文章目录
- 一、redis知识汇总
- 什么是redis
- redis的优缺点:
- 为什么要用redis做缓存
- redis为什么这么快
- 什么是持久化
- redis持久化机制是什么?各自优缺点?
- AOF和RDB怎么选择
- redis持久化数据和缓存怎么做扩容
- 什么是事务
- redis事务的概念
- ACID概念
- 主从复制
- redis主从复制原理
- 一、redis部署
- 二、redis高可用
一、redis知识汇总
什么是redis
是开源免费的,高性能的k/v数据库
特点:支持数据的持久化、可以将内存中的数据保存在磁盘中,重启的时候再次加载使用;不仅支持k/v类型的数据,还提供list、set、zset(有序集合)、hash等数据结构的存储
支持数据的备份,也就是master-slave模式的数据备份
redis的优缺点:
优点:
读写性能优异;支持数据持久化、支持AOF、RDB两种持久化方式
支持事务,redis所有操作都是原子性的
数据结构丰富
支持主从复制、可以进行读写分离
缺点:
数据库内存受物理内存的限制,不能作海量数据的高性能读写
不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败
主机宕机,宕机前部分数据未能及时同步到从机,切换ip会引起数据不一致的问题,降低系统可用性
较难支持在线扩容,集群容量达到上限时在线扩容会变得复杂。
为什么要用redis做缓存
主要是因为它的高性能、高并发
高性能:用户第一次访问数据,会从硬盘上读取,但是他会将用户访问过的数据存在缓存中,这样下次用户访问就是从缓存中获取数据,也就是直接操作内存,速度非常快
高并发:直接操作缓存能够承受的请求量是远远大于直接访问数据库的,如mysql,如果请求量过大,可能承受不住。
redis为什么这么快
完全基于内存,绝大部分的请求是直接基于内存操作
数据结构简单,对数据的操作也简单
采用单线程,避免了多线程或者多线程的切换导致的CPU消耗,不用考虑各种锁的问题
采用多路i/o复用模型
什么是持久化
持久化就是把内存的数据写到磁盘中去,防止宕机后内存数据丢失
redis持久化机制是什么?各自优缺点?
持久化机制:
RDB(默认)
AOF
RDB:是默认的持久化方式;每隔一段时间,就把内存中的数据保存到硬盘上的指定文件中。触发RDB的方式有手动触发和被动触发
手动触发对应save和bgsave命令;
优点:只有一个文件dump.rdb,方便做持久化
性能最大化,fork子进程完成写操作,保证io最大化
相对于数据集大时,比AOF启动效率更高
缺点:数据安全性低,因为是没过一段时间进行数据持久化,如果在这个间断发生故障,就会导致数据丢失
AOF:AOF是以日志形式记录每个动作,每次操作都会以二进制命令的形式保存到指定文件中;两种方式同时开启时,数据恢复redis会优先选择AOF恢复
优点:数据安全,通过append模式写文件,即使中途服务器宕机,可以通过redis-check-aof工具解决数据一致性问题
如果不小心使用flushall命令清空所有数据,只要还没执行rewrite,那么就可以将日志文件中的flushall删除,进行恢复
缺点:AOF开启之后支持写的QPS(美妙查询率)会比RDB支持写的QPS低;数据恢复比较慢,不适合做冷备

AOF和RDB怎么选择
结合起来使用,用AOF保证数据不丢失,用RDB做不同程度的冷备,在AOF文件丢失不可用时,可以用RDB快速恢复
redis持久化数据和缓存怎么做扩容
如果redis被当做缓存使用,使用一致性哈希实现动态扩容缩容
如果被当做持久化存储,必须使用固定的keys-to-nodes映射关系,节点数量一旦确定不能变化,否则就要使用redis集群
什么是事务
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
redis事务的概念
Redis 事务的本质是通过MULTI(事物开始)、EXEC(事务执行)、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。总结:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
ACID概念
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性
事务前后数据的完整性必须保持一致。
隔离性
多个事务并发执行时,一个事务的执行不应影响其他事务的执行
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
Redis的事务总是具有ACID中的一致性和隔离性,其他特性是不支持的。当服务器运行在AOF持久化模式 下,并且appendfsync选项的值为always时,事务也具有耐久性。
主从复制
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 主节点(master),后者称为 从节点(slave)。且数据的复制是 单向 的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
作用:
数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 (实际上是一种服务的冗余)。
负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础,因此说主从复制是 Redis 高可用的基础。
redis主从复制原理
保存主节点(master)信息 这一步只是保存主节点信息,保存主节点的ip和port
主从建立连接 从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接
发送ping命令 连接建立成功后从节点发送ping请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令。
权限验证 如果主节点要求密码验证,从节点必须正确的密码才能通过验证。
同步数据集 主从复制连接正常通信后,主节点会把持有的数据全部发送给从节点。
命令持续复制 接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性
一、redis部署
下载并且编译,将整个目录直接拷贝至另一台主机作为slave端
修改slave端的配置文件,将master ip指向master端,端口6379,就完成了主从复制。redis的主从的配置比较简单。
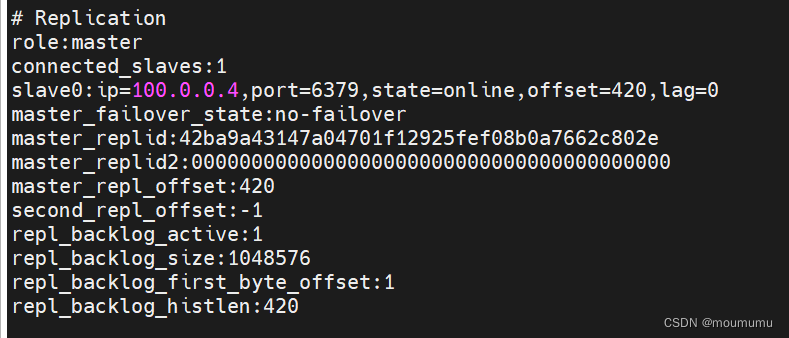
我们可以看到,在master上查看info,就可以看到slave那里变成了1,也就是现在我们有一个slave端,以及这个slave端的ip、状态等等
二、redis高可用
首先我们需要再加一台slave,配置方法和上边一样;我们使用sentinel来做故障切换,即高可用
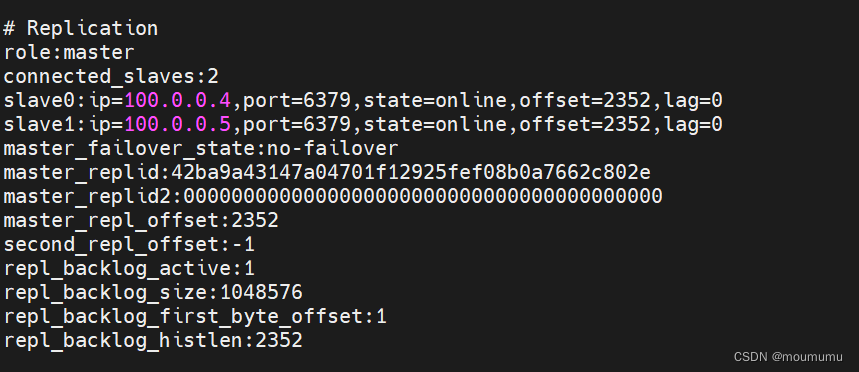
完成之后,我们在master端会看到slave数量为2,相关的端口、ip也都会显示;这些是做高可用的基础
首选我们需要在另外一台主机上ssh我们的master,并且shutdown redis,这个时候我们就会在log中看到master端down,并且会选举出新的master端代替原来的master,在我们重新又开启原来master的redis之后,此主机就会成为slave,并且指向新的刚选举出的master上。









![[HSCSEC 2023] rev,pwn,crypto,Ancient-MISC部分](https://img-blog.csdnimg.cn/img_convert/0f2c43221175c94bc65826a707caea56.jpeg)