结构体说明
GRBL里面的速度规划是带运动段前瞻的,所以有规划运动段数据和微小运动段的区分
这里的“规划运动段”对应的数据结构是plan_block_t,前瞻和加减速会使用到,也就是通过解析G代码后出来的直接直线数据或是圆弧插补出来的拟合直线数据
“微小运动段”对应的数据结构是segment_t,加减速的终端数据持有者,也就是plan_block_t数据经过了加减速后的计算数据
plan_block_t的数据还有一个临时的数据缓冲区,st_block_buffer,作用如上所述,其中存储的是脉冲发生ISR里面需要用到的数据
stepper.c里面有个静态变量static st_prep_t prep,这个变量是plan_block_t数据转换为segment_t数据时的一个缓冲,即从plan_block_t里面提取相关数据,然后生成新的segment_t数据
加减速处理
加减速处理在stepper.c的st_prep_buffer()函数里,流程为:
1.segment_t缓冲区有空余位置才会进行加减速数据生成,否则退出函数;有接收到停止运动指令,同样停止生成数据
2.从规划器的plan_block_t队列里面找到当前要进行分解的运动段,此处会分为“系统运动段”和“普通运动段”,就是一般操作和G代码解析的区分
3.判断prep里面的重新计算标志是否有效,有效则重新计算当前的运动段分解
什么时候会需要重新计算呢?一般是调整了速度修调(Ratio)之后,会对未被执行的运动段重新进行计算
4.如果不需要重新计算了,则直接把plan_block_t里面对应的Bresenham算法需要用到的脉冲输出阈值和总步数,记录到st_block_buffer里面
5.此时开始根据plan_block_t里面的数据和系统当前状态来确定加减速的状态,这里有好几个条件分支,其中牵扯到前瞻计算的初始速度和终止速度,以及系统的速度修调率。
5.1如果检测到系统有进给保持(HOLD)状态指令,则直接进入全减速状态(RAMP_DECEL)
5.2如果速度修调被降低了,则判断当前运动段的距离够不够减速到对应的终止速度,不够则进入全减速状态(RAMP_DECEL),如果是足够的,则进入半减速状态(RAMP_DECEL_OVERRIDE),如果是进入了规划的减速段,则也进入全减速状态(RAMP_DECEL)
5.3如果是速度修调被升高了,或是一开始进入加速运动,则要进入加速状态(RAMP_ACCEL)
5.4如果是加速到了目标速度,则应该进入匀速状态(RAMP_CRUISE)
5.5其中,在加速状态的时候,可以计算出要进行梯形加减速还是三角形加减速
6.在确定了当前运动段的加减速状态后,则根据该状态进行segment_t微小运动段的分解计算,分解计算是依靠一个固定的时基DT_SEGMENT来进行的
注意,该固定时基只在计算segment_t数据时使用,跟脉冲发生的时间没有直接关系
7.分解微小运动段的方法是:根据加减速状态和pl_block的速率,算出在DT_SEGMENT单元时间内的进给量(即应输出的脉冲量)
7.1半减速处理(RAMP_DECEL_OVERRIDE):首先计算减速到目标速度的时间,然后算出减速状态下的进给,再把加减速状态设置为匀速状态(RAMP_CRUISE),剩下的时间会在循环条件里再次进入匀速状态计算进给
7.2全加速处理(RAMP_ACCEL):计算全加速下,是否会到达运动段的加速段目标位置,如果还可以加速,则继续处于全加速状态,否则看加减速是梯形条件还是三角形条件,如果是梯形则进入匀速状态(RAMP_CRUISE),如果是三角形则进入全减速状态(RAMP_DECEL)
7.3匀速处理(RAMP_CRUISE):计算匀速段是否结束了,是则进入全减速状态(RAMP_DECEL),否则保持该状态;另外,如果匀速状态在DT_SEGMENT时间内就结束了,同样地,把剩余时间在全减速状态再计算一次进给量
7.4全减速处理(RAMP_DECEL):如果剩余的距离还可以继续减速,则保持该状态,然后计算出该次的进给量;如果剩余的距离可以在该次减速中完成,则要算出完成减速的时间量和进给量,然后退出该运动段pl_block的加减速
7.5另外,加减速处理中有“最小步”的输出要求,如果在1个DT_SEGMENT内,没有达到“最小步”的要求,则继续累加1个DT_SEGMENT的时间,知道满足“最小步”输出要求,才退出步骤7
8.要注意的是,步骤5是segment_t根据pl_block_t的状态初始化自己数据的流程,里面有步骤7计算时需要用到的初始数据
步骤7是计算一个完整segment_t数据的流程,里面有输出脉冲的条件数据,比如在多长的时间内输出多少个脉冲
然后就是初始化T1定时器计数,并且触发ISR,在ISR中计算脉冲输出条件
9.另外,1个pl_block_t可以分解成很多个segment_t,如果segment_t的缓冲满了,pl_block_t还没有结束,则暂停生成segment_t,等缓冲区空闲了再计算,否则会一直生成segment_t;
相反,也有可能1个pl_block_t就对应1个segment_t,且segment_t可能会在DT_SEGMENT内就完成了pl_block_t的目标距离,时间是以实际计算的为准
10.脉冲输出的时基,即T1定时器的溢出中断计数,是根据segment_t的需要输出脉冲数和segment_t使用的时间(不一定是DT_SEGMENT)来直接计算的。在单个segment_t的脉冲输出期间,T1的溢出中断时间间隔一致,但一般不同的segment_t会有不同的T1时间间隔
pl_block->step_event_count 是完成这个block所需走的步数,就是steps[x], steps[y], steps[z], 的最大值,即是三个轴中的最长轴。如果某个轴是最长轴,意味着这个轴的步进电机每个中断都有脉冲输出。
其他轴按照DDA算法输出
所谓的DDA算法如下
假设从P0点(0,0,0)插补到P1点(2,4,8),坐标分别对应X,Y,Z,则最长轴是Z,每个周期应该Z步数增加1个单位,总共需要8个周期
再假设event_step = 8,step_x = 2,step_y = 4,step_z = 8,cnt_x = cnt_y = cnt_z = 0;
要Z每个周期都输出脉冲,则有:
cnt_x += step_x;
if (cnt_x >= event_step) {输出X脉冲,cnt_x -= event_step} //这里会在第4和第8个周期分别输出脉冲
cnt_y += step_y;
if (cnt_y >= event_step) {输出Y脉冲,cnt_y -= event_step} //这里会在第2/4/6/8个周期分别输出脉冲
cnt_z += step_z;
if (cnt_z >= event_step) {输出Z脉冲,cnt_z -= event_step} //每个周期都输出脉冲
你按照每个周期来算一下就知道,X/Y/Z会按照插值法来输出脉冲了,这个就是DDA的一个例子
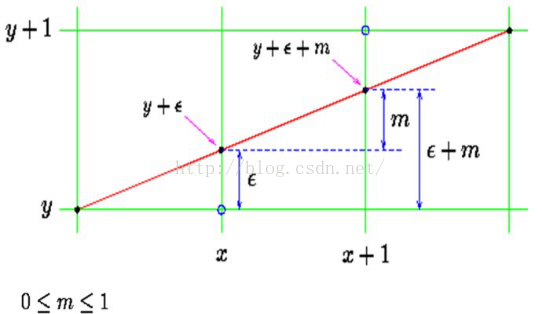

假设需要从点(0,0,0)到点(31,21,5),从(0,0,0)到(31,21,5)最终的执行结果是X轴步进电机移动31步、Y轴步进电机移动21步、Z轴步进电机移动了5步。
那么代码执行的详细情况如下
current_block->steps[X_AXIS] = 31;
current_block->steps[Y_AXIS] = 21;
current_block->steps[Z_AXIS] = 5;
current_block->step_event_count = 31;
//st.counter_x = st.counter_y = st.counter_z = (st.exec_block->step_event_count >> 1);
counter_x = (current_block->step_event_count>>1) = 15;
counter_y = counter_z = counter_e = counter_x;
第一步
Counter_x = counter_x + current_block->steps[X_AXIS] = 15 + 31 = 46;
因为条件counter_x > current_block->step_event_count为true, 所以X电机向前走一步
counter_x = counter_x - current_block->step_event_count = 46 - 31; = 15;
counter_y = counter_y + current_block->steps[Y_AXIS] = 15 + 21 = 36;
因为条件counter_y > current_block->step_event_count为true,所以Y电机向前走一步
counter_y = counter_y - current_block->step_event_count = 36 - 31 = 5;
counter_z = counter_z + current_block->steps[Z_AXIS] = 15 + 5 = 20;
因为条件counter_z > current_block->step_event_count为false,所以Z电机不动
第二步
Counter_x = counter_x + current_block->steps[X_AXIS] = 15 + 31 = 46;
因为条件counter_x > current_block->step_event_count为true, 所以X电机向前走一步
counter_x = counter_x - current_block->step_event_count = 46 - 31 = 15;
counter_y = counter_y + current_block->steps[Y_AXIS] = 5 + 21 = 26;
因为条件counter_y > current_block->step_event_count为false,所以Y电机不动
counter_z = counter_z + current_block->steps[Z_AXIS] = 20 + 5 = 25;
因为条件counter_z > current_block->step_event_count为false,所以Z电机不动