近日,奇点云黑客马拉松“StartDT Hackathon”正式收官。
这期黑客松以“可观测性”为核心选题,旨在通过加强数据云平台DataSimba的可观测性,提升企业用户“自交付、自运维”的易用性和友好度,降低运维门槛,提升发现、定位并解决问题的效率。

企业级数据平台为什么要“可观测”?
企业级数据平台(数据云平台/云数仓/数据中台等同类数据基础设施)往往非常复杂,所涉及到的作业、任务、资源众多。一旦出现问题,运维工程师就需要扑入硬件、服务、业务的汪洋大海。有经验的“蝙蝠侠”能在数小时内定位问题,而对平台及其业务作业不够熟悉的用户,排查故障则犹如大海捞针。
实事求是,无论多么成熟稳定的平台,都可能会出问题。平台用得越多、越深,出现问题的次数就可能越多。然而,一家企业也很难同时拥有好几位专业“蝙蝠侠”,要求他们处理繁杂而基础的日常运维工作。
这就是“可观测性”要解决的问题。
Gartner在“2023年十大战略技术趋势”中这样解释应用可观测性(Applied Observability):在任何相关方采取任何类型的行动时,都会产生包含了数字化特征的可观测数据,如日志、痕迹、API调用、停留时间、下载和文件传输等。应用可观测性以一种高度统筹和整合的方式,将这些可观测的特征数据进行反馈,创造出一个决策循环,从而提高组织决策的有效性。
简而言之,对于企业级平台来说,真正具备“可观测性”意味着:
- 通过关键指标,用户可以精准、快速、全面地了解平台的硬件、进程、业务等整体状态,获得可能发生异常的预警提示,防患于未然。
- 出现故障后,能第一时间帮助用户快速定位故障所在,并针对性指导解决。
- 运维巡检周期化,能快速响应紧急的动态变化,而不依赖人工报告。
“客户对DataSimba(奇点云数据云平台)的使用越来越深,越来越‘狠’,通过DataSimba完成大量的数据工作。为配合高强度的使用,有越来越多的客户倾向于自交付、自运维。也就是说,相比往常遇到问题通过奇点云工程师来解决,他们更希望能自主识别问题并排查。”
奇点云CTO、资深技术专家地雷介绍,“因此在DataSimba中,我们针对不同类型的用户做了2个模块的设计——运维工程师通过PE平台,可以了解系统的稳定性,关注服务、组件是否正常,系统资源是否够用;数据开发则可以通过系统里的运维频道来确认任务是否正常运行。”
围绕平台“可观测性”提升,“磐石”组、“年夜饭”组各自交出了答卷。
指标全覆盖,诊断无死角
磐石组将其项目命名为“天眼”:运维工程师不能7*24小时“开天眼”排查问题,但系统或许可以。
磐石组以DataKun(奇点云数据存算引擎)为切入点,设计了基础监控数据指标体系,建设了完善的集控看板与诊断工具——覆盖了硬件、服务、业务三大层面,常见问题基本完全覆盖,监控全面无死角。
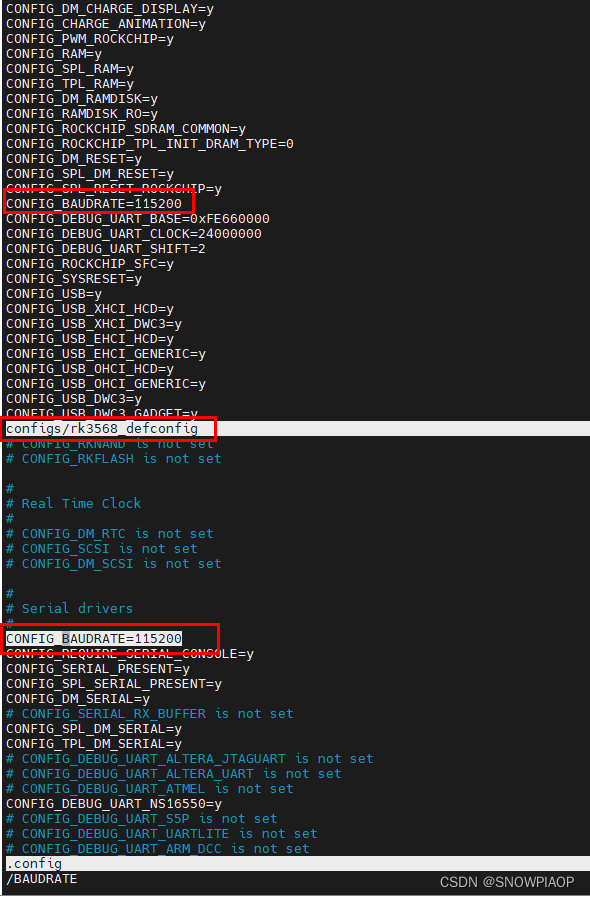
举个例子,通过“硬件集控看板”,CPU、内存、网络、磁盘状态一目了然;又如,想了解作业运行状态,就看“作业运行看板”。看板上呈现了作业运行的成功/失败等状态,以及这些状态下作业的数量、增长趋势、资源消耗等。从而对现状作出判断,譬如,等待作业如果过多,可能是算力不足导致的。
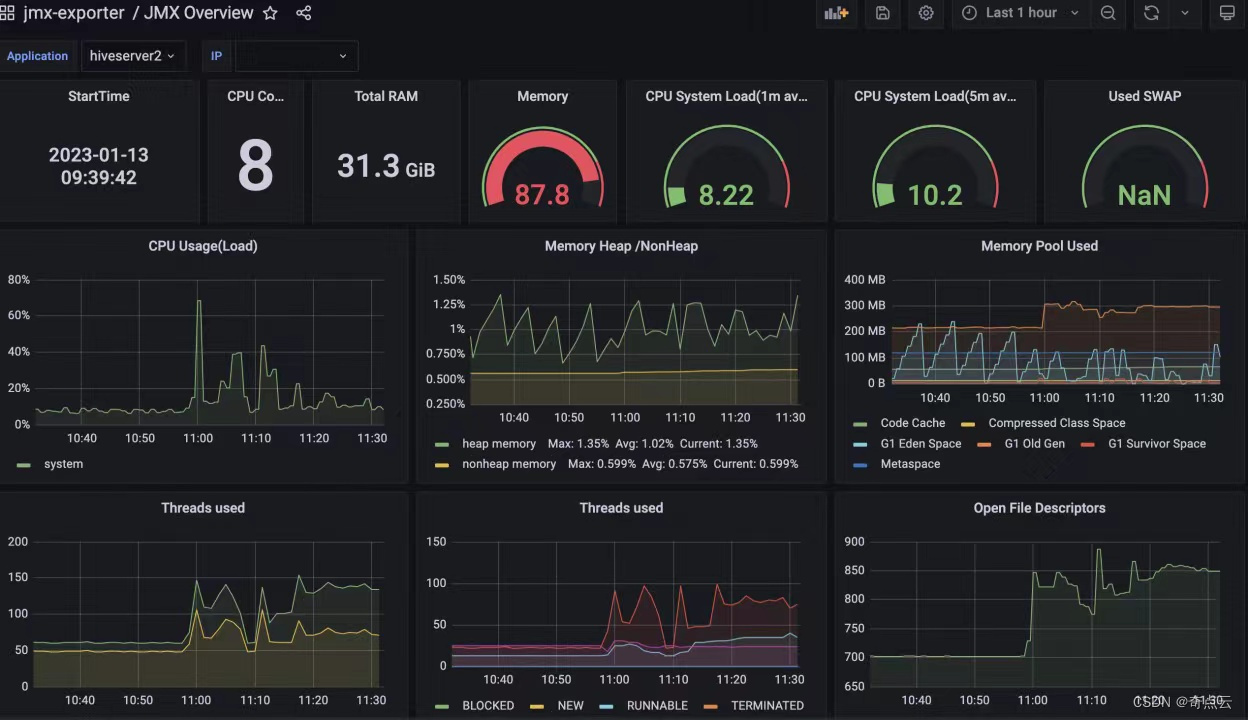
(硬件集控看板)
同时,磐石组引入了TezUI,针对性解决Tez作业监控难的问题。
磐石组表示:“Hive on Tez是常用的任务类型,但其执行机制复杂。当任务报错或发现运行过于缓慢想定位问题时,却会遇到日志排查效率低、组件指标数据收集困难等障碍。TezUI基于作业metrics(指标),不仅能精准高效地分析作业问题,可视化的运维工具也降低了定位问题的门槛。”
“以往企业定位问题常见的做法是:人肉看日志,手动做图表,找到异常点,再返回排查这个时间点前后发生了什么。而目前我们的基础指标基本覆盖了所有部件的状态,如果遇到问题,就能通过看板针对性发现问题。”组长曦光介绍,“排查一个问题,不需要看两个地方,也不再需要人肉收集数据分析。”
关注作业时延,监控再升级
与磐石组着眼于故障发生后的问题定位、排查不同,年夜饭组选择聚焦“事中监控”,希望通过对事中状态的归纳总结,帮助提前定位可能有问题的作业,“防患于未然”。
“我们发现,有越来越多的客户通过DataSimba跑小时调度任务,这类任务对作业运行时长这一指标更为敏感。”组长破破介绍,“我们针对性选择了任务时延等相关指标,以加强对作业粒度的监控和告警。”
“作业不一定跑失败了,只是跑得慢,跑得接近临界值。这种情况通常不被注意,但它在下一个周期或许就会超时。因此我们希望早发现、早定位、早‘治疗’。”年夜饭组提出了2组指标,帮助抓出“有问题”的作业:
- 24小时内作业实例运行时长延误TOP:以作业为单位,根据实际运行时长减去平均时长,计算出任务时延,再对月调度、天调度、小时调度的延误TOP进行排行榜降序排序。
- 本日调度耗时最长作业实例:统计每小时内耗时最长的作业实例,绘成折线图,辅助用户判断每小时内实例是否执行正常。
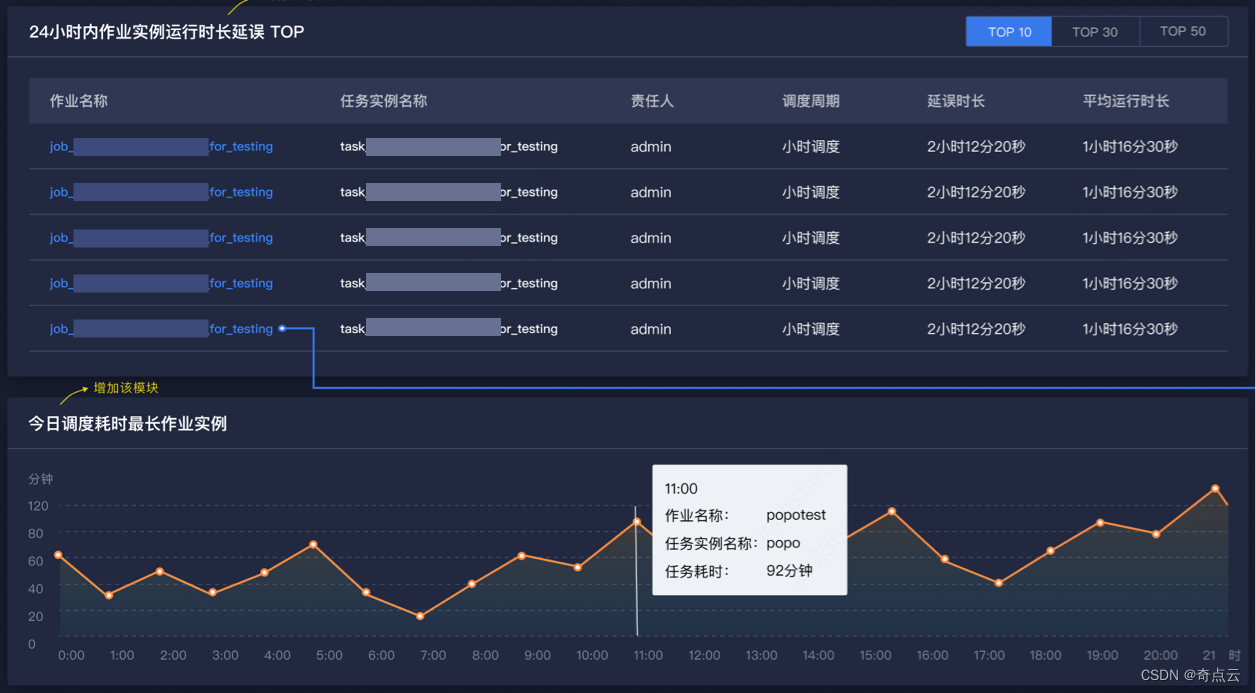
(作业时长看板)
此外,年夜饭组新增了“任务完成情况告警”与“全项目监控”功能,前者定时将作业实例执行情况推送至用户侧,用户无需登录平台,就可得知本日任务是否成功;后者则旨在监控Workspace(工作空间)下所有项目状态,便于用户了解全貌。
“监控系统对主系统的扰动性要足够小。通常来说,监控框架会采集底层日志,再聚合数据、形成图表,这些环节都会有资源消耗。为不影响主系统,监控系统的资源消耗应在可控范围内。”资深技术专家、评委牧然补充道。“对于年夜饭组,其作业运行监控的核心指标主要来自元数据,而无需另外采集,就不会对主系统本身造成压力。”
把“蝙蝠侠”装进产品里
正如前文谈到的,一家企业通常无法拥有足够的资深运维“蝙蝠侠”——他们不仅需要解决复杂的偶发性难题,还需要日以继夜处理繁琐的基础问题。同时,因人手有限,也往往很难第一时间响应所有数据开发遇到的困难,帮助他们排查作业失败的原因所在。
磐石组与年夜饭组所做的,就是“把资深蝙蝠侠装进产品里”,总结常见故障及其诊断指标,把蝙蝠侠know-how产品化。企业的数据开发和运维工程师能便捷地查看自己关注的指标,自助排查、找到病因。进一步,平台还能基于异常指标,给用户以智能化的策略与建议。
而同样都是优化监控精度、提升“可观测性”与运维易用性,磐石组与年夜饭组又有哪些不同?
评委地雷表示,这2个小组的方式在实践中互为补充,缺一不可:
年夜饭组基于元数据的监控与预警如同“体检”。先总结出常见问题,提炼出能反映这些问题的关键指标,通过关键指标发现异常;磐石组深入底层采集数据进行全面分析,帮助找到根因并着手解决。
二者结合来打比方,相当于年夜饭组负责在“烧糊涂”前发现“体温过高”,磐石组则负责做“血常规”等检查,找到病因并治疗。
从关注功能到关注稳定性、可用性及架构健壮性,以DataSimba为代表产品的数据云,已真正向“企业级”数据基础设施的技术深水区迈进。
“在这个阶段,每一次迭代升级都并不来自线性逻辑的推演,而需要有全流程上下游的意识,并通过超乎你过往想象的极端压测。”地雷表示,“我们不能预设每一位企业用户都是资深的大数据研发/运维专家,而应该让奇点云的产品更皮实、更友好、更聪明、更易用,成为用户的支持者。”
本次黑客马拉松呈现的只是冰山一角,未来,奇点云也将站在技术与商业的交叉点,支撑客户放心、便捷地把数据用起来。



![Go-micro[windows]安装以及踩坑](https://img-blog.csdnimg.cn/img_convert/3ab251e0b88786c97975c5274a1dd67e.png)