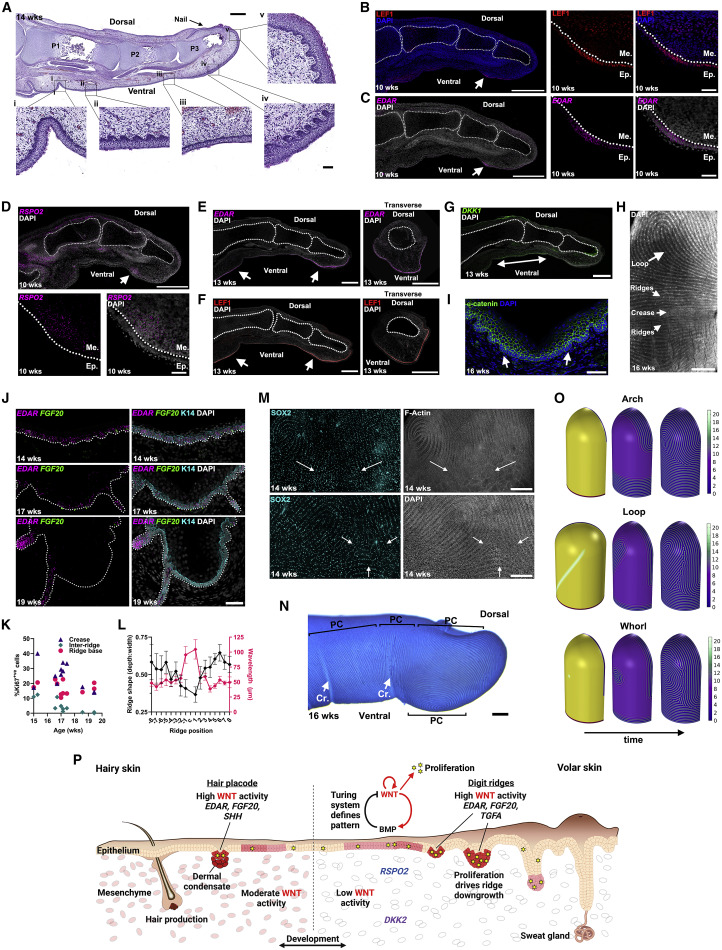
《零入门kubernetes网络实战》视频专栏地址
https://www.ixigua.com/7193641905282875942
本篇文章视频地址(稍后上传)
本篇文章主要是想模拟一下,在同一个宿主机上,多个网络命名空间之间如何通信?
有哪些可以采取的方案。
可能存在的方案:
- 方案一:使用一对veth pair将两个命名空间直接连接起来,两个命名空间处于同网段内
- 方案二:为两个命名空间分别设置自己的veth pair
- 场景一:两个命名空间处于同网段时的链接情况
- 场景二:两个命名空间处于非同网段时的链接情况
- 方案三:使用虚拟网桥将两个不同的命名空间链接起来
- 方案一:使用价值并不是很大。
- 方案二:具有一定的参考价值,为以后学期其他网络模式奠定基础
- 方案三:使用价值最高。可以同时连接多个命名空间,使其通信。
| 1、方案一:使用一对veth pair将两个命名空间直接连接起来,两个命名空间处于同网段内 |

模拟测试将veth pair的两端分别加入两个不同的网络命名空间,测试一下连通性
ip link add veth1 type veth peer name veth2
ip netns add ns1
ip netns add ns2
ip link set veth1 netns ns1
ip link set veth2 netns ns2
ip netns exec ns1 ip addr add 10.244.1.2/24 dev veth1
ip netns exec ns2 ip addr add 10.244.1.3/24 dev veth2
ip netns exec ns1 ip link set veth1 up
ip netns exec ns2 ip link set veth2 up
ip netns exec ns1 ping -c 1 10.244.1.3
ip netns exec ns2 ping -c 1 10.244.1.2


在同一个宿主机下,veth pair链接的两个网络命名空间可以通过veth pair进行互相通信
| 2、方案二:为两个命名空间分别设置自己的veth pair |
| 2.1、场景一:两个命名空间处于同网段时的链接情况 |

| 2.1.1、操作实战 |
ip link add veth1a type veth peer name veth1b
ip link add veth2a type veth peer name veth2b
ip netns add ns1
ip netns add ns2
ip link set veth1a netns ns1
ip link set veth2a netns ns2
ip addr add 10.244.1.3 dev veth1b
ip addr add 10.244.1.4 dev veth2b
ip netns exec ns1 ip addr add 10.244.1.2/24 dev veth1a
ip netns exec ns2 ip addr add 10.244.1.5/24 dev veth2a
ip link set veth1b up
ip link set veth2b up
ip netns exec ns1 ip link set veth1a up
ip netns exec ns2 ip link set veth2a up
| 2.1.2、测试 |
在执行下面的测试命令前,最好先把抓包分析的命令执行一下,
因为肯定是ping不通的。先执行抓包命令,可以观察到最初始的发包状态。
ip netns exec ns1 ping 10.244.1.5

| 2.1.3、抓包分析 |
分别对veth1a,veth1b, veth2a, veth2b进行抓包分析
| 2.1.3.1、在master节点上,进入ns1网络命名空间对veth1a |
ip netns exec ns1 tcpdump -nn -i veth1a

| 2.1.3.2、在master节点上,进入ns2网络命名空间对veth2a进行抓包 |
ip netns exec ns2 tcpdump -nn -i veth2a

| 2.1.4、在master节点上,对veth1b抓包 |
tcpdump -nn -i veth1b

| 2.1.5、在master节点上,对veth2b抓包 |
tcpdump -nn -i veth2b

从抓包情况来看,至少存在一个问题
从veth1a可以正常发送ARP数据包,并且将ARP数据包直接转发到了veth1b网卡里,
veth1b网卡也发送了同样的数据包,但是,数据包从veth1b出来后,没有对应的路由;
再查看一下,当前的路由表

| 2.1.6、设置目的路由 |
给去往10.244.1.2,10.244.1.5的数据包添加相关路由
ip route add 10.244.1.2 dev veth1b
ip route add 10.244.1.5 dev veth2b
route -n

添加完路由后,抓包情况没有发生变化,不再重复截图了。
这个时候,需要关注一下内核参数proxy_arp了。
| 2.1.7、为什么需要设置proxy_arp参数了? |
下面纯属于个人理解:
如果你了解ARP的原理,就会发现:
当veth1a发起的ARP请求到达veth1b后,veth1b网卡进行解析ARP请求,发现目的IP并非自己。
因此,我不需要回复此APR请求。
所以,程序就卡在这里了,veth1a不停的发送,Veth1b不停的丢弃。
因此,如果打破僵局的话,需要veth1b进行回复一下,代理别人回复一下。
就需要用到了proxy_arp参数了。
| 2.1.8、为veth1b设置一下proxy_arp参数 |
| 2.1.8.1、proxy_arp什么意思呢? |
是否开启arp代理,开启arp代理的话则会以自己的mac地址回复arp请求,0为不开启,1则开启。
可以参考一下,下面的网址
https://imliuda.com/post/1015
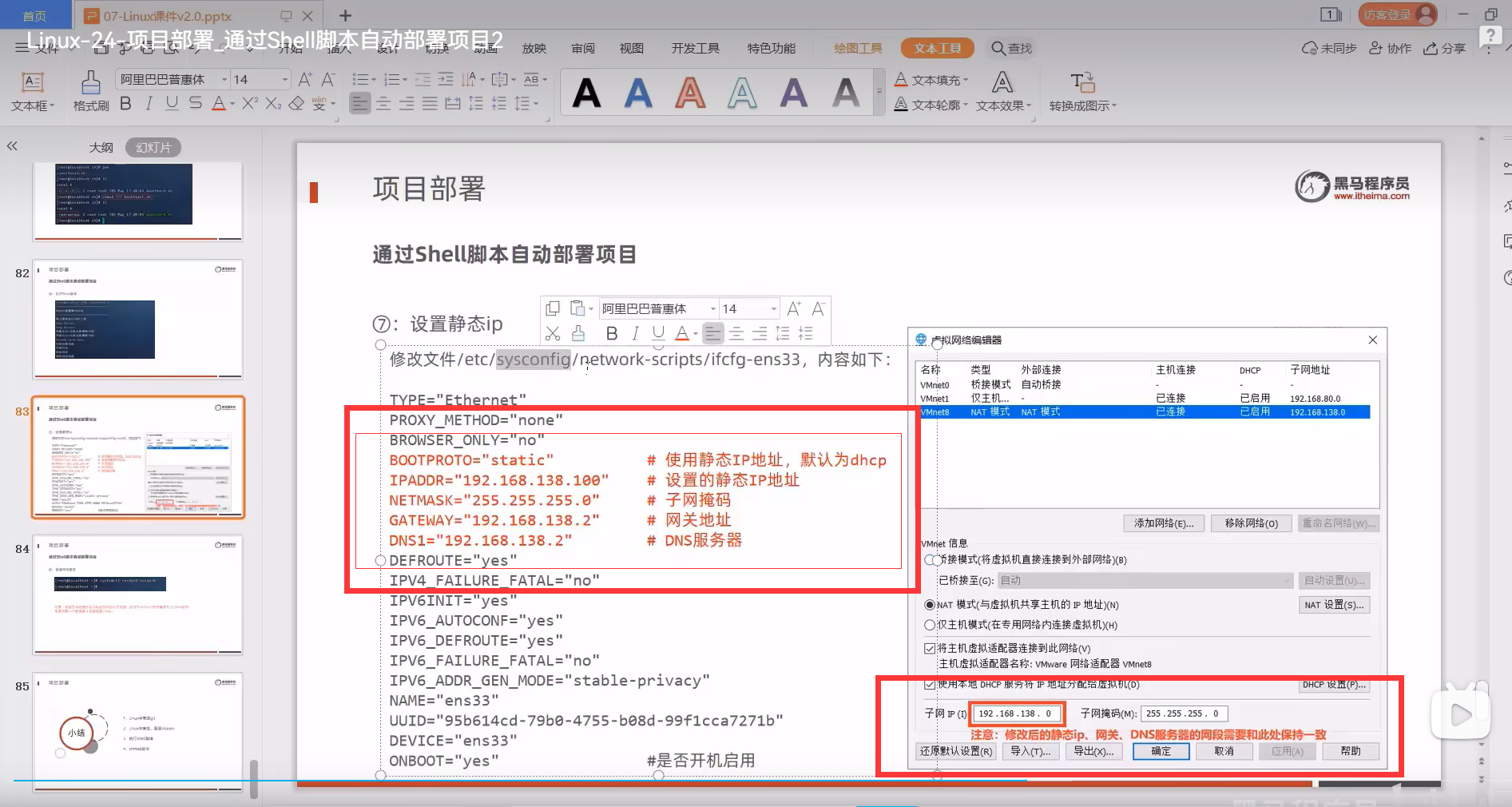
| 2.1.8.2、为veth1b网卡设置proxy_arp参数 |
在宿主机上,执行下面的命令
echo 1 > /proc/sys/net/ipv4/conf/veth1b/proxy_arp
执行完,继续观察一下各网卡的发送情况
veth1a的抓包变化

veth1b对veth1a的ARP请求,进行了回复。也就是替10.244.1.5进行了回复,
这种行为,称为代理回复。
veth1b的抓包变化

veth1a收到ARP的回复后,就立刻发起了icmp请求,并且将数据包转发给了veht1b.
veth2b

veth1b发起的数据包,经过路由判断,将数据包发送给了veth2b
| 2.1.9、为veth2b设置proxy_arp参数 |
echo 1 > /proc/sys/net/ipv4/conf/veth2b/proxy_arp

| 2.1.10、重新测试 |
ip netns exec ns1 ping 10.244.1.5

| 2.1.11、下面提供一下,完整的创建命令 |
ip link add veth1a type veth peer name veth1b
ip link add veth2a type veth peer name veth2b
ip netns add ns1
ip netns add ns2
ip link set veth1a netns ns1
ip link set veth2a netns ns2
ip addr add 10.244.1.3 dev veth1b
ip addr add 10.244.1.4 dev veth2b
ip netns exec ns1 ip addr add 10.244.1.2/24 dev veth1a
ip netns exec ns2 ip addr add 10.244.1.5/24 dev veth2a
ip link set veth1b up
ip link set veth2b up
ip netns exec ns1 ip link set veth1a up
ip netns exec ns2 ip link set veth2a up
ip route add 10.244.1.2 dev veth1b
ip route add 10.244.1.5 dev veth2b
echo 1 > /proc/sys/net/ipv4/conf/veth1b/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth2b/proxy_arp
echo 1 > /proc/sys/net/ipv4/ip_forward
测试命令
ip netns exec ns1 ping 10.244.1.5
还可以进行日志追踪设置
iptables -t raw -A PREROUTING -p icmp -j TRACE
iptables -t raw -A OUTPUT -p icmp -j TRACE
查看日志
tail -f /var/log/messages
关于/proc/sys/net/ipv4/ip_forward

你可以做一些测试,在上面测试正常的情况下,将ip_forward关闭,看看还能ping通不。
在稍微总结一下
直接看下面的图

个人理解:
是将ICMP数据包封装到IP报文里,然后,将IP报文封装到以太网帧里。
因此,veth2b其实,收到的应该是以太网帧。为了简单,图里说的是IP报文。
veth2b收到IP报文后,对IP报文头进行解析,获得源IP是10.244.1.2,目的IP是10.244.1.5
veth2b第一次向veth2a进行转发时,不知道Veth2a的MAC地址,
因此向veth2a发起了ARP请求。从上面对veth2b进行抓包分析里,可以看出来。
veth2a收到ARP请求后,会进行回复
veth2b收到veth2a的回复后,会将IP报文发送给veth2a,
veth2a收到IP报文后,会进行解析,获取ICMP数据包,并进行反馈。
但是,veth2a并不知道10.244.1.2的Mac地址,因此,它也需要发起ARP请求。
因此,接下来,就是回复过程了,跟前面介绍原理一样了。
协议的封装过程,会在后面的tap章节进行介绍。
其实,这个解释,可能经不起推敲的;因为在上面的测试用例中,当在ns1 ping宿主机上的eth0网卡时,
只添加了路由,并没有为veth1设置proxy_arp参数;
| 2.1.12、请求过程,数据包的报文内容 |
下面是master节点上的

上面是ns1网络命名空间,下面是ns2网络命名空间
下面的分析,仅供参考
- 当veth1b网卡接收到veth1a发送的数据包后,对报文进行解析
- 发现目的MAC是自己的,因此,需要接收此数据包,
- 继续解析,发现目的IP是10.244.1.5
- 查询路由,发现去往10.244.1.5,需要通过veth2b网卡发送
- 交由veth2b网卡处理,veth2b网卡发现目的IP是10.244.1.5,需要发送ARP协议,获取10.244.1.5IP对应的MAC地址
- 获取到MAC地址后,经由网络协议栈重新封装,构建新的以太网帧
- 交由veth2b网卡发送出去。
(主要是网卡的具体功能,以及跟网络协议栈调用顺序,并不是非常了解。)
| 2.1.13、请求过程,都经历了哪些iptables规则链 |
为了验证测试,需要在master节点添加日志埋点;
此过程,需要使用到rsyslog服务
| 2.1.13.1、安装rsyslog服务 |
| 2.1.13.1.1、安装rsyslog服务 |
yum -y install rsyslog
| 2.1.13.1.2、更新配置文件 |
echo "kern.* /var/log/iptables.log" >> /etc/rsyslog.conf

.*,表示所有等级的消息都添加到iptables.log文件里
信息等级的指定方式
- .XXX,表示 大于XXX级别的信息
- .=XXX,表示等于XXX级别的信息
- 如,kern.=notice /var/log/iptables.log, 将notice以上的信息添加到iptables.log里
- .!XXX, 表示在XXX之外的等级信息
| 2.1.13.1.3、重启rsyslog服务 |
systemctl restart rsyslog
systemctl status rsyslog

| 2.1.13.2、在master节点上,添加日志埋点 |
将当前的日志统计清零
iptables -t nat -Z
iptables -t filter -Z
插入日志埋点前,先查看一下,当前的现状
iptables -t nat -nvL PREROUTING --line-number
iptables -t filter -nvL FORWARD --line-number
iptables -t nat -nvL POSTROUTING --line-number
插入日志埋点
iptables -t nat -A PREROUTING -p icmp -j LOG --log-prefix "Nat-PREROUTING-1-"
iptables -t filter -A FORWARD -p icmp -j LOG --log-prefix "Filter-FORWARD-1-"
iptables -t nat -A POSTROUTING -p icmp -j LOG --log-prefix "Nat-POSTROUTING-1-"
实时查看日志
tail -f /var/log/iptables.log
| 2.1.13.3、重新发起请求 |
ip netns exec ns1 ping 10.244.1.5

再次查看日志

看上面的图,一共发送了5次请求
再看一下,iptables.log日志,一共有12条记录。
- 前4条记录,是第1次请求和反馈经过的规则链,请求经过了PREROUTING->FORWARD-POSTROUTING,反馈经过了FORWARD链
- 第5,6条记录,是第2次请求和反馈经过的规则链,请求和反馈都只经过FORWARD链
- 第7,8条记录,是第3次请求和反馈经过的规则链,请求和反馈都只经过FORWARD链
- 第9,10条记录,是第4次请求和反馈经过的规则链,请求和反馈都只经过FORWARD链
- 第11,12条记录,是第5次请求和反馈经过的规则链,请求和反馈都只经过FORWARD链
| 2.1.13.4、经历的iptables规则链 |

| 2.2、场景二:两个命名空间处于非同网段时的链接情况 |
| 2.2.1、网络拓扑 |

接下来,我们提供两种方式来实现上面的网络拓扑
| 2.2.2、操作实战一(arp代理应答方案) |
ip link add veth1a type veth peer name veth1b
ip link add veth2a type veth peer name veth2b
ip netns add ns1
ip netns add ns2
ip link set veth1a netns ns1
ip link set veth2a netns ns2
ip addr add 10.244.1.3 dev veth1b
ip addr add 10.244.2.2 dev veth2b
ip netns exec ns1 ip addr add 10.244.1.2/24 dev veth1a
ip netns exec ns2 ip addr add 10.244.2.3/24 dev veth2a
ip link set veth1b up
ip link set veth2b up
ip netns exec ns1 ip link set veth1a up
ip netns exec ns2 ip link set veth2a up
ip route add 10.244.1.2 dev veth1b
ip route add 10.244.2.3 dev veth2b
ip netns exec ns1 route add -net 10.244.2.0/24 dev veth1a
ip netns exec ns2 route add -net 10.244.1.0/24 dev veth2a
echo 1 > /proc/sys/net/ipv4/conf/veth1b/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth2b/proxy_arp
echo 1 > /proc/sys/net/ipv4/ip_forward
该方式,完全跟同网段是一样的。
从ns1里ping ns2
ip netns exec ns1 ping 10.244.2.3

从ns2里ping ns1也是可以的
ip netns exec ns2 ping 10.244.1.2
| 2.2.3、操作实战二(可以认为是路由方案) |
ip link add veth1a type veth peer name veth1b
ip link add veth2a type veth peer name veth2b
ip netns add ns1
ip netns add ns2
ip link set veth1a netns ns1
ip link set veth2a netns ns2
ip addr add 10.244.1.3 dev veth1b
ip addr add 10.244.2.2 dev veth2b
ip netns exec ns1 ip addr add 10.244.1.2/24 dev veth1a
ip netns exec ns2 ip addr add 10.244.2.3/24 dev veth2a
ip link set veth1b up
ip link set veth2b up
ip netns exec ns1 ip link set veth1a up
ip netns exec ns2 ip link set veth2a up
ip route add 10.244.1.0/24 dev veth1b
ip route add 10.244.2.0/24 dev veth2b
ip netns exec ns1 route add -net 10.244.2.0/24 gw 10.244.1.3 dev veth1a
ip netns exec ns2 route add -net 10.244.1.0/24 gw 10.244.2.2 dev veth2a
echo 1 > /proc/sys/net/ipv4/ip_forward
将宿主机作为路由器来使用。

测试,如下:
ip netns exec ns1 ping 10.244.2.3
| 2.3、方案三:使用虚拟网桥将两个不同的命名空间链接起来 |
本方案,可以参考后续的网桥相关文章
| 3、总结 |
-
如果你已经看过<<基于veth pair+snat技术实现内部网络访问本局域网的其他宿主机>>的文章后,可以思考一下,为什么在这篇文章里,没有使用proxy_arp代理转发参数呢?同样,在场景二里的操作实战二中也没有使用proxy_arp代理转发参数?
- 本篇文章里使用了proxy_arp代理转发参数,是因为?
- snat文章里,设置默认路由,并指定了网关地址,将veth1b网卡设置为网关了,当数据包去往10.211.55.0/24路由时,都会将数据包发送给网关,通过ARP是可以获取网关的MAC地址的。
- 而本篇文章里没有在ns1网络命名空间里设置默认路由,因此,当veth1a发送ARP协议获取10.244.1.5IP对应的MAC地址时,veth1b网卡虽然收到了ARP数据包,发现目的IP并非是自己,就丢弃了;因此,需要让veth1b代理回答一下arp协议。
- 本篇文章里使用了proxy_arp代理转发参数,是因为?
-
本测试用例,实际中,就是同一个节点上容器之间如何通信
可以重点关注几个事情?
是否跨网段了,是否设置了路由,指定了网关,通过哪个网卡发送出去的?
ARP协议用来干什么的?
proxy_arp代理转发?什么时候使用代理转发
网桥不用设置代理转发,应该是默认支持的。
网卡之间数据包转发时,经过了哪些链?第一次,跟第二次,,,,,经过的链是否一样?
当然,一开始,总结不好,等时间长了,做了很多练习,就会发现。
好像,来来回回,就这些东西。
只是,一开始,比较乱而已。
| 点击 下面 返回 专栏目录 |
<<零入门kubernetes网络实战>>技术专栏之文章目录




![字母板上的路径[提取公共代码,提高复用率]](https://img-blog.csdnimg.cn/dcdc077c29f14c2cac0d898ace0b53ae.png)