前言:
在日常数据处理时,我们通过变量传参来完成某个日期的数据转换。但可能因程序或者网络原因导致某个时间段的数据抽取失败。常见导致kettle作业失败的原因大概分为三大类,数据源异常、数据库异常、程序异常。因此面对这些异常时,怎么快速恢复批量数据,就需要利用循环来处理,指定含条件的数据,如恢复2023年1月6日至2023年2月02日的数据等等。这时有人会问为啥不直接用对应时间段过滤来恢复,但是实际的情况是,因对应抽取逻辑是按每日进行抽取,并且是某个同事编写的,他在当时考虑的可能是性能或者其他方面的原因,因此更改程序需要的时间成本或者风险相应较大。但又不想通过每次修改变量值去运行转换,如时间变量为${nydate},此时我们需要将变量分别赋值为2023-01-08、2023-01-07...2023-02-01、2023-02-02。因此我们有必要让kettle自己来处理这些结构的数据。
一、循环条件
1.1循环组件
在我们进行循环学习前,我们需要学习和循环相关的一个重要组件,“检验字段的值”,检验字段的值是实现循环的关键组件,类似for循环中的 i<100来判断什么时候终止作业。
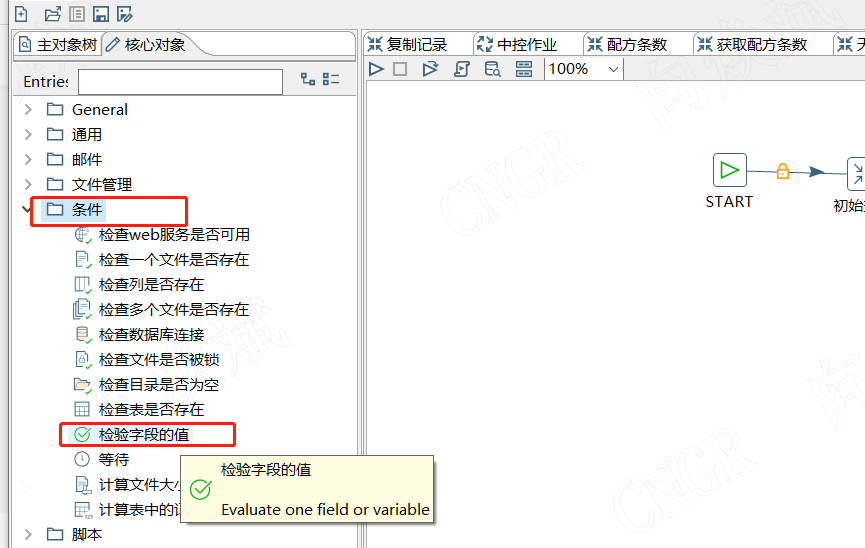
1.2检验字段的值组件介绍
检验字段的值主要包括两部分:“源”即我们判断的数据来源,一般我们使用变量或者上一步骤传过来的值,两者使用方法一致,本来来介绍一种通过的通过变量来实现循环判断。掌握了变量判断,其他的就易如反掌了。第二部就是成功条件,从字面意思就是作业能运行的条件,即我们在for循环中i<100,其中100就是对应的值,其中值建议使用变量代替,如不熟悉使用也可以使用常量来代替。

在成功条件里面还有一个“Success when variable"的选型,默认是不勾选的,它的作用,第一是用来实现无条件执行,即死循环。你不点击停止它就会一直循环运行下次,还有就是我们在调试的时候使用,有时候我们发现循环不执行了,这时候,我们可能会怀疑"源"有问题,也可能是”成功条件“有问题,此时我们勾选“Success when variable"就可以排除成功条件带来的干扰了。
二、循环案例
根据前面所述我们需将2023年1月6日至2023年2月02日的数据恢复,将我们需要将变量${nydate}的值从2023年1月6日变化至2023年2月02日。因此我们需要设置${nydate}初始值为2023年1月6日,然后通过条件判断是否满足执行条件,满足的话执行转换,执行转换后,对应变量+1,然后再判断变量值是否执行条件,再执行转换,执行转换后,对应变量+1再判断...直至变量不满足判断条件。
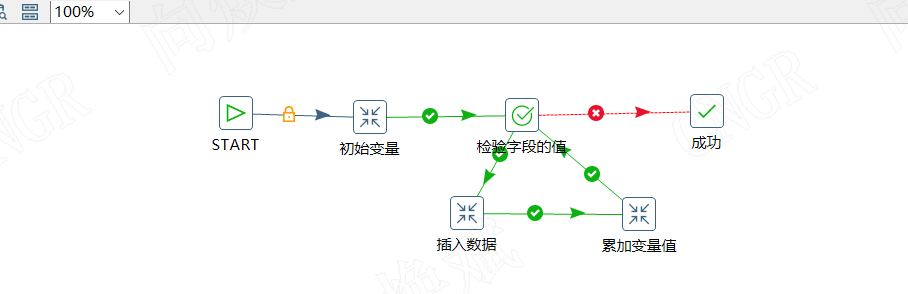
因此最后我们的作业如上图所示,包括初始变量→检验字段的值→插入数据(执行带变量的转换恢复数据等)→累计变量值→检验字段的值....累计变量值→检验字段的值→成功(不满足执行条件)
2.1初始变量
我们可以通过SQ来设置我们初始变量的值,如oracle数据库,采用如下语句来初始化变量开始日期,采用to_day 来设置变量执行的终止日期加1天(这个在后面再解释)。这样我们就给我们执行的变量赋了初始值2023年1月6日,执行的终止条件为执行至昨天的数据为止。这里根据需求灵活设置。其中变量活动类型都选择"Valid in the root job"在job中进行生效。
select '2023-01-06' startdate,to_char(sysdate,'yyyy-mm-dd') to_day from dual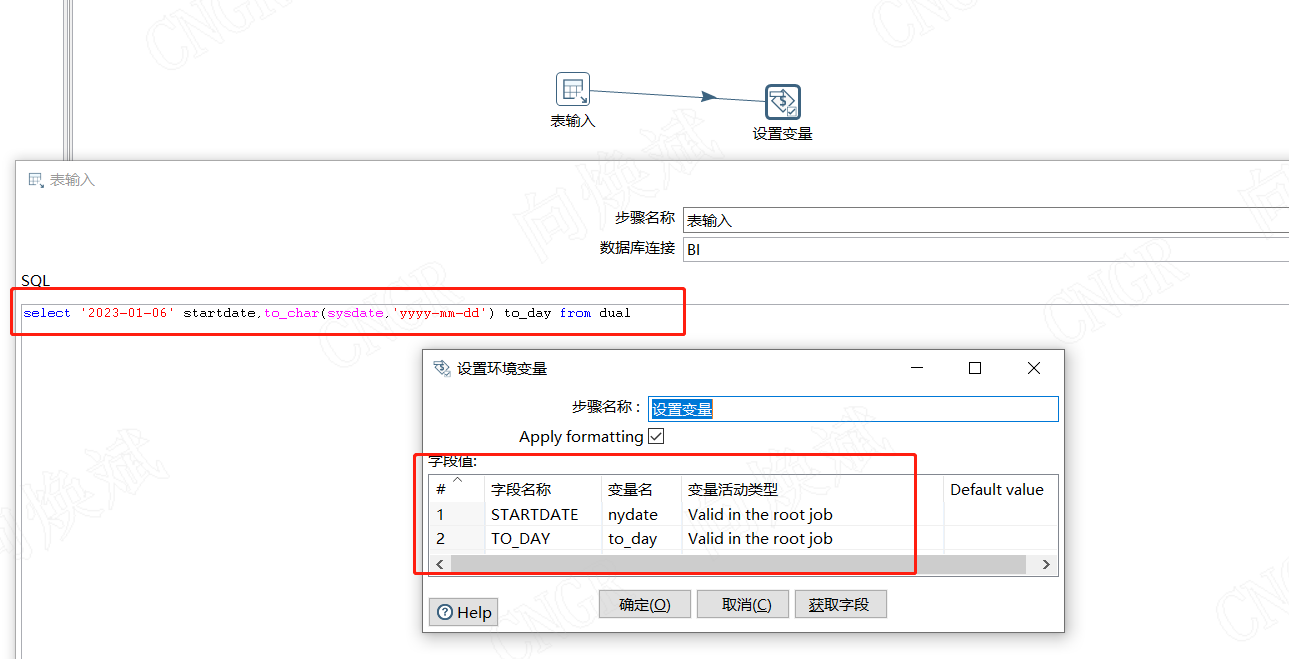
2.2循环条件
因为条件重点介绍了功能了,这里不再复述,对应我们在源,选择检验类型为变量,将初始变量的开始变量名放在对应变量名处。类似我们选择string类型即可。当然也可以选择时间类型。
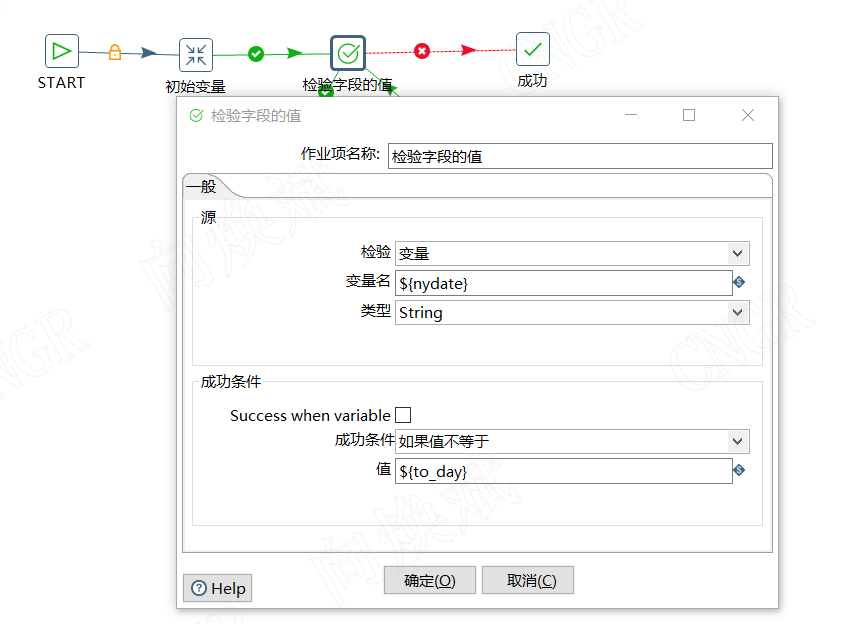
成功条件我们选择,成功条件”如果值不包含“而不要去选择”如果值不等于“因为这个判定条件存在一定的问题,这也是为啥我们初始变量的时候对应终止变量值要设置为终止日期+1天了。对应值输入我们结束的条件变量${to_day},这样我们就完成了我们循环的最关键的一步了。
2.3循环执行
循环执行主要包括循环执行的主干程序,和累计循环条件。即在本文中执行恢复2023年1月6日的数据,然后执行一次数据恢复后,将变量日期加1天。

带变量的执行转换
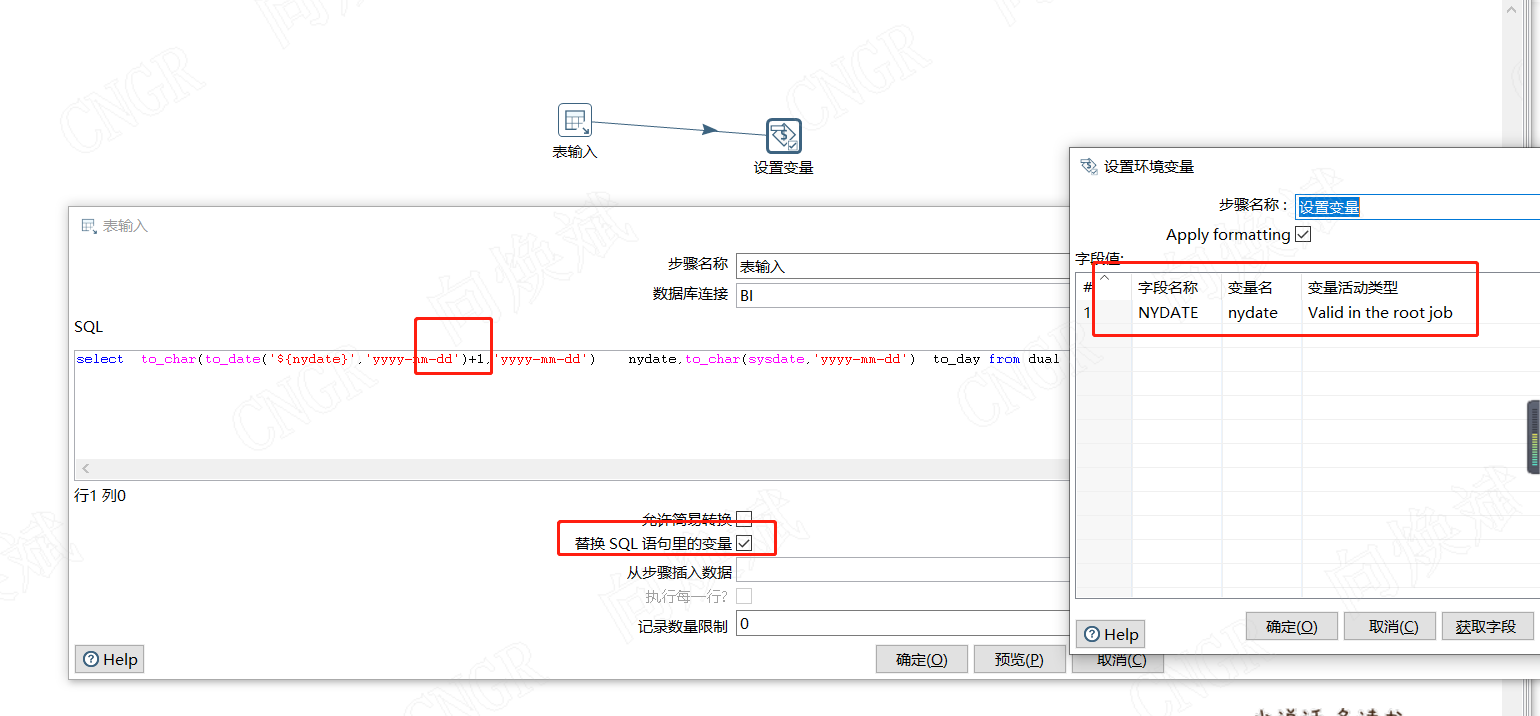
变量累计程序
2.4结束循环
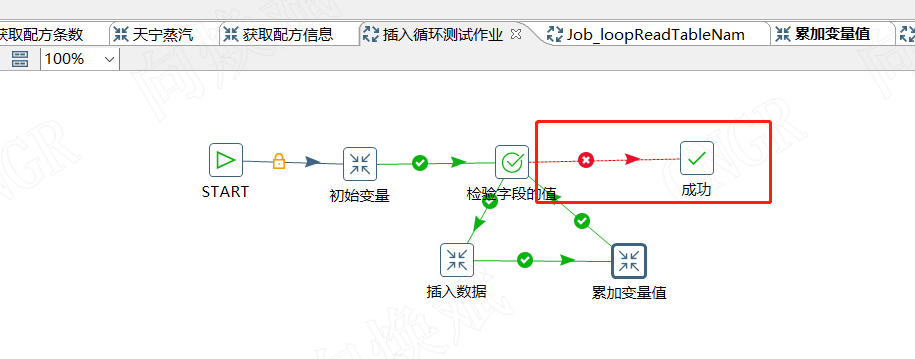
结束循环时我们可以直接用一个成功的组件也可以添加其他转换作业来完成数据转换等。
三、执行结果
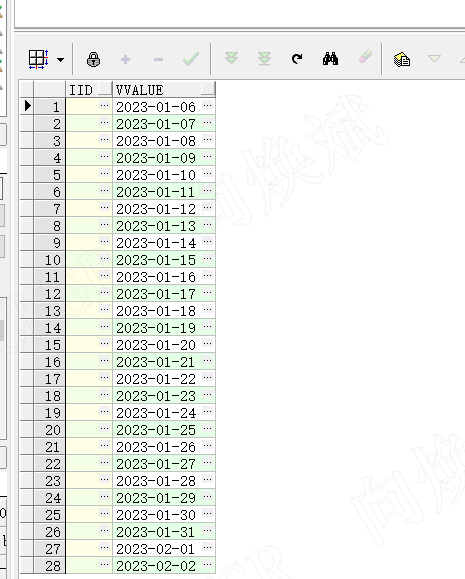
为了让大家直观的看到循环的执行效果,我将执行过程中变量的变化值保存至数据库了,如下图所示我们可以看到变量从2023-01-06变化值2023-02-02。自此我们就成功了掌握了kettle的循环了。
2023年我们继续分享kettle相关开发经验,为大家布道、助力。