笔记整理:陈磊,天津大学硕士
链接:https://ieeexplore.ieee.org/ielx7/6287639/7859429/08057770.pdf
动机
设计一个强大而有效的损失框架对于知识图嵌入模型区分正确和不正确的三元组至关重要。经典的基于边距的排名损失将正负三元组的分数限制为具有合适的边距。最近提出的基于限制的评分损失独立地限制了正负三元组分数的范围。然而,这些损失框架使用相等或固定的惩罚项来降低正负样本对的分数,这在优化上是不灵活的。如果三元组分数与最佳值相差甚远,则应予以强调。因此,论文提出了自适应极限评分损失Adaptive Limit Scoring Loss,它简单地重新加权每个三元组以突出优化差的三元组分数。论文将这个损失框架应用于几个知识图谱嵌入模型,如TransE、TransH和ComplEx。链接预测和三元组分类的实验结果表明,论文提出的方法已经达到了与技术水平相当的性能。
亮点
MCCF的亮点主要包括:
(1)论文提出了自适应极限评分损失,这有利于知识图谱嵌入具有灵活的优化和明确的正负三元组分离的特点;
(2)与最近的知识图谱嵌入负样本损失框架基于限制的评分损失和双限制评分损失相比,论文的方法不仅减少了需要调整的参数的数量,而且提高了性能;
(3)论文在WordNet和Freebase数据集上进行了链接预测和三元组分类任务的实验,结果表明论文提出的方法具有优越性,其性能与目前最先进的技术水平相当。
概念及模型
论文首先介绍了用于优化知识图谱嵌入模型的自适应极限评分损失。其次,论文根据圆心的定位方法引入不同的损失指标进行优化。
自适应极限评分损失
基于Double Limit Scoring Loss (Zhou et al., 2021)的工作,论文考虑通过允许每个三元组得分根据它当前的优化状态以自己的速度学习来增强优化的灵活性。然后,论文将自适应的惩罚项分别添加到正负三元组评分中。于是得到了损失函数LAS。
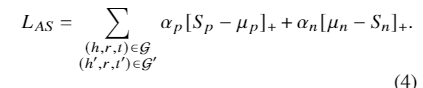
这其中αp和αn是非负权重因子。在训练过程中,当反向传播到Sp(或Sn)时,梯度将乘以αp(或αn)。当三元组得分与其最优值相差很大时,它应该获得一个大的权重因子,以便获得大梯度的有效更新.为此,论文以一种自适应的方式定义了αp和αn。
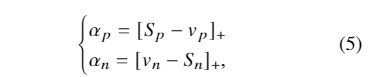
总体而言,等式 (4) 中的自适应极限评分损失期望 Sp< μp 和 Sn > μn。论文通过推导决策边界进一步分析了μp 和 μn的设置。在优化过程中,决策边界实现为

再结合等式5,论文可以得到
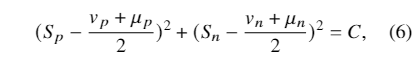
其中 C = ((vp − μp )2 +(vn −μn)2) /4 。等式(6)表明决策边界是圆弧,如图 1b 所示。圆的中心在Sn = (vn +μn)/2 , Sp = (vp +μp )/2,半径等于√C。这里论文有四个超参数:μp和μn 来自方程(4),vp和vn来自方程(5)。定位圆心后,四个超参数可以减少到两个。
定位圆心
圆心是 (Sn, Sp) 的理想优化目标,圆弧是实际的决策边界。通常,论文期望 Sn 的得分较低,而 Sp的得分更高。然而,论文的模型训练是基于开放世界假设,即知识图谱只包含真实的事实,而未观察到的事实可能是错误的,也可能只是缺失,这意味着生成的负三元组可能是正确的,但它们不会出现在原始知识图中。因此,论文不希望 Sn 是无限的,而是一个有限的值。这里论文考虑两种选择:
恒定自适应极限评分损失(CAS):论文将圆的中心设置为常数 (0, μp +μn)。相应地,等式(5)中的两个超参数Vp,Vn可以设置为Vp = −μp,Vn =μn +2μp。等式(6)中的决策边界可以降级为:

等式(7)中定义的决策边界旨在优化 Sp→ 0 和Sn→ μp +μn(实际上 (0, μp +μn) 无法达到,在等式 (4) 中论文限制 Sp≥ μp , Sn ≤ μn)。常数 (μp +μn) 的选择受到方程 (5) 中动态加权的取值范围的启发。当需要对模型嵌入进行优化时(即 Sp > μp , S n<μn ), 将 vp = -μp代入等式(5),可得正三元组动态权重范围αp> 2μp .同理,将 vn = μn+2μp代入式(5),论文可以得到相同范围的负三元组动态权重αn> 2μp。
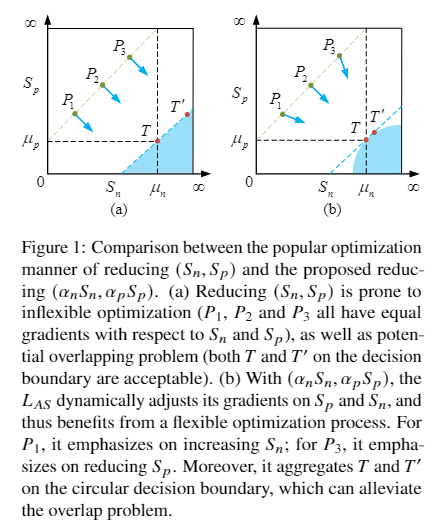
独立自适应极限评分损失(IAS):当模型嵌入处于不同状态时(例如图2中的 P1、P2 和 P3),它应该有不同的优化轨迹。论文期望找到每个独立嵌入状态的最佳轨迹。以图2中的点P1为例(假设其坐标为(Sn,Sp)),其对应的决策边界是最大的弧线(位于浅蓝色扇形区域),

而圆的中心是PC1 (C1n , 0)。根据相似三角形△PC 1 P0 P′0 ∼△PC 1 P1 P′1 论文可以得到:
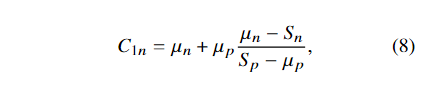
其中 Sn < μn, Sp > μp。结合等式(6)定义的圆心,等式(5)中的两个超参数vp ,v n可以通过设为vp = −μp, v n =μn + 2μp (μn − Sn)/ (Sp − μp)来消去。与LCAS相比,LIAS可以独立设置每个样本的圆心,获得独立的优化轨迹。
自适应极限评分通过添加自适应惩罚项来动态调整优化过程,进一步改善了双倍评分损失LSS。在模型训练的初期,正反三元组的分数离优化还很远,这时增加惩罚项的权重,获得较大的梯度。这有利于模型的早期快速收敛。在训练过程中,当成对的正负三元组的优化出现偏差时,如正三元组接近最优,而负三元组离要求还很远时,惩罚项会增加负三元组的权重,使负三元组能及时调整。除了对正负评分的单独限制外,带惩罚项的差异化步伐调整也可以缓解重叠问题,如图a和b中的T′:
理论分析
实验
论文在实验中使用了两个流行的知识图谱FreeBase和WordNet的一些子集,包括来自 WordNet 的 WN18、WN18RR 和 WN11,以及来自 Freebase 的 FB15k、FB15K-237 和 FB13。这些子集的统计数据如下表所示。其中FB15k-237和 WN18RR分别是 FB15k 和 WN18 删除了逆向关系的子集。

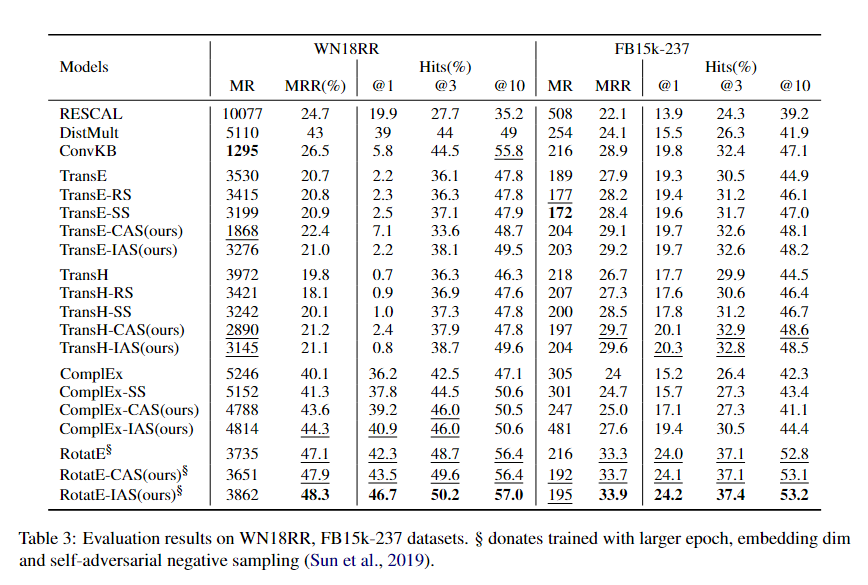
首先链接预测任务在WN18 和 FB15K数据集上实验的评价指标为:Mean和Hits@10。其中“raw”和“filt”的设置是为了区分是否考虑正确知识图中存在的损坏三元组的影响。从下表中可以看到具有LAS(包括 CAS 和 IAS)损失的模型都有不同程度的改善。与结果已经很高的 WN18(hit@10 上的 95%)相比,FB15K 有了显着的改进。在 FB15K 上,结果(比较 Hit@10 的最佳结果)增加了 TransE 6.4%,TransH-SS 1.6% 和 ComplEx-SS 0.7%。

然后链接预测任务在WN18 和 FB15K数据集上实验的评价指标是MR, MRR, Hits@1, Hits@3 and Hits@10。从下表中,可以看到具有LAS损失的模型在所有指标上都优于相应的具有LR、LRS和LSS的模型。
最后三元组分类任务,通常由翻译模型测试,很少由非线性模型验证。因此,在这个实验中,论文只测试比较翻译模型的系列并使用了三个数据集:WN11、FB13和FB15K进行实验。从下图的实验结果可以看出,在 WN11 上,具有LAS的模型都可以达到 84% 的准确率。在 FB13 上,具有LAS的模型与以前的损失模型相当。在 FB15K 上,带有 LAS的模型与以前的模型相比有了显着的改进,并且TransH-CAS 的表现最好,在比较模型中达到了 91.6% 的准确率。

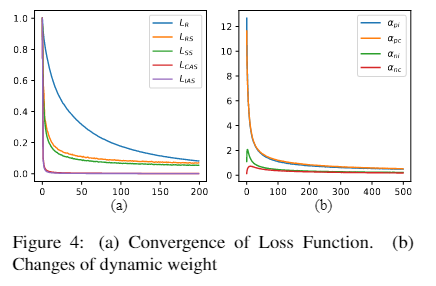
从下图a可以看出,LAS可以更快地收敛并达到更低的状态。这一现象证实了LAS有一个更明确的收敛目标,这促进了正负三元组的可分离性。从下图b可以看出,LIAS的权重变化比LCAS更敏感,两者的整体权重动态变化更接近。在实际应用中,论文建议先使用较简单的LCAS,而LIAS可能会带来一些更好的结果。
总结
论文提出了一个新颖的自适应极限评分损失框架,用于学习知识图谱嵌入。其提议的自适应评分损失的关键思想是重新加权每个三元组并突出显示优化少的三元组分数。对于动态权重的设置,首先根据圆心的定位提出了恒定自适应和独立自适应的方法。然后将其损失框架应用于 TransE、TransH、ComplEx 和 RotatE 等多个知识图嵌入模型,并在 WordNet 和 Freebase 数据集上进行链接预测和三元组分类任务的实验。实验结果表明了论文提出的方法的优越性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。