这是栖落的电影网站地址:https://xxx.xxx
进入网页,显示:
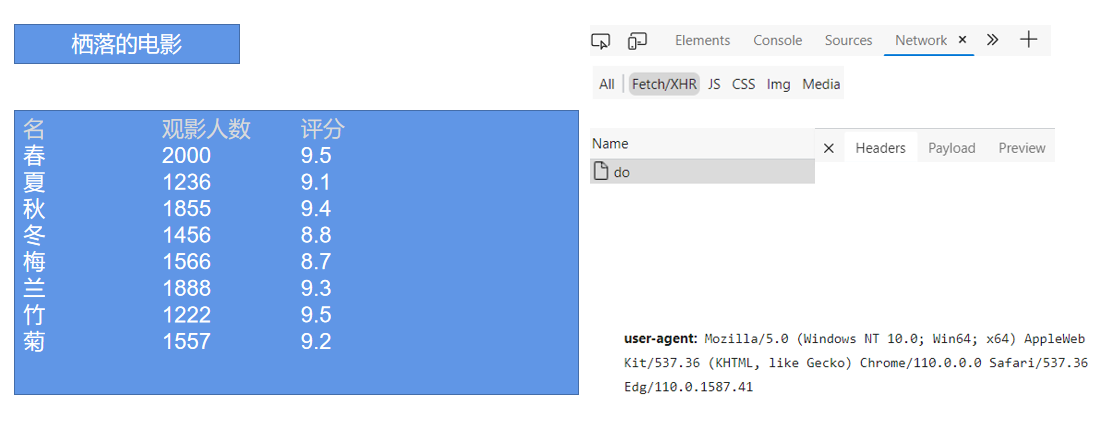
爬取目标:电影的名称、观影人数和评分。
易知本网站的url
url = "https://xxx.xxx"
本网站会识别出headers中的python请求而拒绝访问,所以需要更改headers当中的信息
user-agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41
对应的代码为:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41"
}
选中目标
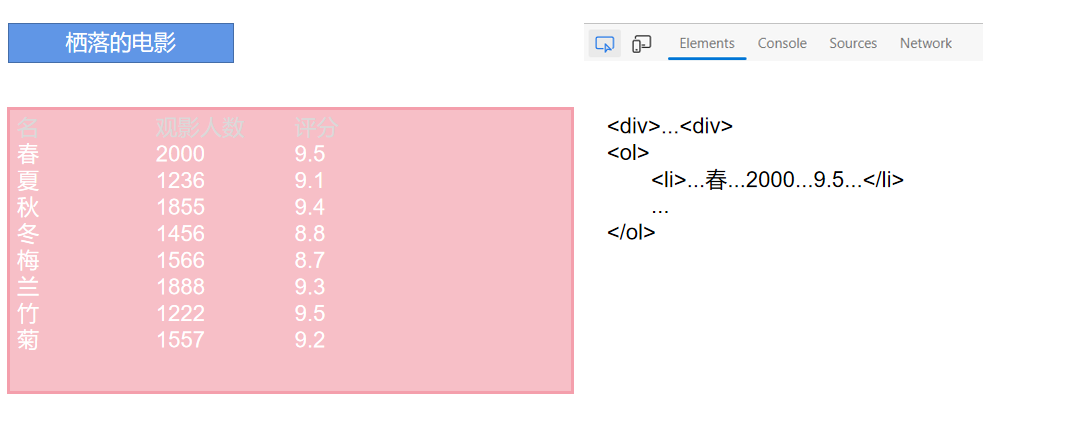
利用正则表达式匹配相应的信息。
obj = re.compile(r'<li>.*?标志1.*?标志2.*?标志1.*?标志2.*?标志1.*?标志2.*?</li>',re.S)
红色的.*?匹配需要的信息,其余的过滤掉多余的信息,各个标志为.*?的左右端的关键信息,r为requests模块返回的text文本。
并且我们需要为匹配的信息赋予相应的意义,即名、观影人数和评分。
利用(?<别名>)
obj = re.compile(r'<li>.*?标志1(?P<name>.*?)标志2.*?标志1(?P<num>.*?)标志2.*?标志1<?P<score>.*?)标志2.*?</li>',re.S)
把匹配的对象放入list中以便遍历。
result = obj.finditer(r)
遍历且以一定格式输出。
for it in result:
print("{:<10s}{:<5s{<5s}".format(it.group("name"),it.group("num"),it.group("score")))
参考代码:
import requests
import re
#获取页面信息
url = "https://xxx.xxx"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41"
}
r = requests.get(url,headers=headers)
r = r.text
#print(r)
#解析页面
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<num>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</li>',re.S)
#匹配
result = obj.finditer(r)
#输出
for it in result:
print("{:<10s}{:<5s{<5s}".format(it.group("name"),it.group("num"),it.group("score")))
输出结果:
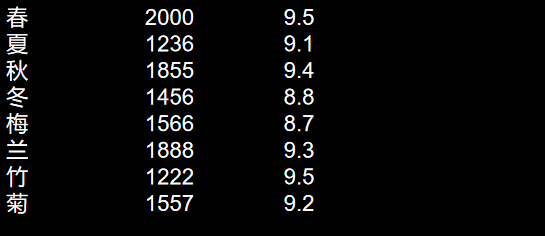
小结:
如何爬取本站?
- 确定url
- 更改headers
- 请求页面信息
- 正则匹配
- 输出
提问 :
re.compile是啥?
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象。
语法格式如下:re.compile(pattern,[flags])
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I :忽略大小写
- re.L :表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M :多行模式
- re.S :即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U :表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X :为了增加可读性,忽略空格和 # 后面的注释
finditer是啥?
finditer 返回一个可迭代对象