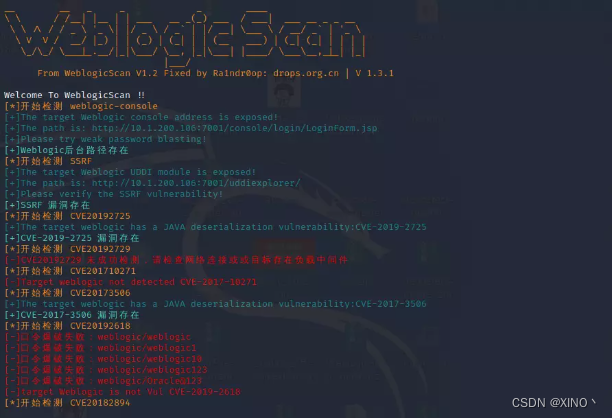
自监督表征学习方法——BYOL(Bootstrap Your Own Latent)
参考文献:《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
1.前言背景
学习良好的图像表示是计算机视觉中的一个关键挑战,因为它允许对下游任务进行有效的训练。许多不同的训练方法被提出来学习这种表征,通常依赖于视觉借口任务。
其中,最先进的对比方法是通过减少同一图像的不同增强视图的表示之间的距离和增加来自不同图像的增强视图的表示(负对)之间的距离来训练的。这些方法需要仔细处理负对,通过依赖大批量、内存库或定制的挖掘策略来检索负对。此外,它们的性能严重取决于图像增强的选择。
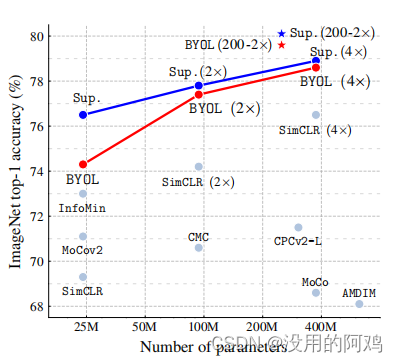
BYOL与以往自监督学习方法在ImageNet上的性能对比
2.BYOL介绍
BYOL在不使用负对的情况下,获得了比最先进的对比方法更高的性能。它迭代地引导网络的输出,以作为增强表示的目标。此外,BYOL对图像增强的选择比对比方法更鲁棒;我们怀疑不依赖负对是其提高鲁棒性的主要原因之一。虽然以前基于引导的方法使用了伪标签、聚类索引或一些标签,但我们建议直接引导表示。
特别是,BYOL使用两种神经网络,被称为在线网络和目标网络,它们相互作用和相互学习。
原理:从一个图像的增强视图开始,BYOL训练其在线网络来预测目标网络对同一图像的另一个增强视图的表示。
虽然这个目标允许折叠解,例如,为所有的图像输出相同的向量,但我们的经验表明,BYOL并不收敛于这样的解。
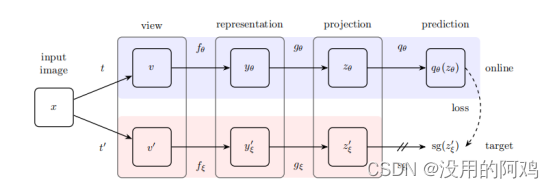
BYOL的框架图
如图所示,紫色部分为在线网络,红色部分为目标网络。
在线网络由一组权值θ定义,由三个阶段组成:编码器、投影仪
和预测器
。目标网络具有与在线网络相同的架构,但使用不同的权值ξ。
目标网络提供了对在线网络进行训练的回归目标,其参数ξ是在线参数θ的指数移动平均值。更准确地说,给定一个目标衰减率,在每个训练步骤后,我们执行以下更新,
![]()
具体流程如下:
①给定一组图像D,图像x∼D采样均匀从D,和两个分布的图像增强和
,BYOL产生两个增强视图
和
从x分别应用图像增强
和
。
②从第一个增广视图v中,在线网络输出一个表示法和一个投影法
。
目标网络从第二个增强视图输出
和目标投影
。
③然后,我们输出的预测和
。最后,我们定义了以下标准化预测和目标预测之间的均方误差,
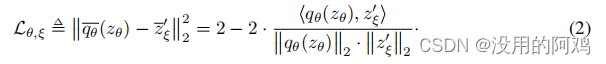
将v输入目标网络,则得到,最终最小化
![]()
参数更新情况如下
![]()
为学习率。
3.实验结果
在ImageNet上做自监督训练。
①下游任务用作ImageNet识别

②ImageNet半监督任务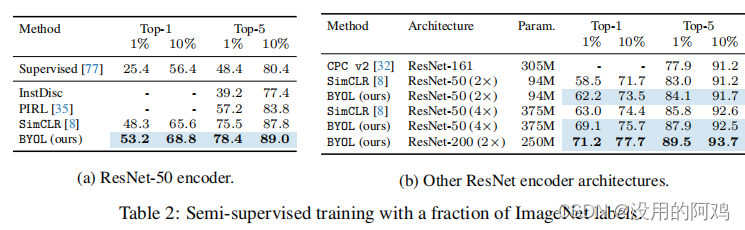
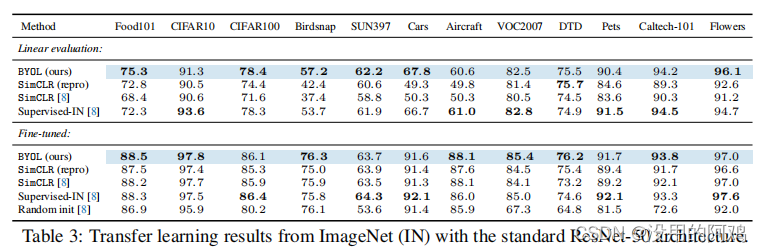
③迁移学习到别的数据集
 ④迁移学习到语义分割和目标检测以及深度估计
④迁移学习到语义分割和目标检测以及深度估计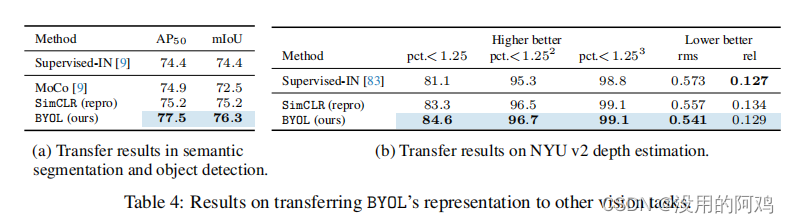
4.结论
这里介绍了一种新的图像表示的自监督学习算法BYOL。BYOL通过预测其输出的以前版本来学习它的表示,而不使用负对。并且展示了BYOL在各种基准测试上取得了最先进的结果。特别是,在使用ResNet-50(1×)的ImageNet线性评估协议下,BYOL实现了一种新的技术,并弥补了自监督方法和的监督学习基线之间的大部分剩余差距。使用ResNet-200(2×),BYOL达到了79.6%的前1位精度,比之前的技术水平(76.8%)有所提高,同时少使用了30%的参数。
然而,BYOL仍然依赖于特定于视觉应用程序的现有增强集。为了将BYOL推广到其他模式(例如,音频、视频、文本、……),有必要为每种模式获得类似的合适的扩充。设计这样的增强功能可能需要大量的努力和专业知识。因此,自动搜索这些增强功能将是将BYOL推广到其他模式的重要下一步。


![[HSCSEC 2023] rev,pwn,crypto,Ancient-MISC部分](https://img-blog.csdnimg.cn/img_convert/0f2c43221175c94bc65826a707caea56.jpeg)