件为: /etc/ntp.conf
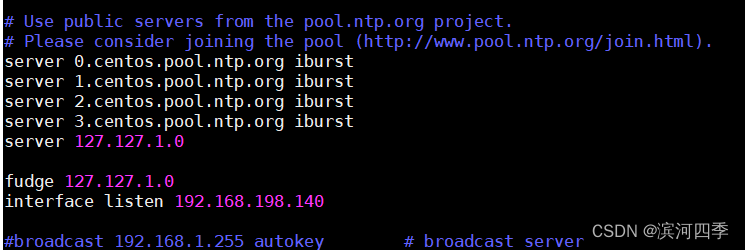
server 0.cn.pool.ntp.org iburst
server 1.asia.pool.ntp.org iburst #iburst 当一个远程NTP服务器不可用时,向他发送一系列的并发包进行检测
server 2.asia.pool.ntp.org iburst
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 #这行是时间服务器的层次。设为0则为顶级,如果要向别的NTP服务器更新时间,请不要把它设为0,最好设置的数字靠后
interface listen 192.168.198.140配置好后,需要重启服务

使用如下命令检查是否同步成功,如出现running表示运行,否则失败。

客户端配置
vim /etc/ntp.conf
这里的server指向服务器的IP,改完后重启服务
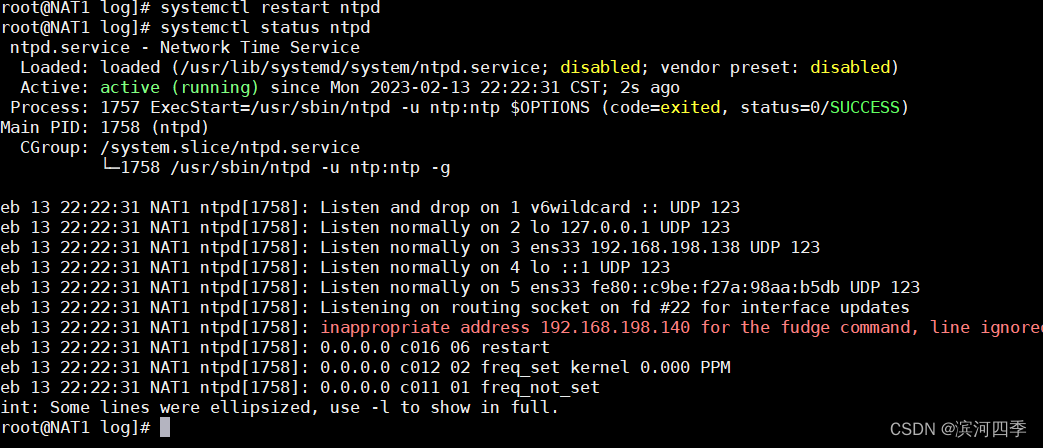
上面红色的那一行不影响使用;
ntp同步测试
【在进行所有ntp测试时最好关闭服务端的防火墙】
[root@NAT-139 ~]# iptables -F
[root@NAT-139 ~]# systemctl stop firewalld
[root@NAT-139 ~]# setenforce 0在服务器端执行ntpstat命令看下服务端同步上游服务器情况,这个命令需要等待2-3分钟
当状态由unsynchronised变为synchronised代表同步上游服务器成功,此过程需要 几分钟时间 。
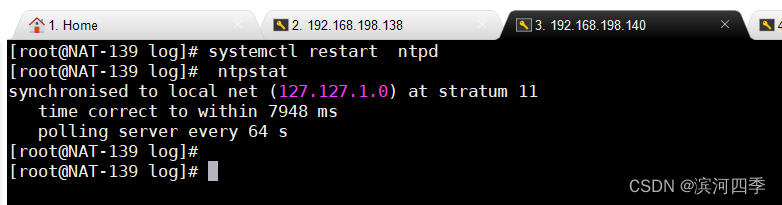
然后执行ntpq -pn命令查看服务器同步详细情况

以星号 (*)开头这就意味着您的计算机已经从网络上获取了时间,当前的refid是local代表我们配置的本地ntp服务器
ntp链接状态
ntpq -premote:本机和上层ntp的ip或主机名,“+”表示优先,“*”表示次优先
refid:参考上一层ntp主机地址
st:stratum阶层
when:多少秒前曾经同步过时间
poll:下次更新在多少秒后
reach:已经向上层ntp服务器要求更新的次数
delay:网络延迟
offset:时间补偿
jitter:系统时间与bios时间差#
参数详解:
remote – 用于同步的远程节点或服务器。“LOCAL”表示本机 (当没有远程服务器可用
时会出现)
表中第一个字符(统计代码)是状态标识(参见 Peer Status Word),包含 "
","x","-","#","+","*","o":
• " " – 无状态,表示: 没有远程通信的主机
• "LOCAL" 即本机 (未被使用的)高层级服务器 远程主机使用的这台机
器作为同步服务器
• “x” – 已不再使用
• “-” – 已不再使用
• “#” – 良好的远程节点或服务器但是未被使用 (不在按同步距离排序的前六个节点
中,作为备用节点使用)
• “+” – 良好的且优先使用的远程节点或服务器(包含在组合算法中)
• “*” – 当前作为优先主同步对象的远程节点或服务器
“o” – PPS 节点 (当优先节点是有效时)。实际的系统同步是源于秒脉冲信号
(pulse-per-second,PPS),可能通过PPS 时钟驱动或者通过内核接口。
refid – 远程的服务器进行同步的更高一级服务器
st – 远程节点或服务器的 Stratum(级别,NTP 时间同步是分层的)
t – 类型 (u: unicast(单播) 或 manycast(选播) 客户端, b: broadcast
(广播) 或 multicast(多播) 客户端, l: 本地时钟, s: 对称节点(用于备份),
A: 选播服务器, B: 广播服务器, M: 多播服务器, 参见“Automatic Server
Discovery“)
when – 最后一次同步到现在的时间 (默认单位为秒, “h”表示小时,“d”表示天)
poll – 同步的频率:rfc5905建议在 NTPv4 中这个值的范围在 4 (16秒) 至 17
(36小时) 之间(即2的指数次秒),然而观察发现这个值的实际大小在一个小的多的范围内
:64 (26 )秒 至 1024 (210 )秒
reach – 一个8位的左移移位寄存器值,用来测试能否和服务器连接,每成功连接一次
它的值就会增加,以 8 进制显示
delay – 从本地到远程节点或服务器通信的往返时间(毫秒)
offset – 主机与远程节点或服务器时间源的时间偏移量,offset 越接近于0,主机和
NTP 服务器的时间越接近(以方均根表示,单位为毫秒)
jitter – 与远程节点同步的时间源的平均偏差(多个时间样本中的 offset 的偏差,
单位是毫秒),这个数值的绝对值越小,主机的时间就越精确
客户端测试

使用ntpdate 服务器ip进行同步,发现报ntp socket被占用,是因为客户端开启了ntp服务,需要停掉ntp服务然后同步;

到这里同步完成,我们可在服务端和客户端同时执行date命令查看时间是否同步 ;

4、ntpd、ntpdate的区别
下面是网上关于ntpd与ntpdate区别的相关资料。如下所示:
使用之前得弄清楚一个问题,ntpd与ntpdate在更新时间时有什么区别。
ntpd不仅仅是时间同步服务器,它还可以做客户端与标准时间服务器进行同步时 间,而且是平滑同步,
并非ntpdate立即同步,在生产环境中慎用ntpdate,也正如此两者不可同时运行。
时钟的跃变,对于某些程序会导致很严重的问题。
许多应用程序依赖连续的时钟——毕竟,这是一项常见的假定,即,取得的时间是线 性的,
一些操作,例如数据库事务,通常会地依赖这样的事实:时间不会往回跳跃。
不幸的是,ntpdate调整时间的方式就是我们所说的”跃变“:在获得一个时间之后, ntpdate使用settimeofday(2)设置系统时间。
这有几个非常明显的问题:
1)这样做不安全
ntpdate的设置依赖于ntp服务器的安全性,攻击者可以利用一些软件设计上的缺 陷,拿下ntp服务器并令与其同步的服务器执行某些消耗性的任务。
由于ntpdate采用的方式是跳变,跟随它的服务器无法知道是否发生了异常(时间不 一样的时候,唯一的办法是以服务器为准)。
2)这样做不精确
一旦ntp服务器宕机,跟随它的服务器也就会无法同步时间。
与此不同,ntpd不仅能够校准计算机的时间,而且能够校准计算机的时钟。
3)这样做不够优雅
由于是跳变,而不是使时间变快或变慢,依赖时序的程序会出错 (例如,如果ntpdate发现你的时间快了,则可能会经历两个相同的时刻,对某些应 用而言,这是致命的)。尤其对数据库等对时间敏感的程序应用。
因而,唯一一个可以令时间发生跳变的点,是计算机刚刚启动,但还没有启动很多服 务的那个时候。
其余的时候,理想的做法是使用ntpd来校准时钟,而不是调整计算机时钟上的时 间。
NTPD在和时间服务器的同步过程中,会把BIOS计时器的振荡频率偏差——或者说 Local Clock的自然漂移(drift)——记录下来。 这样即使网络有问题,本机仍然能维持一个相当精确的走时。
二、NFS网络文件共享存储服务器
NFS介绍
NFS是Network File System的缩写,中文意思是网络文件系统。它的主要功能是通过网络(一般是局域网)让不同的主机系统之间可以共享文件或目录。
NFS客户端(一般为应用服务器,例如Web)可以通过挂载的方式将NFS服务器端共享的数据目录挂载带NFS客户端本地系统中(就是某一个挂载点下)。从客户端本地看,NFS服务器端共享的目录就好像是客户端自己的磁盘分区或目录一样,而实际上确实远端的NFS服务器的目录。
NFS网络文件系统很像Windows系统的网络共享、安全功能、网络驱动器映射,这也和Linux系统里的samba服务类似。只不过一般情况下,Windows网络共享服务或samba服务用于办公局域网共享,而互联网中小型网站集群架构后端常用NFS进行数据共享,如果是大型网站,那么有可能还会用到更复杂的分布式文件系统,例如:Moosefs(mfs)、GlusterFS、FastDFS.
为什么要使用共享存储
实现多台服务器之间数据共享
实现多台服务器之间数据一致
集群没有共享存储的情况
A用户上传图片经过负载均衡,负载均衡将上传请求调度至WEB1服务器上。
B用户访问A用户上传的图片,此时B用户被负载均衡调度至WEB2上,因为WEB2 上没有这张图片,所以B用户无法看到A用户传的图片。
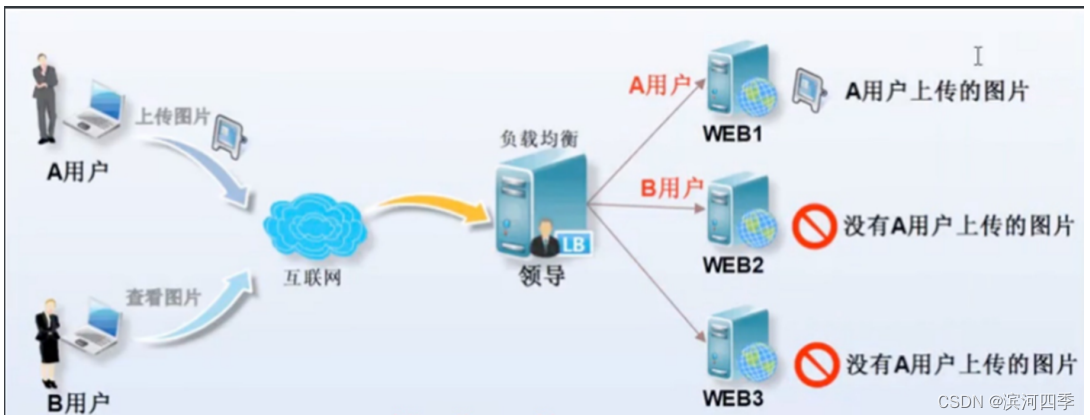
集群有共享存储的情况
A用户上传图片无论被负载均衡调度至WEB1还是WEB2, 最终数据都被写入至共享存储*
B用户访问A用户上传图片时,无论调度至WEB1还是WEB2,最终都会上共享存储访问对应的文件,这样就可以访问到资源了。
也就是用户上传文件时都上传到共享存储,不同服务器通过连接共享存储进行查看;

NFS工作原理
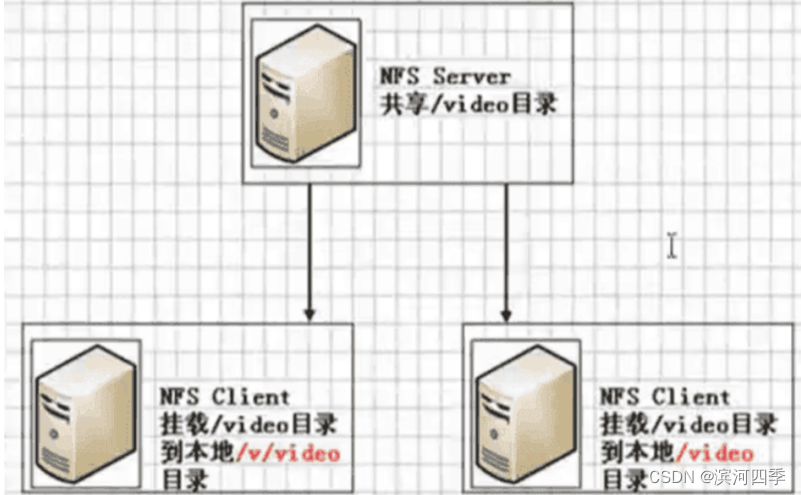
在NFS服务器端设置好一个共享目录/video后,其他有权限访问NFS服务器端的客户 端都可以将这个共享目录/video挂载到客户端本地的某个挂载点,图中的两个NFS客 户端本地的挂载点分别为/v/video和/video,不同客户端的挂载点可以不相同。
客户端正确挂载完毕后,就进入到了nfs客户端的挂载点所在的/v/video或/video目 录,此时就可以看到NFS服务器端/video共享出来的目录下的所有数据。在客户端上 查看时,NFS服务器端的/video目录就相当于客户端本地的磁盘分区或目录,几乎感 觉不到使用上的区别。
已经挂载完后用df -h可以看到本地挂载信息,和本地的磁盘分区几乎没什么差别, 只是文件系统的开始是以IP地址开头而已。
NFS服务所使用的端口号在每次启动的时候是不同的,通过RPC(远程过程调用Remote Procedure Call简称RPC)协议/服务来实现,这个RPC服务的应用在门户级的网站有很多。例如:百度。
什么是RPC
因为NFS支持的功能相当多,而不同的功能都会使用不同的程序来启动,每启动一个功能就会启用一些端口来传输数据,因此,NFS的功能所对应的端口无法固定,它会随机取用一些未被使用的端口来作为传输之用,其中CentOS5.x的随机端口都小于1024,而CentOS6.x的随机端口都是较大的。
因为端口不固定,这样一来就会造成NFS客户端与NFS服务端的通信障碍,因为NFS客户端必须要知道NFS服务器端的数据传输端口才能进行通信,才能交互数据。
要解决上面的困扰,就需要通过远程过程调用RPC服务来帮忙了,NFS的RPC服务最主要的功能就是记录每个NFS功能所对应的端口号,并且在NFS客户端请求时将该端口和功能对应的信息传递给请求数据的NFS客户端,从而确保客户端可以连接到正确的NFS端口上去,达到实现数据传输交互数据目的。
服务端的RPC服务如何知道每个NFS的端口的:

当NFS读取端启动服务时会随机取用若干端口,并主动向RPC服务注册相关端口的对应的功能,然后RPC服务使用固定的111端口来监听NFS客户端提交的请求,并将正确的NFS端口信息回复给请求的NFS客户端。
NFS实例搭建
我们需要两台CentOS7机器,我们用虚拟机做测试,分别做NFS服务器和客户端,配置如下:
NFS-Server ip:192.168.198.140
NFS-Client ip:192.168.198.138
实现的目标是:在NFS服务器上共享一个目录,在客户端上可以直接操作NFS服务器上的这个共享目录下的文件。
NFS服务端配置
①安装NFS服务和rpcbind
首先使用yum安装nfs服务:
yum -y install rpcbind nfs-utils②创建共享目录
在服务器上创建共享目录,并设置权限。
mkdir -p /data/share/
chmod 755 -R /data/share/③配置NFS
nfs的配置文件是 /etc/exports ,在配置文件中加入一行:
/data/share/ 192.168.198.140(rw,no_root_squash,no_all_squash,sync)
这行的意思是把共享目录/data/share/共享给192.168.198.138这个客户端ip,后面括号里的内容是权限参数,其中:rw 表示设置目录可读写。 sync表示数据会同步写入到内存和硬盘中,相反 rsync 表示数据会先暂存于内存中,而非直接写入到硬盘中。
no_root_squash NFS客户端连接服务端时如果使用的是root的话,那么对服务端分享的目录来说,也拥有root权限。
no_all_squash 不论NFS客户端连接服务端时使用什么用户,对服务端分享的目录来说都不会拥有匿名用户权限。
如果有多个共享目录配置,则使用多行,一行一个配置。
④启动服务
按顺序启动rpcbind和nfs服务:
systemctl start rpcbind
systemctl start nfs加入开机启动【centos7】:
systemctl enable rpcbind
systemctl enable nfs
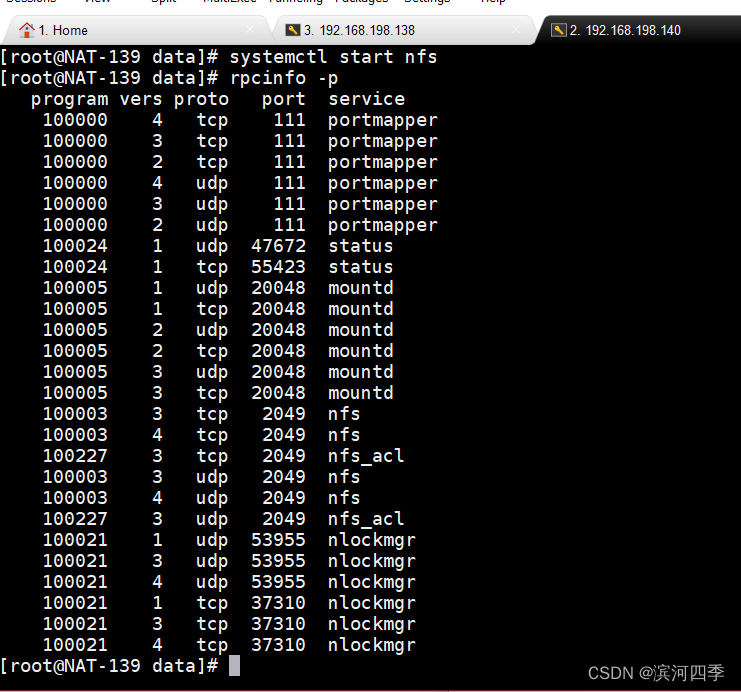
⑤验证服务
nfs服务启动后,可以使用命令 rpcinfo -p 查看端口是否生效。
111端口为rpcbind服务对外提供服务的主端口。
#设置服务开机自启动【centos6】
chkconfig rpcbind on
chkconfig nfs on
#查看
systemctl list-unit-files |grep rpcbind
systemctl list-unit-files | grep nfs我们可以使用 showmount 命令来查看服务端(本机)是否可连接:

出现上面结果表明NFS服务端配置正常。
NFS客户端配置
①安装rpcbind服务
Centos6.6版本及以上的系统需要安装nfs-utils软件,否则再挂载的时候会报错,Centos6.5以前的没有这个问题。
yum -y install nfs-utils rpcbind
#客户端只需要启动rpcbind服务即可:
service rpcbind start
②挂载远程nfs文件系统
查看服务端已共享的目录:
showmount -e 192.168.198.140
建立挂载目录,执行挂载命令:
mkdir /mnt/share
mount -t nfs 192.168.198.140:/data/share /mnt/share -o nolock,nfsvers=3,vers=3
如果不加 -o nolock,nfsvers=3 则在挂载目录下的文件属主和组都是nobody,如果指定nfsvers=3则显示root。
查看挂载结果,在客户端输入 df -h
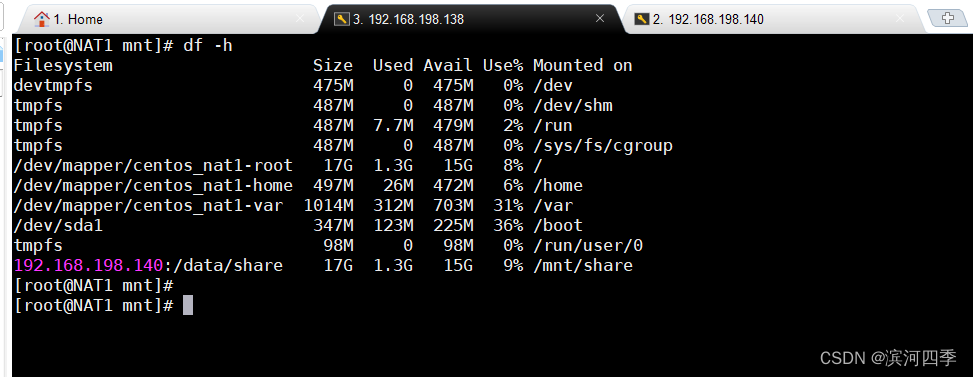
如果要解除挂载,可执行命令:
umount /mnt/share开机自动挂载
如果按上面的配置好,NFS即部署好了,但是如果你重启客户端系统,发现不能随机器一起挂载,需要再次手动操作挂载,这样操作比较麻烦,因此我们需要设置开机自动挂载。我们不要把挂载项写到/etc/fstab文件中,因为开机时先挂载本机磁盘再启动网络,而NFS是需要网络启动后才能挂载的,所以我们把挂载命令写入到/etc/rc.d/rc.local文件中即可。
[root@localhost ~]# vim /etc/rc.d/rc.local
#在文件最后添加一行:
mount -t nfs 192.168.42.101:/data/share /mnt/share/ -o nolock,nfsvers=3,vers=3
#同时需要给此脚本加执行权限
chmod +x /etc/rc.d/rc.local
保存并重启机器看看。测试验证
查看挂载结果,在客户端输入 df -h
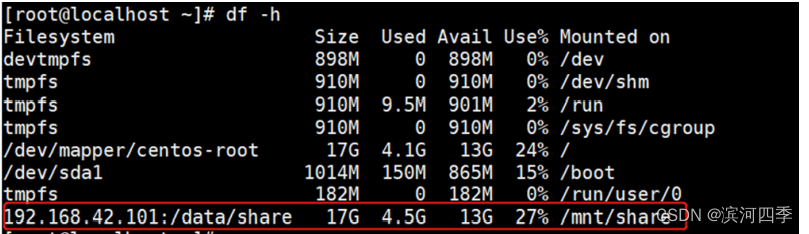
看到最后一行了没,说明已经挂载成功了。接下来就可以在客户端上进入目录/mnt/share下,新建/删除文件,然后在服务端的目录/data/share查看是不是有效果了,同样反过来在服务端操作在客户端对应的目录下看效果。
测试结果
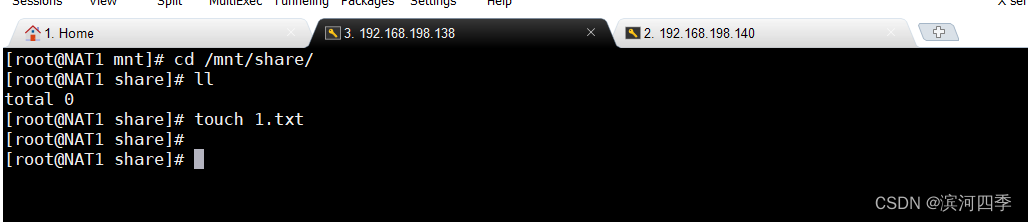
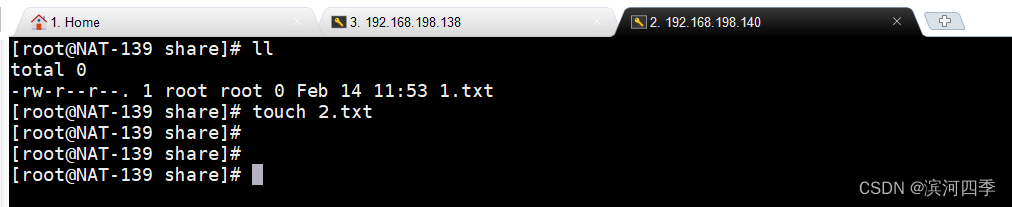
在138客户端的/mnt/share目录中创建一个1.txt文件,可以在服务端/data/share目录下看到此文件。
你也可以这样理解:将服务端的/data/share目录挂载到了客户端/mnt/share上,相当于将服务端的/data/share目录共享给了客户端的/mnt/share;
所以在客户端/mnt/share进行创建文件或删除文件的操作相当于直接对服务端/data/share目录下进行操作;
在服务端/data/share进行创建文件或删除文件的操作相当于直接对客户端/mnt/share目录下进行操作。
在客户端进行操作:

在服务端进行操作

三、NFS的优缺点
NFS服务可以让不同的客户端挂载使用同一个共享目录,也就是讲其作为共享存储使用,这样可以保证不同节点客户端数据的一致性,在集群架构环境中经常会使用到(仅支持类UNIX系统)。如果是Windows和Linux混合环境的集群系统,可以使用samba来实现。
优点:
简单,容易上手,容易掌握。
NFS文件系统内数据是在文件系统之上的,即数据是能看得见的。
部署快速,维护简单方便,且可控,满足需求就是最好的。
可靠,从软件层面上看,数据可靠性高,经久耐用。
服务非常稳定。
缺点:
存在单点故障,如NFS Server宕机了,所有客户端都不能访问共享目录,后期会 通过负载均衡及高可用方案弥补
在大数据高并发的场合,NFS效率、性能有限(2千万/日 以下PV的网站不是瓶 颈,除非网站架构设计太差)
客户端认证是基于IP和主机名的,权限需要根据ID识别,安全性一般(用于内网 则问题不大)
NFS数据是明文的,NFS本身不对数据完整性作验证(传输的文件可能完整也可能不完整)。
多台客户机器挂载一个NFS服务器时,连接管理维护麻烦(耦合度高)。尤其 NFS服务端出问题后,所有NFS客户端都处于挂掉状态(测试环境可使用autofs自动 挂载解决,正式环境可修复NFS服务或强制卸载umount -lf)
耦合性(英语:Coupling,dependency,或称耦合力或耦合度)是一种软件度量,是指一程序中,模块及模块之间信息或参数依赖的程度。 内聚性是一个和耦合性相对的概念,一般而言低耦合性代表高内聚性,反之亦然。
涉及了同步(实时等待)和异步(解耦)的概念,NFS服务端和客户端相对来说就是耦合度有些高。网站程序也是一样,尽量不要耦合度太高,系统及程序架构师的重要职责就是为了解决程序及架构解耦,让网站的可扩展性变得更好。





![jstack排查cpu占用高[复习]](https://img-blog.csdnimg.cn/img_convert/90082021a89d218851ab2d74973542d4.png)