目录
- 1.Java 有哪几种基本数据类型?分别对应哪些包装类?
- 2.Java 中为什么要保留基本数据类型?为什么要使用包装类?
- 3.基本数据类型的转换规则有哪些?
- 4.基本数据类型与包装类有什么区别?
- 5.什么是装箱?什么是拆箱?它们的执行过程分别是什么?
- 6.什么是包装类型的缓存机制?
- 7.在进行算术运算时如果存在大量自动装箱的过程,可能会出现什么问题?
- 8.基本类型和包装类对象使用 == 和 equals 进行比较的区别是什么?
- 9.为什么浮点数运算的时候会有精度丢失的风险?如何解决该问题?
- 10.超过 long 整型的数据应该如何表示?
- 11.对于整型数据来说,存在 i 使得 i + 1 < i 吗?
- 12.char 型变量中能否存储一个中文汉字,为什么?
- 13.a = a + b 与 a += b 有什么区别吗?
1.Java 有哪几种基本数据类型?分别对应哪些包装类?
(1)Java 中一共有 8 种基本数据类型,同时分别对应 8 个包装类,具体如下表所示:
| 数据类型 | 关键字 | 字节数 | 取值范围 | 默认值 | 包装类 |
|---|---|---|---|---|---|
| 布尔型 | boolean | - | {true, false} | false | Boolean |
| 字节型 | byte | 1 | -128 ~ 127 | 0 | Byte |
| 短整型 | short | 2 | -215 ~ 215 - 1 | 0 | Short |
| 字符型 | char | 2 | 0 ~ 216 - 1 | ‘\u0000’(空格) | Character |
| 整型 | int | 4 | -231 ~ 231 - 1 | 0 | Integer |
| 长整型 | long | 8 | -263 ~ 263 - 1 | 0 | Long |
| 单精度浮点型 | float | 4 | 1.4013E-45 ~ 3.4028E+38 | 0.0F | Float |
| 双精度浮点型 | double | 8 | 4.9E-324 ~ 1.7977E+308 | 0.0D | Double |
(2)注意事项:
- 虽然定义了 boolean 这种数据类型,但是只对它提供了非常有限的支持。在 Java 虚拟机中没有任何供 boolean 值专用的字节码指令,Java 语言表达式所操作的 boolean 值,在编译之后都使用 Java 虚拟机中的 int 数据类型来代替,而 boolean 数组将会被编码成 Java 虚拟机的 byte 数组,每个元素 boolean 元素占 8 位。Java 虚拟机规范提议:
- 1)如果 boolean 是 “单独使用”:boolean 被编译为 int 类型,占 4 个字节;
- 2)如果 boolean 是以 “boolean 数组” 的形式使用:boolean 占 1 个字节,Java 虚拟机直接支持 boolean 数组,通过 newarray 指令创建 boolean 数组,然后通过 byte 数组指令 baload 和 bastore 来访问和修改 boolean 数组;
- 总之,boolean 占用 1 个字节、4 个字节都是有可能的,具体还要看虚拟机实现是否按照规范来。
- 当一个整数以 l 或者 L 结尾时,其字面值是 long 类型,否则就是默认的 int 类型,另外建议使用大写的 L,因为小写 l 容易和 1 混淆;
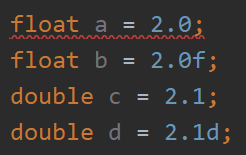
- 当一个浮点数以 f 或者 F 结尾时,其字面值是 float 类型,否则就是默认的 double 类型(以 d 或者 D 结尾,写不写都可以),不过在定义 float 类型的浮点数时,必须以 f 或 F 结尾,否则会报错,如下图所示。
2.Java 中为什么要保留基本数据类型?为什么要使用包装类?
(1)保留基本数据类型的原因如下:
- 在 Java 中,使用 new 关键字创建的对象存储在堆中,并且通过栈中的引用来使用这些对象,所以对象本身来说是比较消耗资源的。
- 基本类型存储在栈里,因为栈的效率高,所以保留了基本类型。变量的值存储在栈中,方法执行时创建,结束时销毁,因此更加高效。
- 使用基本数据类型参与计算时的性能要比使用包装类的高。
(2)使用包装类的原因如下:
- Java 语言是面向对象的编程语言,而基本数据类型声明的变量并不是对象,为其提供包装类,增强了 Java 面向对象的性质。
- 如果只有基本数据类型,那么在使用时会带来许多不便之处,例如,由于集合类中存放的元素必须是 Object 类型,因此无法存放 int、long、double 等基本数据类型。
- 此外,包装类还为基本类型添加了属性和方法,丰富了基本数据类型的操作,并且方便涉及到对象的操作。例如当我们想获取 int 取值范围的最小值,可以直接使用 Integer.MAX_VALUE 来表示最小值即可。
3.基本数据类型的转换规则有哪些?
(1)在代码种我们经常需要将一种数值类型转换为另一种数值类型。下图给出了数值类型之间的合法转换,其中, 6 个实心箭头表示无信息丢失的转换;3 个虚心箭头,表示可能有精度损失的转换。
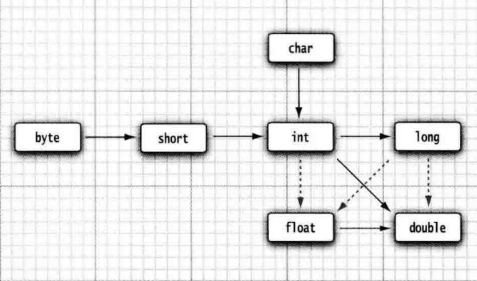
(2)基本数据类型的转换规则:
- 8 种基本数据类型中,除了 boolean 类型不能转换,剩下的 7 种类型之间都可以进行转换;
- 如果整数型字面值没有超过 byte、short、char 的取值范围,可以直接将其赋值给对应类型的变量;
- 小容量向大容量转换称为自动类型转换,容量从小到大排序为:byte < short / char < int < long < float < double,其中 short 和 char 都占用两个字节,但是 char 可以表示更大的正整数;
- 大容量转换为小容量,称为强制类型转换,编写时必须添加“强制类型转换符”,但运行时可能会出现精度损失,须谨慎使用。
- byte、short、char 类型混合运算时,先各自转换成 int 类型再做运算;
- 多种数据类型混合运算时,各自先转换成容量最大的那一种再做运算。
4.基本数据类型与包装类有什么区别?
(1)初始默认值:基本数据类型的的初始值则视具体的类型而定,而包装类型的初始值为 null;
(2)存储位置:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,几乎所有对象实例都存在于堆中,其引用存在于栈中。
(3)使用方式:包装类具有属性和方法,使用方式更加广阔,例如可存储到集合中、可用于泛型,而基本数据类型则不可以;
(4)空间占用:相比于包装类, 基本数据类型占用的空间非常小。
5.什么是装箱?什么是拆箱?它们的执行过程分别是什么?
(1)装箱与拆箱
- 装箱:基本数据类型转变为包装类型的过程。
- 拆箱:包装类型转变为基本数据类型的过程。
(2)执行过程
- 装箱是通过调用包装器类的 valueOf() 实现的。
- 拆箱是通过调用包装器类的 xxxValue() 实现的,xxx代表对应的基本数据类型。例如 int 装箱的时候自动调用 Integer 的 valueOf(int);Integer 拆箱的时候自动调用 Integer 的 intValue()。
//JDK 1.5 之前不支持自动装箱和自动拆箱,创建 Integer 对象必须按下面的方式进行
Integer i = new Integer(9);
//JDK 1.5 开始提供了自动装箱的功能,可以按下面的方式创建 Integer 对象
Integer i = 9;
//上一行代码等价于 Integer i = Integer.valueOf(9);
//自动拆箱
int n = i;
//上一行代码等价于 int n = i.intValue();
6.什么是包装类型的缓存机制?
Java 中的大部分包装类型的都用到了缓存机制来提升性能:
- Byte、Short、Integer、Long 这 4 种包装类默认创建了数值 [-128, 127] 的相应类型的缓存数据;
- Character 创建了数值在 [0, 127] 范围的缓存数据;
- Boolean 直接返回 True 或者 False;
- 由于在某个范围内的整型数值的个数是有限的,而浮点数却不是,valueOf() 直接返回新的对象;
Integer
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1 == i2); // true
System.out.println(i3 == i4); // false
Integer 的 valueOf(int i) 的具体实现如下:
public static Integer valueOf(int i) {
if (i >= -128 && i <= IntegerCache.high) {
return IntegerCache.cache[i + 128];
} else {
return new Integer(i);
}
}
从上面的代码可以看出,在通过 valueOf 方法创建 Integer 对象时,如果数值在 [-128, 127] 之间,便返回指向 IntegerCache.cache 中已经存在的对象的引用;否则创建一个新的 Integer 对象。上面的代码中 i1 和 i2 的数值为 100,因此会直接从 cache 中取已经存在的对象,所以 i1 和 i2 指向的是同一个对象,而 i3 和 i4 则是分别指向不同的对象。
现在再来看看下面的这段代码,请问输出结果是 true 还是 false?
Integer i1 = 100;
Integer i2 = new Integer(100);
System.out.println(i1 == i2);
答案为 false,其原因在于 Integer i1 = 100; 这行代码会自动装箱,即等价于 Integer i1 = Integer.valueOf(100);,并且由于 100 在 [-128, 127] 范围内,所以 i1 直接使用缓存中的对象;而 Integer i2 = new Integer(100); 会直接创建新的对象。因此输出结果为 false。
Character
// 小写字母 a 的 ASCII 值为 97
Character c1 = 'a';
Character c2 = 'a';
System.out.println(c1 == c2); // true
Character 的 valueOf(char c) 的具体实现如下:
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
Boolean
Boolean b1 = false;
Boolean b2 = false;
Boolean b3 = true;
Boolean b4 = true;
System.out.println(b1 == b2); // true
System.out.println(b3 == b4); // true
Boolean 的 valueOf(boolean b) 的具体实现如下:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
Double
Double d1 = 100.0;
Double d2 = 100.0;
Double d3 = 200.0;
Double d4 = 200.0;
System.out.println(d1 == d2); // false
System.out.println(d3 == d4); // false
//解释:在某个范围内的整型数值的个数是有限的,而浮点数却不是
7.在进行算术运算时如果存在大量自动装箱的过程,可能会出现什么问题?
在进行算术运算如果存在大量自动装箱的过程,且装箱返回的包装对象不是从缓存中获取的,那么会创建很多新的对象,这样比较消耗内存以及运行时间,如下面的代码所示:
public static void main(String[] args) {
Integer s1 = 0;
long t1 = System.currentTimeMillis();
for (int i = 0; i < 1000 * 10000; i++) {
//自动装箱
s1 += i;
}
long t2 = System.currentTimeMillis();
System.out.println("使用Integer,消耗了:" + (t2 - t1) + " ms"); // 44 ms
int s2 = 0;
long t3 = System.currentTimeMillis();
for (int i = 0; i < 1000 * 10000; i++) {
s2 += i;
}
long t4 = System.currentTimeMillis();
System.out.println("使用int,消耗了:" + (t4 - t3) + " ms"); // 4 ms
}
8.基本类型和包装类对象使用 == 和 equals 进行比较的区别是什么?
(1)值不同时
使用 == 和 equals() 比较时都返回 false;
(2)值相同时
① 使用 == 比较
基本类型 - 基本类型、基本类型 - 包装对象,返回 true;
包装对象 - 包装对象,非同一个对象(对象的内存地址不同)返回 false;对象的内存地址相同返回 true,如下面等于 100 的两个 Integer 对象(原因是 JVM 缓存部分基本类型常用的包装类对象,如 Integer -128 ~ 127 是被缓存的)
② 使用 equals() 比较
包装对象与基本类型比较,返回 true;
包装对象与包装对象比较,返回 true;
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
Integer c = 200;
Integer d = 200;
int e = 100;
int f = 200;
System.out.println(a == b); // true,a 和 b 均是缓存中的同一对象
System.out.println(c == d); // false,200 不在 [-128, 127] 范围内,a 和 b 是新创建的两个不同对象
System.out.println(a == e); // true
System.out.println(c == f); // true
System.out.println(a.equals(e)); // true
System.out.println(a.equals(b)); // true
System.out.println(c.equals(f)); // true
System.out.println(c.equals(d)); // true
}
《阿里巴巴 Java 开发手册》中规定:所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于Integer var = ?在 -128 至 127 之间的赋值,Integer 对象是在 IntegerCache.cache 产生,会复用已有对象,这个区间内的 Integer 值可以直接使用 == 进行判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用equals方法进行判断。
9.为什么浮点数运算的时候会有精度丢失的风险?如何解决该问题?
(1)浮点数运算精度不丢失与丢失的演示:
float a = 2.1f - 1.8f;
float b = 1.8f - 1.5f;
System.out.println(a); // 0.29999995
System.out.println(b); // 0.29999995
System.out.println(a == b); // true
float c = 2.0f - 1.9f;
float d = 1.8f - 1.7f;
System.out.println(c); // 0.100000024
System.out.println(d); // 0.099999905
System.out.println(c == d); // false
(2)精度可能丢失的原因:计算机底层的数据是用是二进制来表示的,并且计算机在表示一个数字时,其宽度是有限的,因此无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度丢失的情况。例如,十进制下的 0.2 就无法精确转换成二进制小数:
/*
0.2 转换为二进制数的过程如下:
(1) 不断乘以 2,直到不存在小数为止;
(2) 在计算过程中,得到的整数部分从上到下排列就是二进制的结果;
*/
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
...
(3)解决方法:java.math 包中的 BigDecimal 可以实现对浮点数的运算,并且不会造成精度丢失问题。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
BigDecimal a = new BigDecimal("2.0");
BigDecimal b = new BigDecimal("1.9");
BigDecimal c = new BigDecimal("1.8");
BigDecimal d = new BigDecimal("1.7");
BigDecimal e = a.subtract(b);
BigDecimal f = c.subtract(d);
System.out.println(e); // 0.1
System.out.println(f); // 0.1
System.out.println(Objects.equals(e, f)); // true
10.超过 long 整型的数据应该如何表示?
如果要表示超过 long 整型范围的数,可以使用 java.math 包中的 BigInteger 类,BigInteger 类实现了任意精度的整数运算。
// 9999999999999 已经超过 long 所能表示的范围
BigInteger a = new BigInteger("9999999999999");
BigInteger b = new BigInteger("1");
BigInteger c = a.add(b);
System.out.println(c); // 10000000000000
11.对于整型数据来说,存在 i 使得 i + 1 < i 吗?
(1)存在,i = Integer.MAX_VALUE,即 i = 2147483647;
(2)原因分析
计算机底层在进行加法运算时,会先将要相加的数转换为二进制补码,然后再将其相加。由于int 的取值范围是:-2147483648 ~ 2147483647 (-231 ~ 231 - 1)。当 i = Integer.MAX_VALUE,即 i = 2147483647时,其二进制补码如下所示,第一位的 0 是符号位,表示该数为正数。
01111111111111111111111111111111
从 int 的表示范围来看,i + 1 的结果显然超出了其表示范围。但是,在计算机底层进行计算时,i + 1 的补码是
10000000000000000000000000000000
该补码正好表示 Integer.MIN_VALUE,如果将 int 的表示范围看成一个环的话,当 i + 1 的结果大于 Integer.MAX_VALUE 时,那么从补码的角度来看,i + 1 会回到最小值,并且编译器不会提示报错。同理,当 i = Integer.MIN_VALUE时,i - 1 > i。
(3)代码验证
public static void main(String[] args) {
int i = Integer.MAX_VALUE;
System.out.println("i = " + i);
System.out.println("i + 1 = " + (i + 1));
System.out.println("i + 1 < i 的结果为:" + (i + 1 < i));
//查看 i 和 i + 1 的二进制补码表示
String strI = Integer.toBinaryString(i);
String strIP1 = Integer.toBinaryString(i + 1);
System.out.println("i 的二进制补码表示为:" + strI);
System.out.println("i + 1 的二进制补码表示为:" + strIP1);
}
结果如下:
i = 2147483647
i + 1 = -2147483648
i + 1 < i 的结果为:true
i 的二进制补码表示为:1111111111111111111111111111111
i + 1 的二进制补码表示为:10000000000000000000000000000000
Process finished with exit code 0
12.char 型变量中能否存储一个中文汉字,为什么?
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个 char 类型占 2 个字节(16 比特),所以放一个中文是没问题的。
补充:使用 Unicode 意味着字符在 JVM 内部和外部有不同的表现形式,在 JVM 内部都是 Unicode,当这个字符被从 JVM 内部转移到外部时(例如存入文件系统中),需要进行编码转换。所以 Java 中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,如 InputStreamReader 和 OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务;对于 C 程序员来说,要完成这样的编码转换恐怕要依赖于 union(联合体/共用体)共享内存的特征来实现。
13.a = a + b 与 a += b 有什么区别吗?
+= 操作符会进行隐式自动类型转换,此处 a += b 隐式地将加操作的结果类型强制转换为持有结果的类型,而 a = a + b 则不会自动进行类型转换。
byte a = 1;
byte b = 2;
b = a + b; //报编译错误,不兼容的类型: 从 int 转换到 byte 可能会有精度损失
b += a; //ok
同理,以下代码有也错误:
short s1= 1;
s1 = s1 + 1; //报编译错误,不兼容的类型: 从 int 转换到 short 可能会有损失
short 类型在进行运算时会自动提升为 int 类型,也就是说 s1 + 1 的运算结果是 int 类型,而 s1 是 short 类型,从 int 转换到 short 可能会有精度损失,所以会报编译错误。正确写法如下:
short s1= 1;
s1 += 1;
+= 操作符会将右边的表达式结果强转为匹配左边的数据类型,所以没错。
其实,s1 += 1 相当于 s1 = (short)(s1 + 1),有兴趣的可以自己编译下这两行代码的字节码,你会发现是一样的。