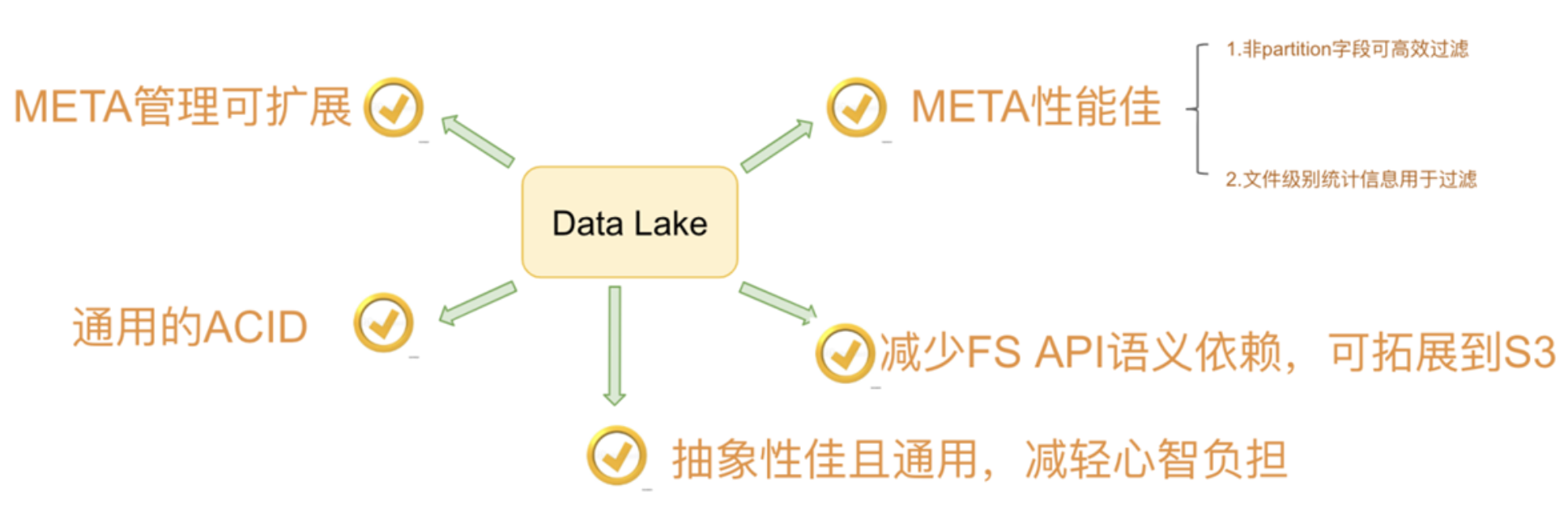
文章目录
一、统计函数 1. 求平均值 mean() 2. 中位数 np.median 3. 标准差 ndarray.std 4. 方差 ndarray.var() 5. 最大值 ndarray.max() 6. 最小值 ndarray.min() 7. 求和 ndarray.sum() 8. 加权平均值 numpy.average() 二、数据类型 1. 数据存储 2. 定义结构化数据 3. 结构化数据操作 三、操作文件 loadtxt 1. 读取文件内数据 2. 不同列标识不同信息,数据读取 3. 读取指定的列 4. 数据中存在空值进行处理
NumPy 能方便地求出统计学常见的描述性统计量。 最开始呢,我们还是先导入 numpy。 import numpy as np
mean() 是默认求出数组内所有元素的平均值。 我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止值(不包含)设置为 20,步长默认为 1 的 4 行 5 列的数组。 m1 = np. arange( 20 ) . reshape( ( 4 , 5 ) )
print ( m1)
m1. mean( )
如果我们想求某一维度的平均值,就设置 axis 参数,多维数组的元素指定。
m1 = np. arange( 20 ) . reshape( ( 4 , 5 ) )
print ( m1)
m1. mean( axis= 0 )
m1. mean( axis= 1 )
中位数又称中点数,中值。 它是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。 平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据;中位数:是一个不完全"虚拟"的数。 平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”;中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的"中等水平"。 接下来看两个例子,第一个中位数是数组中的元素,是一个不虚拟的数。 ar1 = np. array( [ 1 , 3 , 5 , 6 , 8 ] )
np. median( ar1)
ar1 = np. array( [ 1 , 3 , 5 , 6 , 8 , 9 ] )
np. median( ar1)
在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。 简单来说,标准差是一组数据平均值分散程度的一种度量。 一个较大的标准差,代表大部分数值和其平均值之间差异较大; 一个较小的标准差,代表这些数值较接近平均值。 例如,A、B 两组各有 6 位学生参加同一次语文测验,A 组的分数为 95、85、75、65、55、45,B 组的分数为 73、72、71、69、68、67,我们分析哪组学生之间的差距大(标准差大的差距大 )? a = np. array( [ 95 , 85 , 75 , 65 , 55 , 45 ] )
b = np. array( [ 73 , 72 , 71 , 69 , 68 , 67 ] )
print ( np. std( a) )
print ( np. std( b) )
我们也可以使用数学函数进行标准差的计算(使用标准差的数学公式即可)。 import math
( a - np. mean( a) ) ** 2 )
math. sqrt( np. sum ( ( ( a - np. mean( a) ) ** 2 ) / a. size) )
标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。 a = np. array( [ 95 , 85 , 75 , 65 , 55 , 45 ] )
b = np. array( [ 73 , 72 , 71 , 69 , 68 , 67 ] )
print ( 'A组的方差为:' , a. var( ) )
print ( 'B组的方准差为:' , b. var( ) )
标准差有计量单位,而方差无计量单位,但两者的作用一样,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。 最大值比较好理解,默认求出数组内所有元素的最大值。 axis = 0,将从上往下(按列)计算。 axis = 1,将从左往右(按行)计算。 print ( m1)
print ( m1. max ( ) )
print ( 'axis=0,从上往下查找:' , m1. max ( axis= 0 ) )
print ( 'axis=1,从左往右查找' , m1. max ( axis= 1 ) )
最小值比较好理解,默认求出数组内所有元素的最小值。 axis = 0,将从上往下(按列)计算。 axis = 1,将从左往右(按行)计算。 print ( m1)
print ( m1. min ( ) )
print ( 'axis=0,从上往下查找:' , m1. min ( axis= 0 ) )
print ( 'axis=1,从左往右查找' , m1. min ( axis= 1 ) )
求和比较好理解,默认求出数组内所有元素的总和。 axis = 0,将从上往下(按列)计算。 axis = 1,将从左往右(按行)计算。 print ( m1)
print ( m1. sum ( ) )
print ( 'axis=0,从上往下查找:' , m1. sum ( axis= 0 ) )
print ( 'axis=1,从左往右查找' , m1. sum ( axis= 1 ) )
加权平均值就是将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。 numpy. average( a, axis= None , weights= None , returned= False )
其中,weights 表示数组,是一个可选参数,与 a 中的值关联的权重数组。 a 中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的 a 的大小)或与 a 具有相同的形状。 如果 weights=None,则假定 a 中的所有数据的权重等于 1。一维计算是: avg = sum ( a * weights) / sum ( weights)
对权重的唯一限制是 sum(weights) 不能为 0。` average_a1 = [ 20 , 30 , 50 ]
print ( np. average( average_a1) )
print ( np. mean( average_a1) )
名称 描述 bool_ 布尔型数据类型(True 或者 False) int_ 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) intc 与 C 的 int 类型一样,一般是 int32 或 int 64 intp 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) int8 字节(-128 to 127) int16 整数(-32768 to 32767) int32 整数(-2147483648 to 2147483647) int64 整数(-9223372036854775808 to 9223372036854775807) uint8 无符号整数(0 to 255) uint16 无符号整数(0 to 65535) uint32 无符号整数(0 to 4294967295) uint64 无符号整数(0 to 18446744073709551615) float_ float64 类型的简写 float16 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 float32 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 float64 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 complex_ complex128 类型的简写,即 128 位复数 complex64 复数,表示双 32 位浮点数(实数部分和虚数部分) complex128 复数,表示双 64 位浮点数(实数部分和虚数部分)
a = np. array( [ 1 , 2 , 3 , 4 ] , dtype= np. float64)
a
a = np. array( [ 0 , 1 , 2 , 3 , 4 ] , dtype= np. bool_)
print ( a)
a = np. array( [ 0 , 1 , 2 , 3 , 4 ] , dtype= np. float_)
print ( a)
str1 = np. array( [ 1 , 2 , 3 , 4 , 5 , 6 ] , dtype= np. str_)
string1 = np. array( [ 1 , 2 , 3 , 4 , 5 , 6 ] , dtype= np. string_)
str2 = np. array( [ '我们' , 2 , 3 , 4 , 5 , 6 ] , dtype= np. str_)
print ( str1, str1. dtype)
print ( string1, string1. dtype)
print ( str2, str2. dtype)
在内存里统一使用 unicode, 记录到硬盘或者编辑文本的时候都转换成了utf8 UTF-8 将 Unicode 编码后的字符串保存到硬盘的一种压缩编码方式 在上述数据存储的过程种,我们对于 U1、S1、U2 并不能直接理解,这里使用其实是数据类型标识码。 字符 对应类型 字符 对应类型 字符 对应类型 字符 对应类型 b 代表布尔型 i 带符号整型 u 无符号整型 f 浮点型 c 复数浮点型 m 时间间隔(timedelta) M datatime(日期时间) O Python对象 S,a 字节串(S)与字符串(a) U Unicode V 原始数据(void)
还可以将两个字符作为参数传给数据类型的构造函数。 此时,第一个字符表示数据类型, 第二个字符表示该类型在内存中占用的字节数(2、4、8分别代表精度为16、32、64位的 浮点数)。 首先,我们创建结构化数据类型,然后,将数据类型应用于 ndarray 对象。 dt = np. dtype( [ ( 'age' , 'U1' ) ] )
print ( dt)
students = np. array( [ ( "我们" ) , ( 128 ) ] , dtype= dt)
print ( students, students. dtype, students. ndim)
print ( students[ 'age' ] )
以下示例描述了一位老师的姓名、年龄、工资的特征,该结构化数据其包含以下字段: str 字段:name。 int 字段:age。 float 字段:salary。 import numpy as np
teacher = np. dtype( [ ( 'name' , np. str_, 2 ) , ( 'age' , 'i1' ) , ( 'salary' , 'f4' ) ] )
b = np. array( [ ( 'wl' , 32 , 8357.50 ) ,
( 'lh' , 28 , 7856.80 )
] , dtype = teacher)
print ( b)
b[ 'name' ]
b[ 'age' ]
我们可以使用数组名 [结构化名],取出数组中的所有名称,取出数据中的所有年龄。 print ( b)
print ( b[ 'name' ] )
print ( b[ 'age' ] )
loadtxt 可以读取 txt 文本和 csv 文件。 loadtxt( fname, dtype= < type 'float' > , comments= '#' , delimiter= None , converters= None , skiprows= 0 , usecols= None , unpack= False , ndmin= 0 , encoding= 'bytes' )
其中参数具有如下含义: (1) fname:指定文件名称或字符串。支持压缩文件,包括 gz、bz 格式。 (2) dtype:数据类型。默认 float。 (3) comments:字符串或字符串组成的列表。表示注释字符集开始的标志,默认为 #。 (4) delimiter:字符串。分隔符。 (5) converters:字典。将特定列的数据转换为字典中对应的函数的浮点型数据。例如将空值转换为 0,默认为空。 (6) skiprows:跳过特定行数据。例如跳过前 1 行(可能是标题或注释),默认为 0。 (7) usecols:元组。用来指定要读取数据的列,第一列为 0。例如(1, 3, 5),默认为空。 (8) unpack:布尔型。指定是否转置数组,如果为真则转置,默认为 False。 (9) ndmin:整数型。指定返回的数组至少包含特定维度的数组。值域为 0、1、2,默认为 0。 (10) encoding:编码, 确认文件是 gbk 还是 utf-8 格式 返回:从文件中读取的数组。 例如 data1.txt 存在数据: 0 1 2 3 4 5 6 7 8 9 … 20 21 22 23 24 25 26 27 28 29 我们在读取普通文件时,可以不用设置分隔符(空格 制表符)。 data = np. loadtxt( r'D:\桌面\数据分析-班级\1-2班\data1.txt' , dtype= np. int32)
print ( data, data. shape)
我们在读取 csv 文件时,与普通文件不同,需要设置分隔符,csv 默认为 , 号。 data = np. loadtxt( 'csv_test.csv' , dtype= np. int32, delimiter= ',' )
print ( data, data. shape)
姓名 年龄 性别 身高 小王 21 男 170 … … … … 老王 50 男 180
文件:has_title.txt。(1) 以上数据由于不同列数据标识的含义和类型不同,因此我们需要自定义数据类型。 user_info = np. dtype( [ ( 'name' , 'U10' ) , ( 'age' , 'i1' ) , ( 'gender' , 'U1' ) , ( 'height' , 'i2' ) ] )
(2) 使用我们自定义的数据类型,进行读取数据操作。 data = np. loadtxt( 'has_title.txt' , dtype= user_info, skiprows= 1 , encoding= 'utf-8' )
这里需要注意的是,以上参数中,(1) 设置类型;(2) 跳过第一行;(3) 编码。 print ( data[ 'age' ] )
在读取到文件数据后,我们可以对其数据进行一定的操作。 首先,我们可以获取年龄的数组,计算年龄的中位数。 ages = data[ 'age' ]
ages. mean( )
- 我们也可以计算女生的平均身高(设置一个读取条件即可)。
isgirl = data[ 'gender' ] == '女'
print ( isgirl)
print ( data[ 'height' ] )
data[ 'height' ] [ isgirl]
girl_mean = np. mean( data[ 'height' ] [ isgirl] )
'{:.2f}' . format ( girl_mean)
读取指定的列 usecols=(1,3) 标识只读取第 2 列和第 4 列(索引从 0 开始)。 user_info = np. dtype( [ ( 'age' , 'i1' ) , ( 'height' , 'i2' ) ] )
print ( user_info)
data = np. loadtxt( 'has_title.csv' , dtype= user_info, delimiter= ',' , skiprows= 1 , usecols= ( 1 , 3 ) )
这里需要注意的是,在以上参数中:(1) 设置类型;(2) 跳过第一行;(3) 分隔符。 print ( data)
需要借助用于 converters 参数,传递一个字典,key 为列索引,value 为对列中值的处理。 比如,我们具体如下数据,csv 中学生信息中存在空的年龄信息: 姓名 年龄 性别 身高 小王 21 男 170 … … … … 小谭 男 169 … … … … 小陈 27 男 177
文件:has_empty_data.csv。 如果我们直接读取指定的列 usecols=(1,3) ,会出现错误。 因此,在需要处理空数据的时候,我们需要创建一个函数接收列的参数,并加以处理。 def parse_age ( age) :
try :
return int ( age)
except :
return 0
和之前一样的步骤,使用自定义的数据类型,读取数据。 print ( user_info)
data = np. loadtxt( 'has_empty_data.csv' , dtype= user_info, delimiter= ',' , skiprows= 1 , usecols= ( 1 , 3 ) , converters= { 1 : parse_age, 3 : parse_age} )
print ( data)
age_arr = data[ 'age' ]
age_arr
age_arr[ age_arr == 0 ] = np. median( age_arr[ age_arr != 0 ] )
age_arr. mean( )
计算班级年龄的平均值,由于存在 0 的数据,因此一般做法是将中位数填充。 首先,我们填充中位数,然后,我们计算平均值。 ages = data[ 'age' ]
ages[ ages== 0 ] = np. median( ages)
print ( ages)
np. round ( np. mean( ages) , 2 )