- Java后端-学习路线-笔记汇总表【黑马程序员】
- ElasticSearch-学习笔记01【ElasticSearch基本介绍】【day01】
- ElasticSearch-学习笔记02【ElasticSearch索引库维护】
- ElasticSearch-学习笔记03【ElasticSearch集群】
- ElasticSearch-学习笔记04【Java客户端操作索引库】【day02】
- ElasticSearch-学习笔记05【SpringDataElasticSearch】
目录
day01
ES简介
ES启动方法
ES与关系型数据库的通俗比较
映射mapping
集群cluster
节点node
ElasticSearch的客户端操作
Postman工具
ElasticSearch的接口语法
ES查询数据的三种方式
1、根据id查询
2、根据关键词查询(term查询)
3、根据字符串查询(querystring查询)
集群概念
ES集群搭建
day02
day01
ES简介
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)。
ES启动方法
1、启动ES服务:点击ElasticSearch下的bin目录下的elasticsearch.bat,http://localhost:9200,通过浏览器访问ElasticSearch服务器。
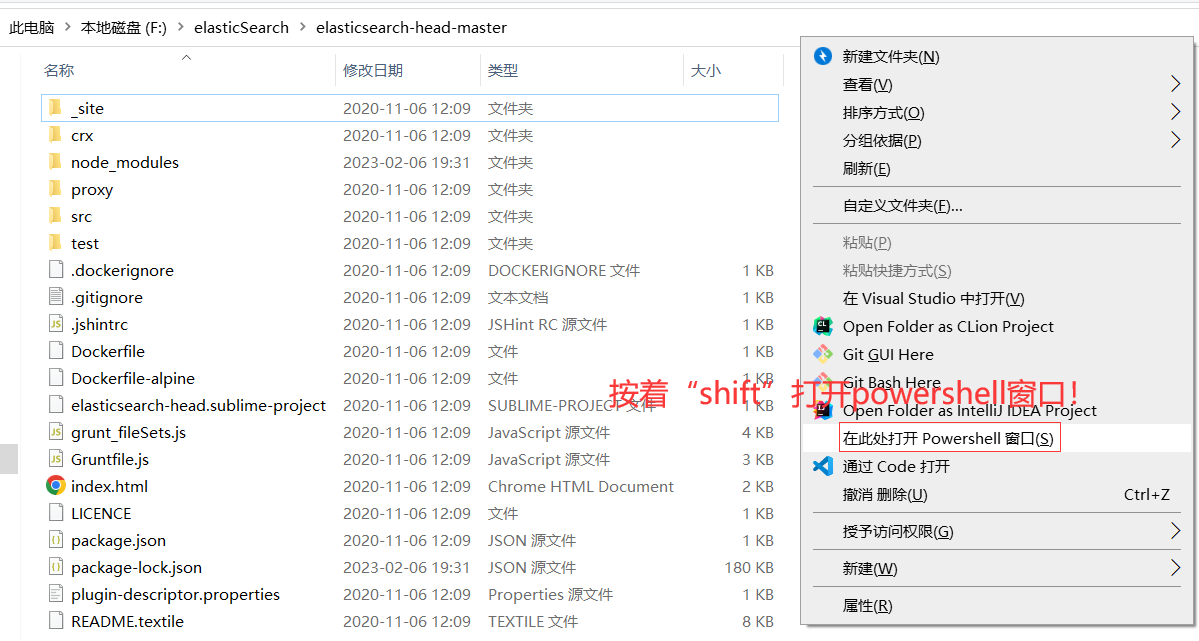
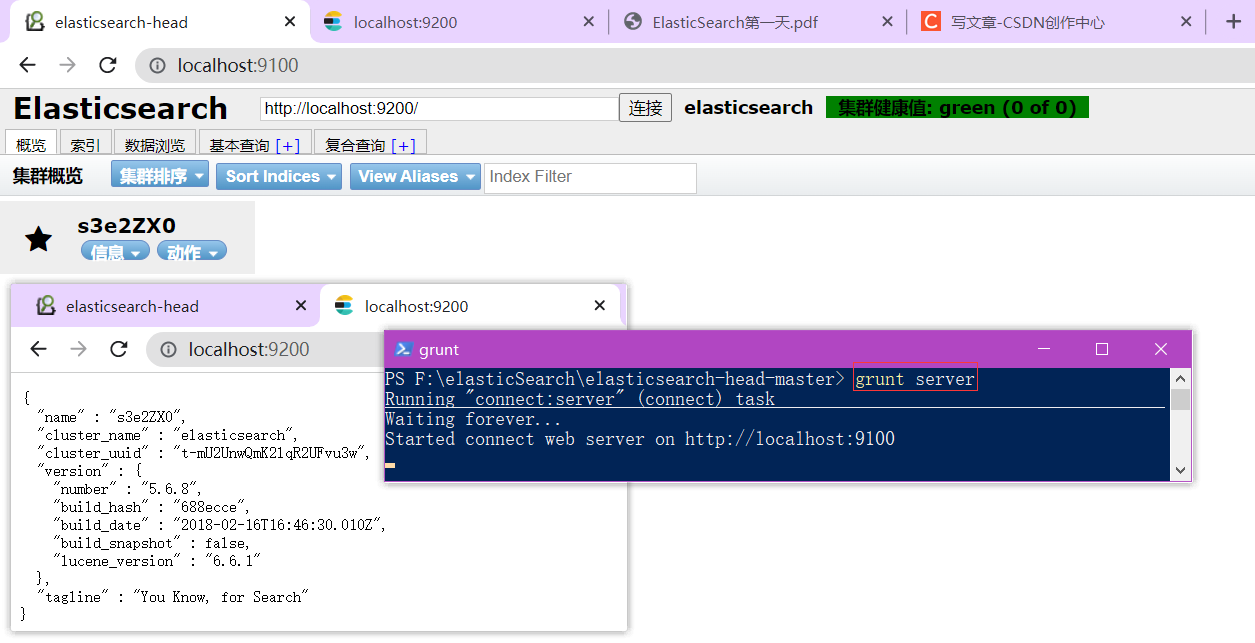
2、在head中按“shift”键打开powershell,输入“grunt server”启动——http://localhost:9100。
通过安装ElasticSearch的head插件,完成图形化界面的效 果,完成索引数据的查看。
ES与关系型数据库的通俗比较
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:
es集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档(数据)包含多个字段(Fields)(列)。

映射mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
集群cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
ElasticSearch的客户端操作
实际开发中,主要有三种方式可以作为elasticsearch服务的客户端:
- 第一种,elasticsearch-head插件;
- 第二种,使用elasticsearch提供的Restful接口直接访问;
- 第三种,使用elasticsearch提供的API进行访问。
Postman工具
Postman中文版是postman这款强大网页调试工具的windows客户端,提供功能强大的Web API & HTTP请求调试。软件功能非常强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman中文版能够发送任何类型的HTTP请求 (GET, HEAD, POST, PUT..),且可以附带任何数量的参数。
ElasticSearch的接口语法

增删改查:get、post、put、delete。
- 查询数据:GET
- 修改数据:POST
- 增加数据:PUT
- 删除数据:DELETE
设置映射mappings
{
"mappings": {
"article": {//type名称,相当于表,type可以有多个。hello
"properties": {//属性,字段
"id": {//字段1
"type": "long",
"store": true,
"index": "not_analyzed"//默认不索引
},
"title": {//字段2
"type": "text",
"store": true,
"index": "analyzed",
"analyzer": "standard"//标准分词器
},
"content": {//字段3
"type": "text",//文本类型
"store": true,//存储
"index": "analyzed",//要索引
"analyzer": "standard"//标准分词器
}
}
}
}
}http://127.0.0.1:9200/blog/hello/_mappings
- blog:索引名称
- hello:type名称
- _mappings:设置mappings
请求url:POST localhost:9200/blog/hello/1
- blog:index(索引,类似于数据库)
- hello:type(表)
- 1:文档id
请求体:
{
"id": 1,
"title": "新添加的文档",
"content": "新添加的文档的内容。"
}
ES查询数据的三种方式
三种查询方式:
- 根据id查询
- 根据关键词查询
- 根据字符串查询
1、根据id查询
GET localhost:9200/blog1/article/1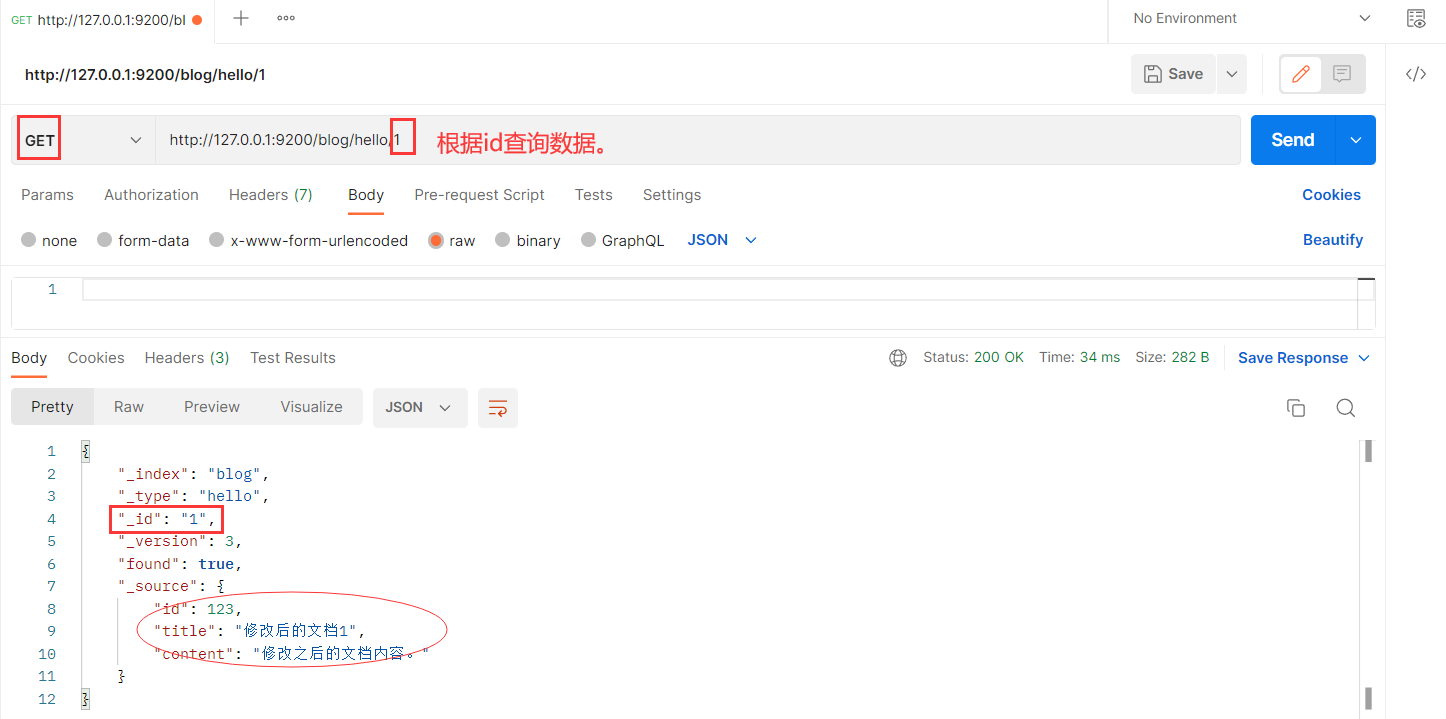
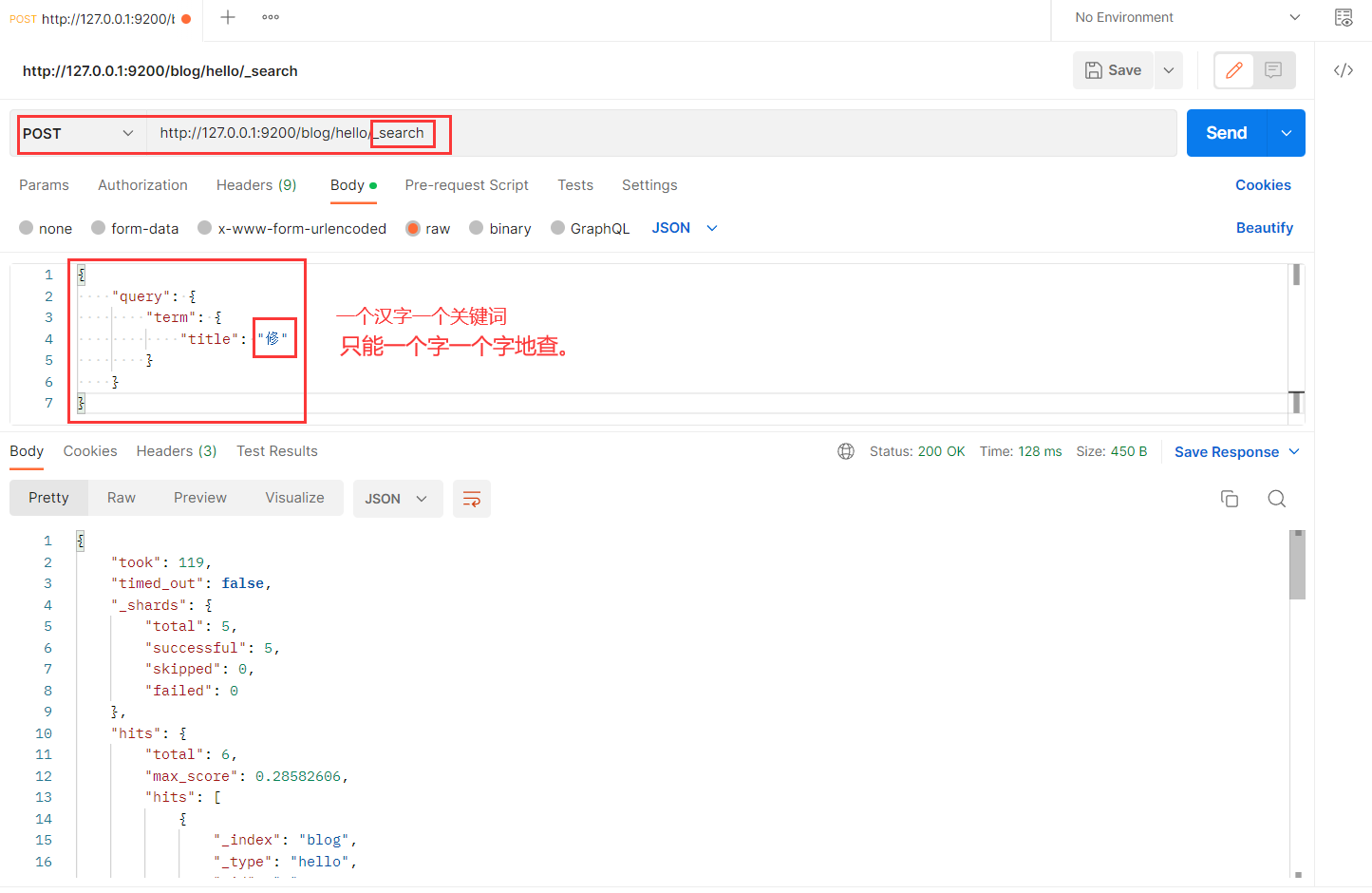
2、根据关键词查询(term查询)
POST localhost:9200/blog1/article/_search
{
"query": {
"term": {
"title": "修"
}
}
}
3、根据字符串查询(querystring查询)
POST localhost:9200/blog1/article/_search
{//查询文档-queryString查询
"query": {
"query_string": {//使用字符串查询
"default_field": "title",//指定默认搜索域
"query": "文档内容"//指定查询条件
}
}
}
集群概念
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
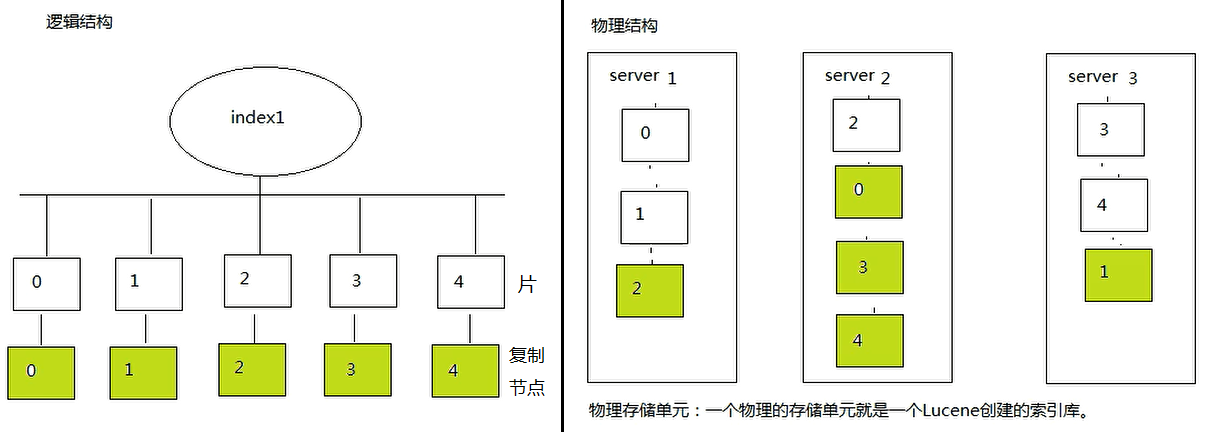
集群的逻辑结构和物理结构
ES集群搭建
ES集群搭建
- 准备三台elasticsearch服务器:创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务;
- 修改每台服务器配置:修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件。
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]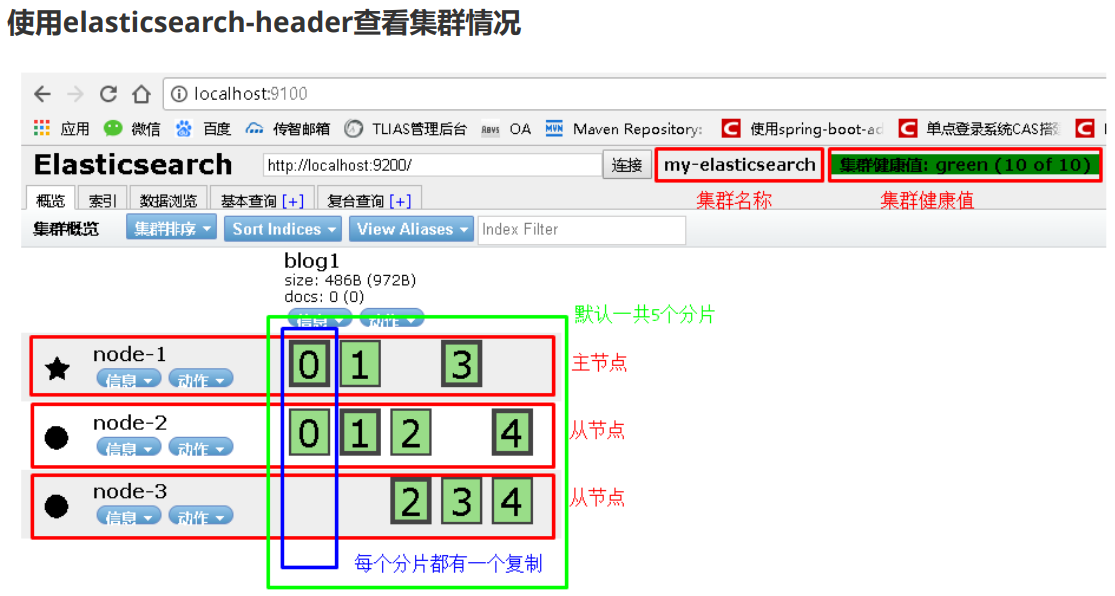
day02
一、使用Java客户端管理ES
1、创建索引库
步骤:
1)创建一个Java工程
2)添加jar包,添加maven的坐标
3)编写测试方法实现创建索引库
1、创建一个Settings对象,相当于是一个配置信息,主要用于配置集群的名称
2、创建一个客户端Client对象
3、使用client对象创建一个索引库
4、关闭client对象
2、使用Java客户端设置Mappings
步骤:
1)创建一个Settings对象
2)创建一个Client对象
3)创建一个mapping信息,应该是一个json数据,可以是字符串也可以是XContextBuilder对象
4)使用client向es服务器发送mapping信息
5)关闭client对象
3、添加文档(一行数据)
步骤:
1)创建一个Settings对象
2)创建一个Client对象
3)创建一个文档对象,创建一个json格式的字符串或者使用XContentBuilder
4)使用Client对象把文档添加到索引库中
5)关闭client
4、添加文档的第二种方式
创建一个pojo类
使用工具类把pojo转换成json字符串
把文档写入索引库二、使用ES客户端实现搜索
1、根据id搜索
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1", "2");
2、根据Term查询(关键词)
QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "北方");
3、QueryString查询方式(带分析的查询)
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("速度与激情").defaultField("title");
查询步骤:
1)创建一个Client对象
2)创建一个查询对象,可以使用QueryBuilders工具类创建QueryBuilder对象
3)使用client执行查询
4)得到查询的结果
5)取查询结果的总记录数
6)取查询结果列表
7)关闭client
4、分页的处理
在client对象执行查询之前,设置分页信息。
然后再执行查询
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
//每页显示的行数
.setSize(5)
.get();
分页需要设置两个值:from、size
from:起始的行号,从0开始。
size:每页显示的记录数
5、查询结果高亮显示
(1)高亮的配置
1)设置高亮显示的字段
2)设置高亮显示的前缀
3)设置高亮显示的后缀
(2)在client对象执行查询之前,设置高亮显示的信息
(3)遍历结果列表时可以从结果中取高亮结果三、SpringDataElasticSearch
1、工程搭建
1)创建一个java工程。
2)把相关jar包添加到工程中,如果maven工程就添加坐标。
3)创建一个spring的配置文件
1、配置elasticsearch:transport-client
2、配置elasticsearch:repositories,包扫描器,扫描dao
3、配置elasticsearchTemplate对象,就是一个bean
2、管理索引库
1、创建一个Entity类,其实就是一个JavaBean(pojo)映射到一个Document上
需要添加一些注解进行标注。
2、创建一个Dao,是一个接口,需要继承ElasticSearchRepository接口。
3、编写测试代码。
3、创建索引
直接使用ElasticsearchTemplate对象的createIndex方法创建索引,并配置映射关系。
4、添加与更新文档
1)创建一个Article对象
2)使用ArticleRepository对象向索引库中添加文档。
5、删除文档
直接使用ArticleRepository对象的deleteById方法直接删除。
6、查询索引库
直接使用ArticleRepository对象的查询方法
7、自定义查询方法
需要根据SpringDataES的命名规则来命名
如果不设置分页信息,默认带分页,每页显示10条数据。
如果设置分页信息,应该在方法中添加一个参数Pageable
Pageable pageable = PageRequest.of(0, 15);
注意:设置分页信息,默认是从0页开始。
可以对搜索的内容先分词然后再进行查询,每个词之间都是and的关系。
8、使用原生的查询条件查询
NativeSearchQuery对象。
使用方法:
1)创建一个NativeSearchQuery对象
设置查询条件,QueryBuilder对象
2)使用ElasticSearchTemplate对象执行查询
3)取查询结果