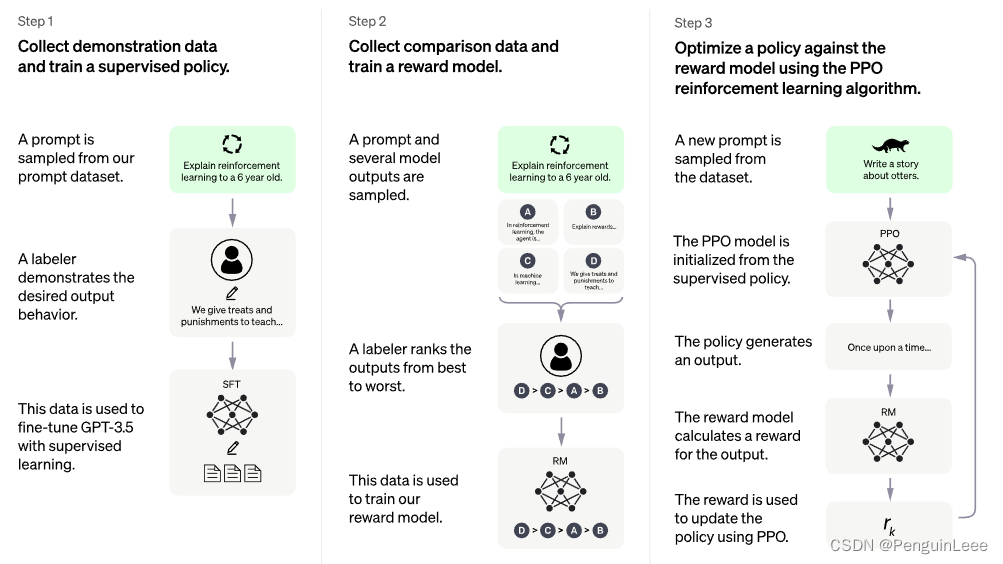
一,机器学习系统分类
机器学习系统分为三个类别,如下图所示:

二,如何处理数据中的缺失值
可以分为以下 2 种情况:
- 缺失值较多:直接舍弃该列特征,否则可能会带来较大噪声,从而对结果造成不良影响。
- 缺失值较少:当缺失值较少(
< 10%)时,可以考虑对缺失值进行填充,有几下几种填充策略:- 用一个异常值填充(比如 0 ),缺失值作为一个特征处理:
data.fillna(0) - 用均值|条件均值填充:
data.fillna(data.mean()) - 用相邻数据填充:
data.fillna(method='pad'),data.fillna(method='bfill') - 插值:
data.interpolate() - 拟合:简单来说,就是将缺失值也作为一个预测问题来处理:将数据分为正常数据和缺失数据,对有值的数据采用
随机森林等方法拟合,然后对有缺失值的数据进行预测,用预测的值来填充
- 用一个异常值填充(比如 0 ),缺失值作为一个特征处理:
三,数据清洗与特征处理
机器学习中的数据清洗与特征处理综述
美团的这篇综述文章总结得不错,虽然缺少实例不容易直观理解,但是初学者来说也足够了。
3.1,清洗标注数据
清洗标注数据的方法,主要是是数据采样和样本过滤。
数据采样:对于分类问题:选取正例,负例。对于回归问题,需要采集数据。对于采样得到的文本,根据需要设定样本权重,当模型不能使用全部的数据来训练时,需要对数据进行采样,设定一定的采样率。采样的方法包括随机采样,固定比例采样等方法。- 样本过滤:1.结合业务情况进行数据的过滤,例如去除crawler抓取,spam,作弊等数据。 - 2.异常点检测,采用异常点检测算法对样本进行分析,常用的异常点检测算法包括 - 偏差检测,例如聚类,最近邻等。
3.2,特征分类
根据不同的分类方法,可以将特征分为:
Low level特征和High level特征- 稳定特征与动态特征。
- 二值特征、连续特征、枚举特征
Low level 特征是较低级别的特征,主要是原始特征,不需要或者需要很少的人工处理和干预,例如文本中的词向量特征,图像特征中的像素点大小,用户 id,商品 id等。High level 特征是经过比较复杂的处理,结合部分业务逻辑或者规则、模型得到的特征,例如人工打分,模型打分等特征,可以用于较复杂的非线性模型。Low level 比较针对性,覆盖面小。长尾样本的预测值主要受 high level 特征影响。 高频样本的预测值主要受 low level 特征影响。
稳定特征 是变化频率较少的特征,例如评价平均分,团购单价价格等,在较长时间段内数值都不会发生变化。动态特征是更新变化比较频繁的特征,有些甚至是实时计算得到的特征,例如距离特征,2 小时销量等特征。或者叫做实时特征和非实时特征。针对两类特征的不同可以针对性地设计特征存储和更新方式,例如对于稳定特征,可以建入索引,较长时间更新一次,如果做缓存的话,缓存的时间可以较长。对于动态特征,需要实时计算或者准实时地更新数据,如果做缓存的话,缓存过期时间需要设置的较短。
二值特征主要是 0/1 特征,即特征只取两种值:0 或者 1,例如用户 id 特征:目前的 id 是否是某个特定的 id,词向量特征:某个特定的词是否在文章中出现等等。连续值特征是取值为有理数的特征,特征取值个数不定,例如距离特征,特征取值为是0~正无穷。枚举值特征主要是特征有固定个数个可能值,例如今天周几,只有7个可能值:周1,周2,…,周日。在实际的使用中,我们可能对不同类型的特征进行转换,例如将枚举特征或者连续特征处理为二值特征。枚举特征处理为二值特征技巧:将枚举特征映射为多个特征,每个特征对应一个特定枚举值,例如今天周几,可以把它转换成7个二元特征:今天是否是周一,今天是否是周二,…,今天是否是周日。连续值处理为二值特征方法:先将连续值离散化(后面会介绍如何离散化),再将离散化后的特征切分为N个二元特征,每个特征代表是否在这个区间内。
3.3,特征处理与分析
对特征进行分类后,需要对特征进行处理,常用的特征处理方法如下:
- 特征归一化,离散化,缺省值处理
- 特征降维方法
- 特征选择方法
特征归一化。在有些算法中,例如线性模型或者距离相关的模型(聚类模型、knn 模型等),特征值的取值范围会对最终的结果产生较大影响,例如输入数据有两种不同的特征,其中的二元特征取值范围 [0, 1],而距离特征取值可能是 [0,正无穷],两种特征取值范围不一致,导致模型可能会偏向于取值范围较大额特征,为了平衡取值范围不一致的特征,需要对特征进行归一化处理,将特征值取值归一化到 [0,1] 区间,常用的归一化方法包括:
函数归一化,通过映射函数将特征取值映射到[0,1]区间,例如最大最小值归一化方法,是一种线性的映射。还有通过非线性函数的映射,例如log函数等。分维度归一化,可以使用最大最小归一化方法,但是最大最小值选取的是所属类别的最大最小值,即使用的是局部最大最小值,不是全局的最大最小值。排序归一化,不管原来的特征取值是什么样的,将特征按大小排序,根据特征所对应的序给予一个新的值。
离散化。在上面介绍过连续值的取值空间可能是无穷的,为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。常用的离散化方法包括等值划分和等量划分。
等值划分,是将特征按照值域进行均分,每一段内的取值等同处理。例如某个特征的取值范围为 [0,10],我们可以将其划分为10段,[0,1),[1,2),…,[9,10)。等量划分,是根据样本总数进行均分,每段等量个样本划分为 1 段。例如距离特征,取值范围[0,3000000],现在需要切分成 10 段,如果按照等比例划分的话,会发现绝大部分样本都在第 1 段中。使用等量划分就会避免这种问题,最终可能的切分是[0,100),[100,300),[300,500),…,[10000,3000000],前面的区间划分比较密,后面的比较稀疏。
缺省值处理。有些特征可能因为无法采样或者没有观测值而缺失,例如距离特征,用户可能禁止获取地理位置或者获取地理位置失败,此时需要对这些特征做特殊的处理,赋予一个缺省值。缺省值如何赋予,也有很多种方法。例如单独表示,众数,平均值等。
四,交叉验证
交叉验证是机器学习当中的概念,一般深度学习不会使用交叉验证方法,原因是深度学习的数据集一般都很大。但是也有例外,Kaggle 的一些医疗类比赛,训练集一般只有几千张,由于训练数据很少,用来作为验证集的数据会非常少,因此训练的模型在验证集上精度可能会有很大波动,这直接取决于我们所选择的验证集和训练集划分方式,也就是说,验证集的划分方式可能会造成验证集精度存在较大方差,从而无法对模型进行有效评估,同时也无法进行有效的超参数调整(batch 设置多少模型最佳收敛)。
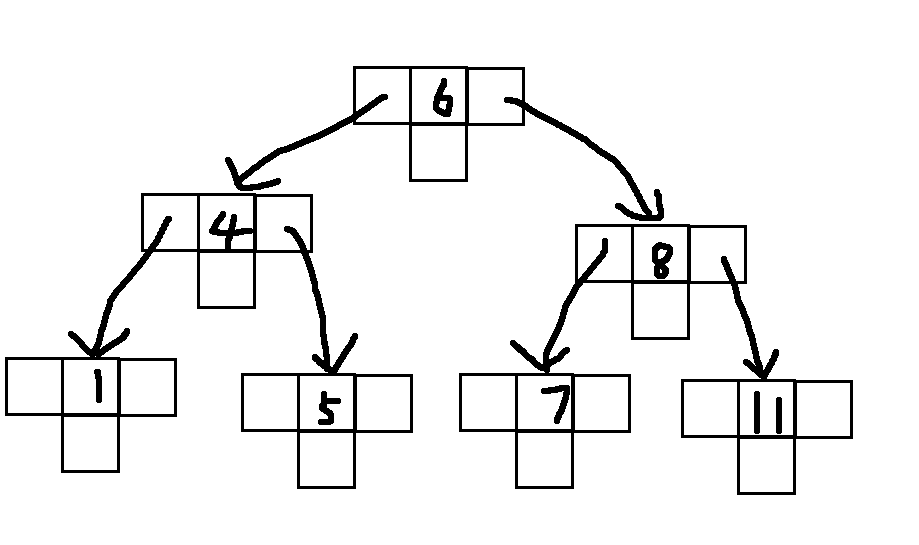
一个有效的解决办法是,在训练数据上面,我们可以进行交叉验证(Cross-Validation)·。一种方法叫做 ·K-fold Cross Validation ( K 折交叉验证), K 折交叉验证,初始采样分割成 K 个子样本,一个单独的子样本被保留作为验证模型的数据,其他 K-1 个样本用来训练。交叉验证重复 K 次,每个子样本验证一次,平均 K 次模型训练的结果,最终输出一个单一估测。k-折交叉验证的训练集划分方式如下图所示:
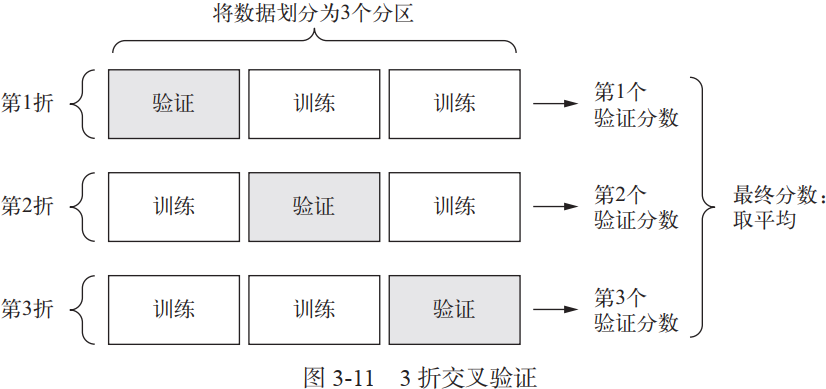
- 当
K值大的时候, 我们会有更少的Bias(偏差), 更多的Variance。 - 当
K值小的时候, 我们会有更多的Bias(偏差), 更少的Variance。
k 折交叉验证的代码实现可以参考《Python深度学习》第三章,在模型训练好后,可通过计算所有 Epoch 的 K 折验证分数的平均值,并绘制每轮的模型验证指标变化曲线,观察哪个 Epoch 后模型不再收敛,从而完成模型调参工作。同时,K 折交叉验证方式训练模型会得到 K个模型,将这个 K 个模型在测试集上的推理结果取平均值或者投票,也是一种 Ensemble 方式,可以增强模型泛化性,防止过拟合。
# 计算所有轮次中的 K 折验证分数平均值
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
参考资料
- Machine learning basics