8.5 Spark 基本概念
Spark Application运行时,涵盖很多概念,主要如下表格:

官方文档:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary
- Application:指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码;
- Driver:Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
- Cluster Manager:指的是在集群上获取资源的外部服务,Standalone模式下由Master负责,Yarn模式下ResourceManager负责;
- Executor:是运行在工作节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执行分区计算任务的进程;
- RDD:Resilient Distributed Dataset弹性分布式数据集,是分布式内存的一个抽象概念;
- DAG:Directed Acyclic Graph有向无环图,反映RDD之间的依赖关系和执行流程;
- Job:作业,按照DAG执行就是一个作业,Job==DAG;
- Stage:阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet任务集;
- Task:任务,运行在Executor上的工作单元,1个Task计算1个分区,包括pipline上的一系列操作;
8.6 Spark 并行度
Spark作业中,各个stage的task数量,代表了Spark作业在各个阶段stage的并行度!
资源并行度与数据并行度
在Spark Application运行时,并行度可以从两个方面理解:
1)、资源的并行度:由节点数(executor)和cpu数(core)决定的
2)、数据的并行度:task的数据,partition大小
- task又分为map时的task和reduce(shuffle)时的task;
- task的数目和很多因素有关,资源的总core数,spark.default.parallelism参数,spark.sql.shuffle.partitions参数,读取数据源的类型,shuffle方法的第二个参数,repartition的数目等等。
如果Task的数量多,能用的资源也多,那么并行度自然就好。如果Task的数据少,资源很多,有一定的浪费,但是也还好。如果Task数目很多,但是资源少,那么会执行完一批,再执行下一批。所以官方给出的建议是,这个Task数目要是core总数的2-3倍为佳。如果core有多少Task就有多少,那么有些比较快的task执行完了,一些资源就会处于等待的状态。
设置Task数量
将Task数量设置成与Application总CPU Core 数量相同(理想情况,150个core,分配150 Task)官方推荐,Task数量,设置成Application总CPU Core数量的2~3倍(150个cpu core,设置task数量为300~500)与理想情况不同的是:有些Task会运行快一点,比如50s就完了,有些Task可能会慢一点,要一分半才运行完,所以如果你的Task数量,刚好设置的跟CPU Core数量相同,也可能会导致资源的浪费,比如150 Task,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个CPU Core空闲出来了,导致浪费。如果设置2~3倍,那么一个Task运行完以后,另外一个Task马上补上来,尽量让CPU Core不要空闲。
设置Application的并行度
参数spark.defalut.parallelism默认是没有值的,如果设置了值,是在shuffle的过程才会起作用。

案例说明
当提交一个Spark Application时,设置资源信息如下,基本已经达到了集群或者yarn队列的资源上限:
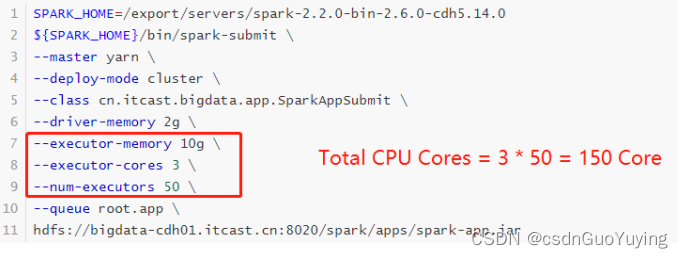
Task没有设置或者设置的很少,比如为100个task ,平均分配一下,每个executor 分配到2个task,每个executor 剩下的一个cpu core 就浪费掉了!
虽然分配充足了,但是问题是:并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源。可以调整Task数目,按照原则:Task数量,设置成Application总CPU Core数量的2~3倍

实际项目中,往往依据数据量(Task数目)配置资源。
附录:Maven 依赖
在Maven Project中创建Maven Model,依赖pom.xml添加如下依赖:
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client 依赖 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>