https://github.com/leeguandong/KuaiZai![]() https://github.com/leeguandong/KuaiZaiAI 框架部署方案之模型部署概述 - 知乎文@小P 家的 1011010 概述模型训练重点关注的是如何通过训练策略来得到一个性能更好的模型,其过程似乎包含着各种“玄学”,被戏称为“炼丹”。整个流程包含从训练样本的获取(包括数据采集与标注),模型结构的…
https://github.com/leeguandong/KuaiZaiAI 框架部署方案之模型部署概述 - 知乎文@小P 家的 1011010 概述模型训练重点关注的是如何通过训练策略来得到一个性能更好的模型,其过程似乎包含着各种“玄学”,被戏称为“炼丹”。整个流程包含从训练样本的获取(包括数据采集与标注),模型结构的…![]() https://zhuanlan.zhihu.com/p/367042545AI 框架部署方案之模型转换 - 知乎文@ 小P家的0027200 前言模型转换是模型部署的重要环节之一,本文会从深度学习训练框架的角度出发,讲一讲作者本人对模型转换的理解。 1 模型转换的意义模型转换是为了模型能在不同框架间流转。在实际应用时,模型…
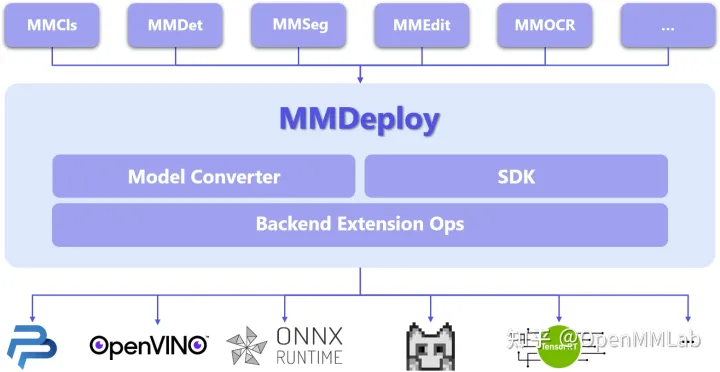
https://zhuanlan.zhihu.com/p/367042545AI 框架部署方案之模型转换 - 知乎文@ 小P家的0027200 前言模型转换是模型部署的重要环节之一,本文会从深度学习训练框架的角度出发,讲一讲作者本人对模型转换的理解。 1 模型转换的意义模型转换是为了模型能在不同框架间流转。在实际应用时,模型…![]() https://zhuanlan.zhihu.com/p/396781295模型部署入门教程(一):模型部署简介 - 知乎本文作者知乎ID:周弈帆前言OpenMMLab 的算法如何部署?是很多社区用户的困惑。而 模型部署工具箱 MMDeploy 的开源,强势打通了从算法模型到应用程序这 "最后一公里"!今天我们将开启模型部署入门系列教程…
https://zhuanlan.zhihu.com/p/396781295模型部署入门教程(一):模型部署简介 - 知乎本文作者知乎ID:周弈帆前言OpenMMLab 的算法如何部署?是很多社区用户的困惑。而 模型部署工具箱 MMDeploy 的开源,强势打通了从算法模型到应用程序这 "最后一公里"!今天我们将开启模型部署入门系列教程…![]() https://zhuanlan.zhihu.com/p/477743341
https://zhuanlan.zhihu.com/p/477743341
老潘的AI部署以及工业落地学习之路 - 知乎原文来源于 老潘的博客:老潘的AI部署以及工业落地学习之路Hello我是老潘,好久不见各位。 最近在复盘今年上半年做的一些事情,不管是 训练模型、部署模型搭建服务,还是写一些组件代码,零零散散是有一些产出。虽…![]() https://zhuanlan.zhihu.com/p/386488468
https://zhuanlan.zhihu.com/p/386488468
https://ai.baidu.com/ai-doc/EASYEDGE/yk3fj850y![]() https://ai.baidu.com/ai-doc/EASYEDGE/yk3fj850y训练侧可以使用openmmlab、paddle去训练,只要能转成onnx就可以,paddle有paddle2onnx工具,pytorch可以原生转onnx,有onnx之后,非常建议用onnxruntime的c++推理去三端运行模型。
https://ai.baidu.com/ai-doc/EASYEDGE/yk3fj850y训练侧可以使用openmmlab、paddle去训练,只要能转成onnx就可以,paddle有paddle2onnx工具,pytorch可以原生转onnx,有onnx之后,非常建议用onnxruntime的c++推理去三端运行模型。
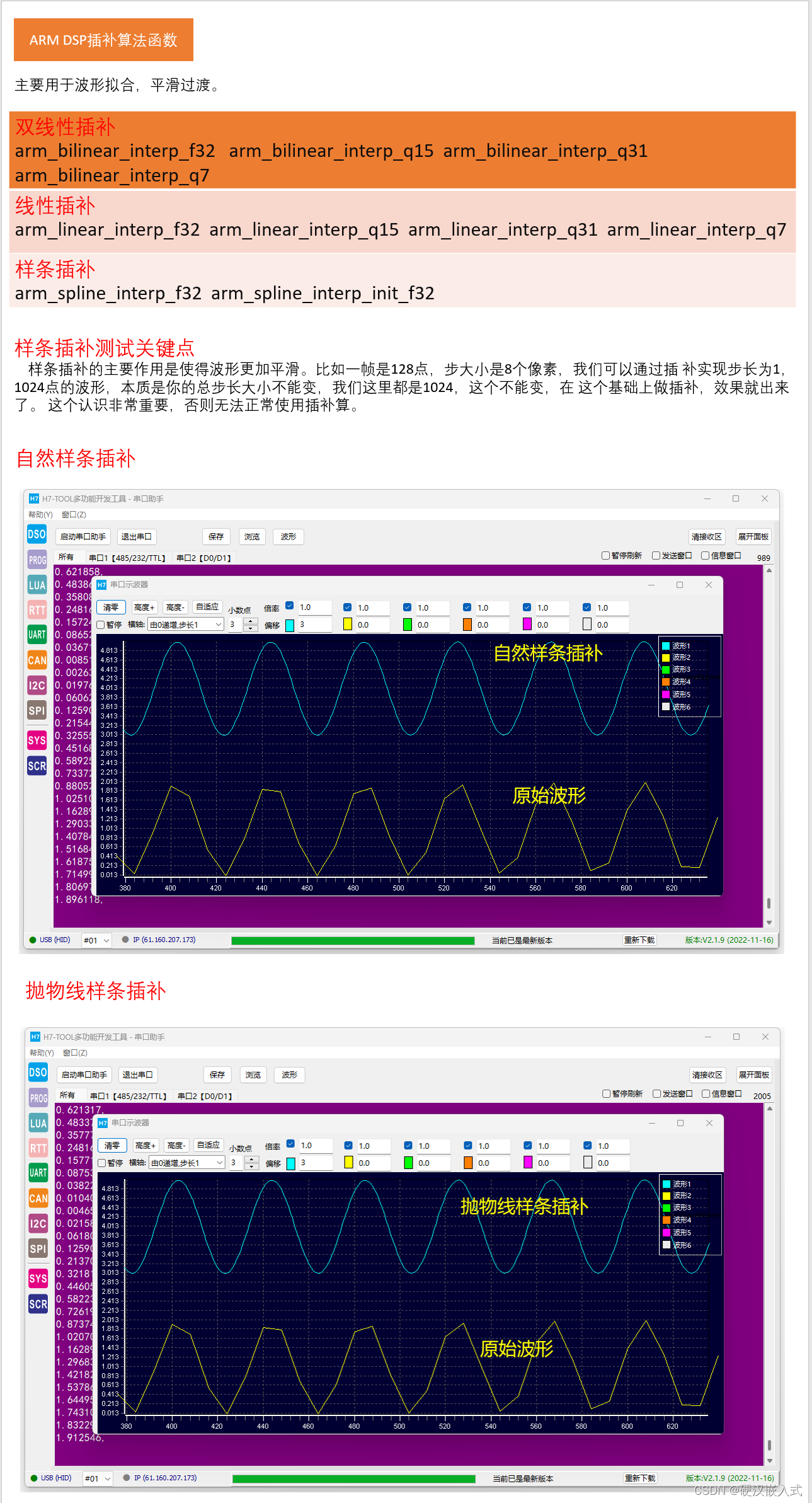
1. 模型部署综述
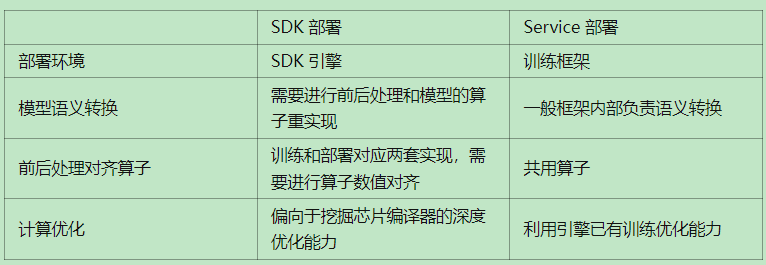
这个问题主要源于中心服务器云端部署和边缘部署两种方式的差异,云端部署常见的模式是,模型部署在云端服务器,用户通过网页访问或者 API 接口调用等形式向云端服务器发出请求,云端收到请求后处理并返回结果。 边缘部署则主要用于嵌入式设备,主要通过将模型打包封装到 SDK,集成到嵌入式设备,数据的处理和模型推理都在终端设备上执行。
针对上面提到的两种场景,分别有两种不同的部署方案,Service 部署和 SDK 部署。 Service 部署:主要用于中心服务器云端部署,一般直接以训练的引擎库作为推理服务模式。 SDK 部署:主要用于嵌入式端部署场景,以 C++ 等语言实现一套高效的前后处理和推理引擎库(高效推理模式下的 Operation/Layer/Module 的实现),用于提供高性能推理能力。此种方式一般需要考虑模型转换(动态图静态化)、模型联合编译等进行深度优化。

在数据中心服务场景,对于功耗的约束要求相对较低,在边缘终端设备场景,硬件的功耗会影响边缘设备的电池使用时长。一般会用NPU等专用优化的加速器单元来处理神经网络等高密度计算,能节省大量功耗。
云端相对更加关注的是多路的吞吐量优化需求,而终端场景则更关注单路的延时需要。CV多选择INT4/INT8,NLP选择FP16。
1.1 模型转换
模型转换可为计算图生成和计算图转换两大步骤,计算图生成是指框架通过一次inference记录执行算子的类型,输入输出,超参,参数和调用该算子的模型层次,最后把inference过程中得到的算子信息和模型信息结合得到最终的静态计算图。计算图生成的本质是把动态图模型静态表达出来,pytorch的torchscript、onnx、fx模块都是基于模型静态表达来开发的。
计算图转换是指分析静态计算图的算子对应转换到各种目标格式,这个步骤其实在pytorch中是被封装好的,在torch.onnx.export中,其中在计算图生成之后和计算图转换之前,可以进行计算图优化,例如去除冗余op等,这里一般指的是onnsim之类的库,目前这块可能没有那么复杂了,有pytorch2onnx和pytorch2tensorrt等各种库,只要转成onnx就是可以的。
用户的一些非框架底层的计算,训练框架自身是无法追踪到的,在计算图中需要自定义算子。
1.2 量化压缩
量化过程主要是将原始浮点FP32训练出来的模型压缩到定点INT8(或者INT4)的模型,由于INT8只需要8比特来表示,因此相对于32比特浮点数,压缩率可以到1/4。大部分终端设备都会有专用的定点计算单元,通过低比特指令实现的低精度算子,速度上会有大的提升。
量化的技术栈主要分为量化训练(QAT, Quantization Aware Training)和离线量化(PTQ, Post Training Quantization), 两者的主要区别在于,量化训练是通过对模型插入伪量化算子(这些算子用来模拟低精度运算的逻辑),通过梯度下降等优化方式在原始浮点模型上进行微调,从来调整参数得到精度符合预期的模型。离线量化主要是通过少量校准数据集(从原始数据集中挑选 100-1000 张图,不需要训练样本的标签)获得网络的 activation 分布,通过统计手段或者优化浮点和定点输出的分布来获得量化参数,从而获取最终部署的模型。几乎各个框架都提供了自己的量化函数。paddle有paddleslim。
1.3 模型打包SDK
模型打包,并进行SDK封装。

模型训练:pytorch、paddle、mm系列...
模型转换:torch.onnx.export、paddle2onnx等
模型压缩量化:paddleslim、各个框架也支持量化
模型部署:paddleInference、paddlelite、ncnn、onnxruntime、tensorrt、fastdeploy、mmdeploy、