集成 Hive
Hudi 源表对应一份 HDFS 数据,通过 Spark,Flink 组件或者 Hudi CLI,可以将 Hudi 表的数据映射为 *Hive 外部表*,基于该外部表, Hive可以方便的进行实时视图,读优化视图以及增量视图的查询。
集成步骤
以 hive3.1.2、hudi 0.12.0为例,其他版本类似。
(1)拷贝编译好的jar包
将 hudi-hadoop-mr-bundle-0.12.0.jar , hudi-hive-sync-bundle-0.12.0.jar 放到 hive 节点的lib目录下;
cp /opt/software/hudi-0.12.0/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.12.0.jar /opt/module/hive/lib/
cp /opt/software/hudi-0.12.0/packaging/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.12.0.jar /opt/module/hive/lib/
(2)配置完后重启 hive
// 按照需求选择合适的方式重启
nohup hive --service metastore &
nohup hive --service hiveserver2 &
Hive同步
(1)Flink同步Hive
Flink hive sync 现在支持两种 hive sync mode, 分别是 hms 和 jdbc 模式。 其中 hms 只需要配置 metastore uris;而 jdbc 模式需要同时配置 jdbc 属性 和 metastore uris,具体配置模版如下:
## hms mode 配置
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' = 'hdfs://xxx.xxx.xxx.xxx:9000/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.table'='${hive_table}', -- required, hive 新建的表名
'hive_sync.db'='${hive_db}', -- required, hive 新建的数据库名
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'hive_sync.metastore.uris' = 'thrift://ip:9083' -- required, metastore的端口
);
实例:
CREATE TABLE t10(
id int,
num int,
ts int,
primary key (id) not enforced
)
PARTITIONED BY (num)
with(
'connector'='hudi',
'path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t10',
'table.type'='COPY_ON_WRITE',
'hive_sync.enable'='true',
'hive_sync.table'='h10',
'hive_sync.db'='default',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hadoop1:9083'
);
insert into t10 values(1,1,1);
(2)Spark 同步Hive
参数:https://hudi.apache.org/docs/basic_configurations#Write-Options
option("hoodie.datasource.hive_sync.enable","true"). //设置数据集注册并同步到hive
option("hoodie.datasource.hive_sync.mode","hms"). //使用hms
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://ip:9083"). //hivemetastore地址
option("hoodie.datasource.hive_sync.username",""). //登入hiveserver2的用户
option("hoodie.datasource.hive_sync.password",""). //登入hiveserver2的密码
option("hoodie.datasource.hive_sync.database", ""). //设置hudi与hive同步的数据库
option("hoodie.datasource.hive_sync.table", ""). //设置hudi与hive同步的表名
option("hoodie.datasource.hive_sync.partition_fields", ""). //hive表同步的分区列
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor"). // 分区提取器 按/ 提取分区
案例:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
.withColumn("a",split(col("partitionpath"),"\\/")(0))
.withColumn("b",split(col("partitionpath"),"\\/")(1))
.withColumn("c",split(col("partitionpath"),"\\/")(2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option("hoodie.table.name", tableName).
option("hoodie.datasource.hive_sync.enable","true").
option("hoodie.datasource.hive_sync.mode","hms").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hadoop1:9083").
option("hoodie.datasource.hive_sync.database", "default").
option("hoodie.datasource.hive_sync.table", "spark_hudi").
option("hoodie.datasource.hive_sync.partition_fields", "a,b,c").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
mode(Overwrite).
save(basePath)
Flink使用 HiveCatalog
(1)直接使用Hive Catalog
-
上传hive connector到flink的lib中
hive3.1.3的connector存在guava版本冲突,需要解决:官网下载connector后,用压缩软件打开jar包,删除/com/google文件夹。处理完后上传flink的lib中。
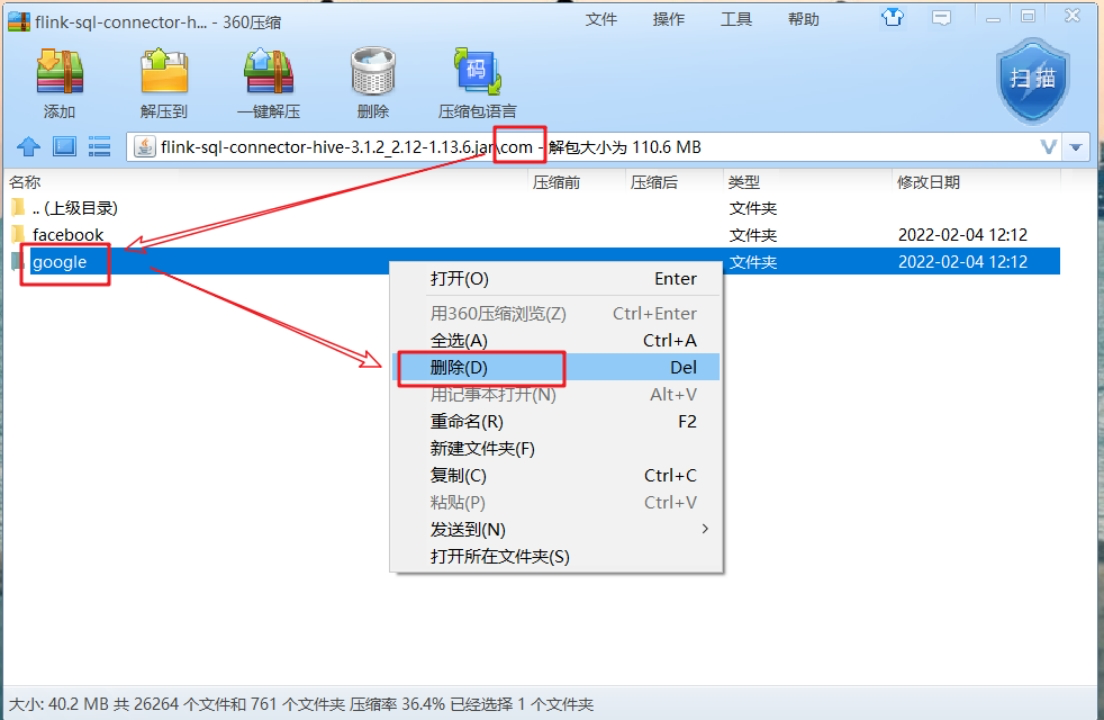
-
解决与hadoop的冲突
避免与hadoop的冲突,拷贝hadoop-mapreduce-client-core-3.1.3.jar到flink的lib中(5.2.1已经做过)
-
创建catalog
CREATE CATALOG hive_catalog WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/opt/module/hive/conf', 'hadoop-conf-dir'='/opt/module/hadoop-3.1.3/etc/hadoop' ); use catalog hive_catalog; -- hive-connector内置了hive module,提供了hive自带的系统函数 load module hive with ('hive-version'='3.1.2'); show modules; show functions; -- 可以调用hive的split函数 select split('a,b', ',');
(2)Hudi Catalog使用hms
CREATE CATALOG hoodie_hms_catalog
WITH (
'type'='hudi',
'catalog.path' = '/tmp/hudi_hms_catalog',
'hive.conf.dir' = '/opt/module/hive/conf',
'mode'='hms',
'table.external' = 'true'
);
创建 Hive 外表
一般来说 Hudi 表在用 Spark 或者 Flink 写入数据时会自动同步到 Hive 外部表(同6.2), 此时可以直接通过 beeline 查询同步的外部表,若写入引擎没有开启自动同步,则需要手动利用 hudi 客户端工具 run_hive_sync_tool.sh 进行同步,具体后面介绍。
查询 Hive 外表
(1)设置参数
使用 Hive 查询 Hudi 表前,需要通过set命令设置 hive.input.format,否则会出现数据重复,查询异常等错误,如下面这个报错就是典型的没有设置 hive.input.format 导致的:
java.lang.IllegalArgumentException: HoodieRealtimeReader can oly work on RealTimeSplit and not with xxxxxxxxxx
除此之外对于增量查询,还需要 set 命令额外设置3个参数。
set hoodie.mytableName.consume.mode=INCREMENTAL;
set hoodie.mytableName.consume.max.commits=3;
set hoodie.mytableName.consume.start.timestamp=commitTime;
注意这3个参数是表级别参数。
| 参数名 | 描述 |
|---|---|
| hoodie.mytableName.consume.mode | Hudi表的查询模式。增量查询 :INCREMENTAL。非增量查询:不设置或者设为SNAPSHOT |
| hoodie.mytableName.consume.start.timestamp | Hudi表增量查询起始时间。 |
| hoodie. mytableName.consume.max.commits | Hudi表基于 hoodie.mytableName.consume.start.timestamp之后要查询的增量commit次数。例如:设置为3时,增量查询从指定的起始时间之后commit 3次的数据设为-1时,增量查询从指定的起始时间之后提交的所有数据 |
(2)COW 表查询
这里假设同步的 Hive 外表名为 hudi_cow。
-
实时视图
设置 hive.input.format 为以下两个之一:
- org.apache.hadoop.hive.ql.io.HiveInputFormat
- org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat
像普通的hive表一样查询即可:
set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat; select count(*) from hudi_cow; -
增量视图
除了要设置 hive.input.format,还需要设置上述的3个增量查询参数,且增量查询语句中的必须添加 where 关键字并将 `_hoodie_commit_time > ‘startCommitTime’ 作为过滤条件(这地方主要是hudi的小文件合并会把新旧commit的数据合并成新数据,hive是没法直接从parquet文件知道哪些是新数据哪些是老数据)
set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat; set hoodie.hudicow.consume.mode= INCREMENTAL; set hoodie.hudicow.consume.max.commits=3; set hoodie.hudicow.consume.start.timestamp= xxxx; select count(*) from hudicow where `_hoodie_commit_time`>'xxxx' -- (这里注意`_hoodie_commit_time` 的引号是反引号(tab键上面那个)不是单引号, 'xxxx'是单引号)
(3)MOR 表查询
这里假设 MOR 类型 Hudi 源表的表名为hudi_mor,映射为两张 Hive 外部表hudi_mor_ro(ro表)和 hudi_mor_rt(rt表)。
-
实时视图
设置了 hive.input.format 之后,即可查询到Hudi源表的最新数据
set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat; select * from hudicow_rt; -
读优化视图
ro 表全称 read oprimized table,对于 MOR 表同步的 xxx_ro 表,只暴露压缩后的 parquet。其查询方式和COW表类似。设置完 hiveInputFormat 之后 和普通的 Hive 表一样查询即可。
-
增量视图
这个增量查询针对的rt表,不是ro表。同 COW 表的增量查询类似:
set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat; // 这地方指定为HoodieCombineHiveInputFormat set hoodie.hudimor.consume.mode=INCREMENTAL; set hoodie.hudimor.consume.max.commits=-1; set hoodie.hudimor.consume.start.timestamp=xxxx; select * from hudimor_rt where `_hoodie_commit_time`>'xxxx';// 这个表名要是rt表 索引说明:
- set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;最好只用于 rt 表的增量查询 当然其他种类的查询也可以设置为这个,这个参数会影响到普通的hive表查询,因此在rt表增量查询完成后,应该设置 set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; 或者改为默认值set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 用于其他表的查询。
- set hoodie.mytableName.consume.mode=INCREMENTAL; 仅用于该表的增量查询模式,若要对该表切换为其他查询模式,应设置set hoodie.hudisourcetablename.consume.mode=SNAPSHOT;
hive sync tool
若写入引擎没有开启自动同步,则需要手动利用 Hudi 客户端工具进行同步,Hudi提供Hive sync tool用于同步Hudi最新的元数据(包含自动建表、增加字段、同步分区信息)到hive metastore。
Hive sync tool提供三种同步模式,JDBC,HMS,HIVEQL。这些模式只是针对Hive执行DDL的三种不同方式。在这些模式中,JDBC或HMS优于HIVEQL, HIVEQL主要用于运行DML而不是DDL。
(1)使用语法及参数
脚本位置在hudi源码路径下的hudi-sync/hudi-hive-sync/run_sync_tool.sh
-
语法
#查看语法帮助 ./run_sync_tool.sh --help #语法: ./run_sync_tool.sh \ --jdbc-url jdbc:hive2:\/\/hiveserver:10000 \ --user hive \ --pass hive \ --partitioned-by partition \ --base-path <basePath> \ --database default \ --table <tableName>从Hudi 0.5.1版本开始,读时合并优化版本的表默认带有’_ro’后缀。为了向后兼容旧的Hudi版本,提供了一个可选的配置 --skip-ro-suffix,如果需要,可以关闭’_ro’后缀。
-
参数说明
HiveSyncConfig DataSourceWriteOption 描述 –database hoodie.datasource.hive_sync.database 同步到hive的目标库名 –table hoodie.datasource.hive_sync.table 同步到hive的目标表名 –user hoodie.datasource.hive_sync.username hive metastore 用户名 –pass hoodie.datasource.hive_sync.password hive metastore 密码 –use-jdbc hoodie.datasource.hive_sync.use_jdbc 使用JDBC连接到hive metastore –jdbc-url hoodie.datasource.hive_sync.jdbcurl Hive metastore url –sync-mode hoodie.datasource.hive_sync.mode 同步hive元数据的方式. 有效值为 hms, jdbc 和hiveql. –partitioned-by hoodie.datasource.hive_sync.partition_fields hive分区字段名,多个字段使用逗号连接. –partition-value-extractor hoodie.datasource.hive_sync.partition_extractor_class 解析分区值的类名,默认SlashEncodedDayPartitionValueExtractor
(2)解决依赖问题
run_sync_tool.sh这个脚本就是查找hadoop、hive和bundle包的依赖,实际上使用的时候会报错各种ClassNotFoundException、NoSuchMethod,所以要动手修改依赖的加载逻辑:
vim /opt/software/hudi-0.12.0/hudi-sync/hudi-hive-sync/run_sync_tool.sh
-
修改hadoop、hive、hudi-hive-sync-bundle-0.12.0.jar的依赖加载
a. 将34行 HUDI_HIVE_UBER_JAR=xxxx 注释掉
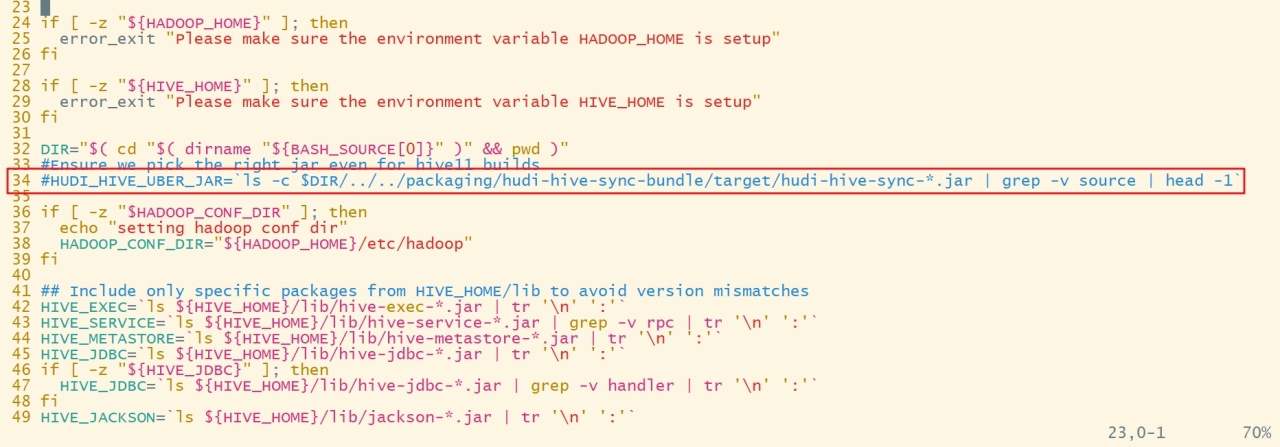
b. 将52行 HADOOP_HIVE_JARS=xxx注释掉
#在 54行 添加如下: HADOOP_HIVE_JARS=`hadoop classpath`:$HIVE_HOME/lib/* HUDI_HIVE_UBER_JAR=/opt/software/hudi-0.12.0/packaging/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.12.0.jar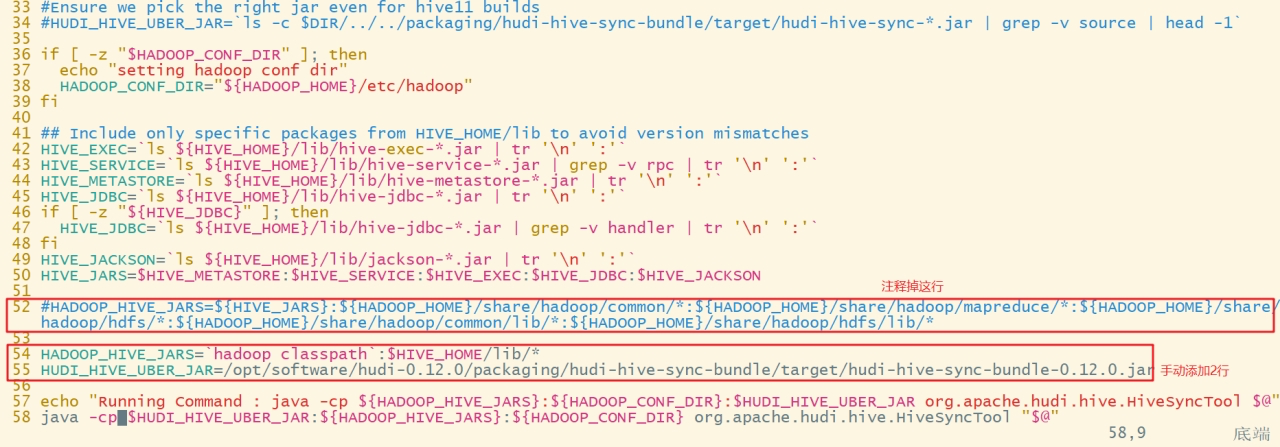
-
解决parquet-column的版本冲突
a. 上传parquet-column-1.12.2.jar到/opt/software/,脚本中添加如下:
PARQUET_JAR=/opt/software/parquet-column-1.12.2.jar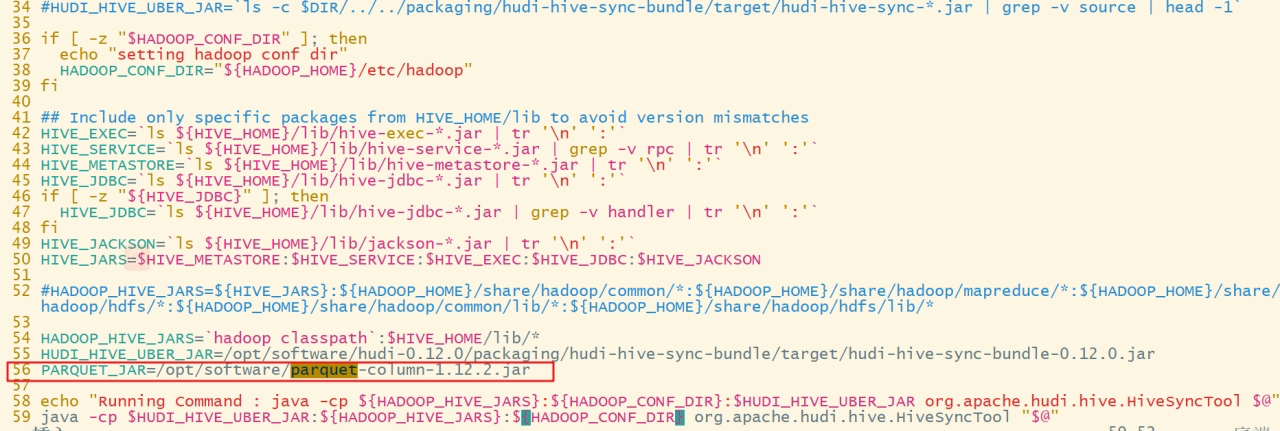
b. 拼接路径到命令最前面(只能最前面!)
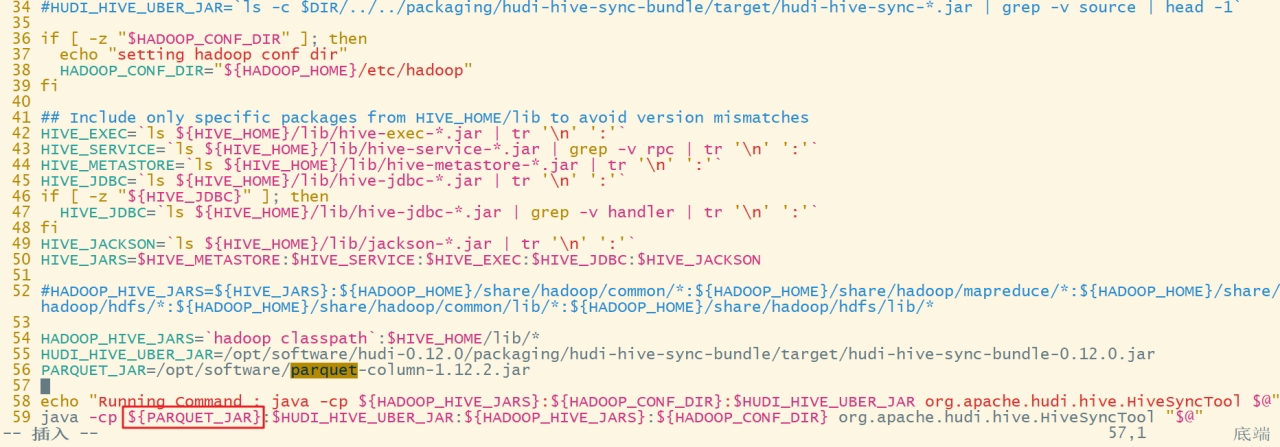
c. 保存退出
(3)JDBC模式同步
通过hive2 jdbc协议同步,提供的是hive server2的地址,如jdbc:hive2://hive-server:10000。默认为jdbc。
cd /opt/software/hudi-0.12.0/hudi-sync/hudi-hive-sync
./run_sync_tool.sh \
--base-path hdfs://hadoop1:8020/tmp/hudi_flink/t2/ \
--database default \
--table t2_flink \
--jdbc-url jdbc:hive2://hadoop1:10000 \
--user atguigu \
--pass atguigu \
--partitioned-by num
(4)HMS模式同步
提供hive metastore的地址,如thrift://hms:9083,通过hive metastore的接口完成同步。使用时需要设置 --sync-mode=hms。
如果使用的是远程metastore,那么确保hive-site.xml配置文件中设置hive.metastore.uris。
./run_sync_tool.sh \
--base-path hdfs://hadoop1:8020/tmp/hudi_flink/t3 \
--database default \
--table t3_flink \
--user atguigu \
--pass atguigu \
--partitioned-by age \
--sync-mode hms \
--jdbc-url thrift://hadoop1:9083