目录标题
- 前言
- 一、数据库连接方式
- 1.JDBC连接数据库
- 2.Spring Jdbc连接数据库(JdbcTemplate)
- 二、JdbcTemplate源码分析
- 1.update/save功能的实现
- 源码分析入口(关键)
- 基础方法execute
- 1.获取数据库连接池
- 2.应用用户设定的输入参数
- 3. 调用回调函数处理
- 4. 资源释放
- Update中的回调函数
- 2.query 功能的实现
- 源码分析入口1(关键)
- 源码分析入口2(关键)
- 3.queryForObject
- 总结
前言
汇总:《Spring源码深度分析》持续更新中…
本章主要以Spring提供的模板类’JdbcTemplate‘为例,进行源代码分析。如果有小伙伴对Spring如何支持持久化技术的理论知识感兴趣,可以参考《精通Spring4.x 企业应用开发实战》第10章 Spring对Dao的支持。
一、数据库连接方式
从《精通Spring4.x 企业应用开发实战》第10章 Spring对Dao的支持
文章中,我们知道目前市场上连接MySQL数据库常用的几种持久化方式有五种:JDBC、Mybatis、Hibernate、JTA、JDO。
然而Spring又分别对JDBC、Hibernate、JTA、JDO提供了模板类,以便快速进行持久化连接开发。其中Spring针对JDBC的模板类是’JdbcTemplate‘。

下面,我们将分别对JDBC和JdbcTemplate数据库连接进行分析。
1.JDBC连接数据库
JDBC ( Java Data Base Connectivity, Java 数据库连接)是一种用于执行 SQL 语句的 Java API,可以为多种关系数据库提供统一访问,它由一组用 Java 语言编写的类和接口组成。JDBC 为数据库开发人员提供了一个标准的 API,据此可以构建更高级的工具和接口,使数据库开发人员能够用纯 Java API 编写数据库应用程序,并且可跨平台运行,并且不受数据库供应商的限制。
JDBC 连接数据库的流程及其原理如下。
(1)在开发环境中加载指定数据库的驱动程序。接下来的实验中,使用的数据库是 MysQL,所以需要去下载 MySQL 支持 JDBC 的驱动程序(最新的版本是 mysal-conneetorjava-5.1.18-bin.jar),将下载得到的驱动程序加载进开发环境中(开发环境是 MyEclipse,具体示例时会讲解如何加载)。
(2)在Java 程序中加载驱动程序。在 Java 程序中,可以通过“Class.forName(“指定数据库的驱动程序”)”的方式来加载添加到开发环境中的驱动程序,例如加载 MySQL 的数据驱动程序的代码为 Class. forName(“com.mysqljdbc.Driver”)。
(3)创建数据连接对象。通过 DriverManager 类创建数据库连接对象 Conneetion。DriverManager 类作用于 Java 程序和 JDBC 驱动程序之间,用于检查所加载的驱动程序是否可以建立连接,然后通过它的 getConnection 方法根据数据库的 URL、用户名和密码,创建一个JDBC Connection 对象,例如:Connection connection = DriverManager.getConnection(“连接数据库的 URL”,“用户名”,"密码”)。其中,URL-协议名+1P 地址(域名) +端口+数据库名称;用户名和密码是指登录数据库时所使用的用户名和密码。具体示例创建 MySQL 的数据库连接代码如下:
Connection connectMySQL = DriverManager.getConnection (“jdbc:mysql://localhost: 3306/myuser","root","root" );
(4)创建 Statement 对象。Statement 类的主要是用于执行静态 SQL 语句并返回它所生成结果的对象。通过 Connection 对象的 createStatement()方法可以创建一个 Statement 对象。例如:Statement statament = connection.createStatement()。具体示例创建 Statement 对象代码如下:
Statement statamentMySQL = connectMySQL.createStatement ();
(5)调用 Statement 对象的相关方法执行相对应的 SQL 语句。通过 execuUpdate()方法来对数据更新,包括插入和删除等操作,例如向 staff 表中插人一条数据的代码:statement.excuteUpdate( “INSERTINTO staff (name, age, sex,address,depart,worklen, wage) " + " VALUES (‘Tom1’, 321,“M’,‘china’,Personnel’,,3”,,3000’)”);通过调用 Statement 对象的 executeQuery()方法进行数据的查询,而查询结果会得到 ResulSet对象,ResuSet 表示执行查询数据库后返回的数据的集合,ResulSet 对象具有可以指向当前数据行的指针。通过该对象的 next()方法,使得指针指向下一行,然后将数据以列号或者字段名取出。如果当 next()方法返回 null,则表示下一行中没有数据存在。使用示例代码如下:
Resultset resultsel = statement.executeQuery( “select * from staff" );
(6)关闭数据库连接。使用完数据库或者不需要访问数据库时,通过 Connection 的 close()方法及时关闭数据连接。
2.Spring Jdbc连接数据库(JdbcTemplate)
Spring 中的 JDBC 连接与直接使用 JDBC 去连接还是有所差别的,Spring 对 JDBC 做了大量封裝,消除了冗余代码,使得开发量大大减小。下面通过一个小例子让大家简单认识 Spring中的 JDBC 操作。




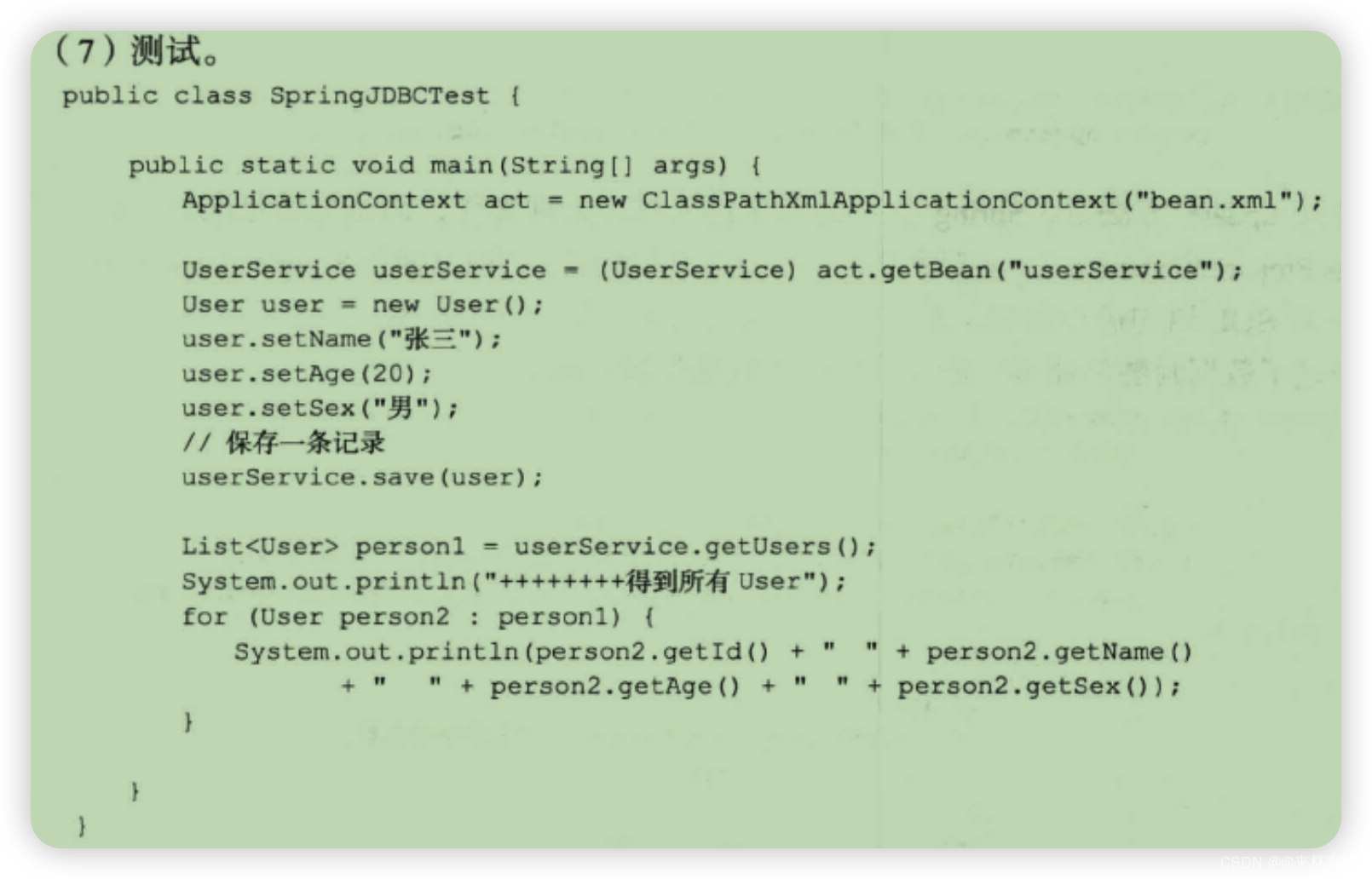
二、JdbcTemplate源码分析
1.update/save功能的实现
源码分析入口(关键)
无论对哪种技术进行源码分析,我们都应该先找到入口点,然后顺藤摸瓜式的解读源码。
我们以上面的例子为基础开始分析 Spring 中对JDBC 的支持,首先寻找整个功能的切入点,在示例中我们可以看到所有的数据库操作都封装在了 UserServicelmpl 中,而 UserServicelmpl中的所有数据库操作又以其内部属性 jdbcTemplate 为基础。这个jdbcTemplate 可以作为源码分析的切人点,我们一起看看它是如何实现又是如何被初始化的。
在 UserServicelmpl 中 jdbcTemplate 的初始化是从 setDataSource 函数开始的,DataSource实例通过参数注入,DataSource 的创建过程是引入第三方的连接池,这里不做过多介绍。DataSource 是整个数据库操作的基础,里面封装了整个数据库的连接信息。我们首先以保存实体类为例进行代码跟踪。
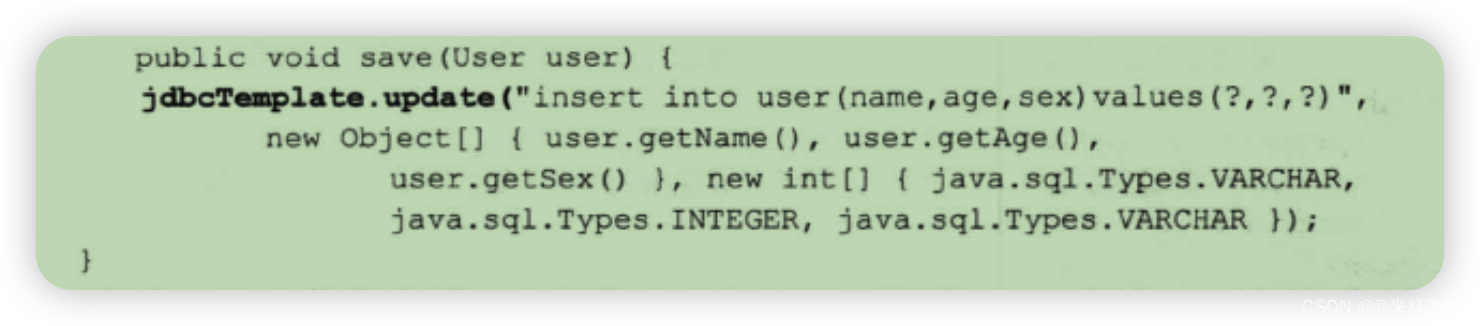
对于保存一个实体类来讲,在操作中我们只需要提供 SQL 语句以及语句中对应的参数和参数类型,其他操作便可以交由 Spring 来完成了,这些工作到底包括什么呢?进入 jdbcTemplate中的 update 方法。
@Override
public int update(String sql, Object[] args, int[] argTypes) throws DataAccessException {
return update(sql, newArgTypePreparedStatementSetter(args, argTypes));
}
@Override
public int update(String sql, @Nullable PreparedStatementSetter pss) throws DataAccessException {
return update(new SimplePreparedStatementCreator(sql), pss);
}
进人 update 方法后,我们发现Spring 并不是急于进入核心处理操作,而是先做足准备工作:
- 使用
ArgTypePreparedStatementSetter对参数与参数类型进行封装 , - 同时又使用
SimplePreparedStatementCreator对 SQL 语句进行封装。
至于为什么这么封装,暂且留下悬念。
经过了数据封装后便可以进入了核心的数据处理代码了。
protected int update(final PreparedStatementCreator psc, @Nullable final PreparedStatementSetter pss)
throws DataAccessException {
logger.debug("Executing prepared SQL update");
// PreparedStatementCallback作为回调函数。execute 方法是最基础的操作,而其他操作比如update、 query 等方法则是传人不同的 PreparedStatementCallback 参数来执行不同的逻辑,
return updateCount(execute(psc, ps -> {
try {
if (pss != null) {
// ArgumentTypePreparedStatementSetter.setValue: 将参数赋值给对应的参数类型
pss.setValues(ps);
}
// ps.executeUpdate(): JDBC-API的基本操作
int rows = ps.executeUpdate();
if (logger.isTraceEnabled()) {
logger.trace("SQL update affected " + rows + " rows");
}
return rows;
}
finally {
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
}, true));
}
基础方法execute
/**
* 功能描述:作为'公用的method',被具有'个性化'的方法(增删改查)调用。
* execute 作为数据库操作的核心人口,將大多数数据库操作相同的步骤统一封装,而将个性化的操作使用参数 PreparedStatementCallback 进行回调。
*
* @param psc
* @param action
* @param closeResources
* @return
* @param <T>
* @throws DataAccessException
*/
@Nullable
private <T> T execute(PreparedStatementCreator psc, PreparedStatementCallback<T> action, boolean closeResources)
throws DataAccessException {
Assert.notNull(psc, "PreparedStatementCreator must not be null");
Assert.notNull(action, "Callback object must not be null");
if (logger.isDebugEnabled()) {
String sql = getSql(psc);
logger.debug("Executing prepared SQL statement" + (sql != null ? " [" + sql + "]" : ""));
}
// 获取与'数据库事务'相绑定的'数据库连接'。
Connection con = DataSourceUtils.getConnection(obtainDataSource());
PreparedStatement ps = null;
try {
ps = psc.createPreparedStatement(con);
applyStatementSettings(ps);
// 执行数据库操作(CRUD)。处理一些通用方法外的个性化处理,也就是 PreparedStatementCallback 类型的参数的doInPreparedStatement 方法的回调。
T result = action.doInPreparedStatement(ps);
handleWarnings(ps);
return result;
}
catch (SQLException ex) {
// Release Connection early, to avoid potential connection pool deadlock
// in the case when the exception translator hasn't been initialized yet.
if (psc instanceof ParameterDisposer) {
((ParameterDisposer) psc).cleanupParameters();
}
String sql = getSql(psc);
psc = null;
JdbcUtils.closeStatement(ps);
ps = null;
// 数据库的连接释放并不是直接调用了 Connection 的API中的close 方法。考虑到存在事务的情况,如果当前线程存在事务,那么说明在当前线程中存在共用数据库连接,这种情况下直接使用 ConnectionHolder 中的 released 方法进行连接数减一,面不是真正的释放连接。
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw translateException("PreparedStatementCallback", sql, ex);
}
finally {
if (closeResources) {
if (psc instanceof ParameterDisposer) {
((ParameterDisposer) psc).cleanupParameters();
}
JdbcUtils.closeStatement(ps);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
}
下面,我们对execute代码中重要的几个关键点进行分析。
1.获取数据库连接池
获取数据库连接也并非直接使用 dataSource.getConnection()方法那么简单,同样也考虑了诸多情况。
在数据库连接方面,Spring 主要考虑的是关于事务方面的处理。基于事务处理的特殊性,Spring 需要保证线程中的数据库操作都是使用同一个事务连接。
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(fetchConnection(dataSource));
}
return conHolder.getConnection();
}
// Else we either got no holder or an empty thread-bound holder here.
logger.debug("Fetching JDBC Connection from DataSource");
Connection con = fetchConnection(dataSource);
// 功能描述:判断'当前线程'是否存在事务。
// 目的:spring需要保证线程下的数据库操作,都使用同一个事务连接。那么当事务回滚的时候,可以一次性回滚所有的数据库操作。
if (TransactionSynchronizationManager.isSynchronizationActive()) {
try {
// Use same Connection for further JDBC actions within the transaction.
// Thread-bound object will get removed by synchronization at transaction completion.
// 在事务中,使用同一个数据库连接。
ConnectionHolder holderToUse = conHolder;
if (holderToUse == null) {
holderToUse = new ConnectionHolder(con);
}
else {
holderToUse.setConnection(con);
}
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(
new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
catch (RuntimeException ex) {
// Unexpected exception from external delegation call -> close Connection and rethrow.
releaseConnection(con, dataSource);
throw ex;
}
}
return con;
}
2.应用用户设定的输入参数
protected void applyStatementSettings(Statement stmt) throws SQLException {
int fetchSize = getFetchSize();
if (fetchSize != -1) {
stmt.setFetchSize(fetchSize);
}
int maxRows = getMaxRows();
if (maxRows != -1) {
stmt.setMaxRows(maxRows);
}
DataSourceUtils.applyTimeout(stmt, getDataSource(), getQueryTimeout());
}
a: setFetchsize 最主要是为了减少网络交互次数设计的。访问 ResultSet 时,如果它每次只从服务器上读取一行数据,则会产生大量的开销。setFetchSize 的意思是当调用 rs.next 时,ResultSet会一次性从服务器上取得多少行数据回来,这样在下次 rs.next 时,它可以直接从内存中获取数据而不需要网络交互,提高了效率。这个设置可能会被某些 JDBC 驱动忽略,而且设置过大也会造成内存的上升。
b: setMaxRows 将此 Statement对象生成的所有 ResulSet 对象可以包含的最大行数限制设置为给定数。
3. 调用回调函数处理
一些通用方法外的个性化处理,也就是 PreparedStatementCallback 类型的参数的dolnPreparedStatement 方法的回调。
4. 资源释放
数据库的连接释放并不是直接调用了 Connection 的APL中的.close 方法。考虑到存在事务的情况,如果当前线程存在事务,那么说明在当前线程中存在共用数据库连接,这种情况下直接使用 ConnectionHolder 中的 released 方法进行连接数减一,面不是真正的释放连接。
public static void doReleaseConnection(@Nullable Connection con, @Nullable DataSource dataSource) throws SQLException {
if (con == null) {
return;
}
if (dataSource != null) {
// 当前线程存在事务的情况下说明存在'共用数据库连接',直接使用 ConnectionHolder 中的released 方法进行连接数减一而不是真正的释放连接。
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && connectionEquals(conHolder, con)) {
// It's the transactional Connection: Don't close it.
conHolder.released();
return;
}
}
// 直接使用Connection的API,调用close方法释放连接
doCloseConnection(con, dataSource);
}
Update中的回调函数
PreparedStatementCalback 作为一个接口,其中只有一个函数 doInPreparedStatement,这个函数是用于调用通用方法 execute 的时候无法处理的一些个性化处理方法,在 update 中的函数实现:
protected int update(final PreparedStatementCreator psc, @Nullable final PreparedStatementSetter pss)
throws DataAccessException {
logger.debug("Executing prepared SQL update");
// PreparedStatementCallback作为回调函数。execute 方法是最基础的操作,而其他操作比如update、 query 等方法则是传人不同的 PreparedStatementCallback 参数来执行不同的逻辑,
return updateCount(execute(psc, ps -> {
try {
if (pss != null) {
// ArgumentTypePreparedStatementSetter.setValue: 将参数赋值给对应的参数类型
pss.setValues(ps);
}
// ps.executeUpdate(): JDBC-API的基本操作
int rows = ps.executeUpdate();
if (logger.isTraceEnabled()) {
logger.trace("SQL update affected " + rows + " rows");
}
return rows;
}
finally {
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
}, true));
}
其中用于真正执行 SQL 的 ps.executeUpdate 没有太多需要讲解的,因为我们平时在直接使用JDBC 方式进行调用的时候会经常使用此方法。但是,对于设置输人参数的函数 pss.set Values(ps),我们有必要去深人研究一下。在没有分析源码之前,我们至少可以知道其功能,不妨再回顾下 Spring 中使用 SOL 的执行过程,直接使用:

SQL 语句对应的参数,对应参数的类型清晰明了,这都归功于 Spring 为我们做了封裝,而真正的 JDBC 调用其实非常繁琐,你需要这么做:
 那么看看 Spring 是如何做到封装上面的操作呢?首先,所有的操作都是以 pss.setValues(ps)为入口的。还记得我们之前的分析路程吗?这个pss 所代表的当前类正是 ArgPreparedStatementSetter。其中的 setValues 的相关源码分析此处略。
那么看看 Spring 是如何做到封装上面的操作呢?首先,所有的操作都是以 pss.setValues(ps)为入口的。还记得我们之前的分析路程吗?这个pss 所代表的当前类正是 ArgPreparedStatementSetter。其中的 setValues 的相关源码分析此处略。
2.query 功能的实现
源码分析入口1(关键)
在之前的章节中我们介绍了 update 方法的功能实现,那么在数据库操作中查找操作也是使用率非常高的函数,同样我们也需要了解它的实现过程。使用方法如下:

@Override
public <T> List<T> query(String sql, Object[] args, int[] argTypes, RowMapper<T> rowMapper) throws DataAccessException {
return result(query(sql, args, argTypes, new RowMapperResultSetExtractor<>(rowMapper)));
}
@Override
@Nullable
public <T> T query(String sql, Object[] args, int[] argTypes, ResultSetExtractor<T> rse) throws DataAccessException {
// 与 update 方法中都同样使用了 newArgTypePreparedStatementSetter。
return query(sql, newArgTypePreparedStatementSetter(args, argTypes), rse);
}
@Override
@Nullable
public <T> T query(String sql, @Nullable PreparedStatementSetter pss, ResultSetExtractor<T> rse) throws DataAccessException {
return query(new SimplePreparedStatementCreator(sql), pss, rse);
}
核心代码如下:
@Nullable
public <T> T query(
PreparedStatementCreator psc, @Nullable final PreparedStatementSetter pss, final ResultSetExtractor<T> rse)
throws DataAccessException {
Assert.notNull(rse, "ResultSetExtractor must not be null");
logger.debug("Executing prepared SQL query");
// 此处会调用和update一样的execute方法
return execute(psc, new PreparedStatementCallback<T>() {
@Override
@Nullable
public T doInPreparedStatement(PreparedStatement ps) throws SQLException {
ResultSet rs = null;
try {
if (pss != null) {
// ArgumentTypePreparedStatementSetter.setValue
pss.setValues(ps);
}
// ps.executeQuery():JDBC-API的基本操作
rs = ps.executeQuery();
// rse.extractData(rsToUse)方法负责将结果进行封装并转换至 POJO, rse 当前代表的类为RowMapperResultSetExtractor,而在构造 RowMapperResultSetExtractor 的时候我们又将自定义的 rowMapper 设置了进去。
return rse.extractData(rs);
}
finally {
JdbcUtils.closeResultSet(rs);
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
}
}, true);
}
可以看到整体套路与 update 差不多的,只不过在回调类 PreparedStatementCallback 的:中使用的是 ps.executeQuery()执行查询操作,而且在返回方法上也做了一些额外的处理。
源码分析入口2(关键)
之前讲了 update 方法以及 query 方法,使用这两个附数示例的 SQL 都是带有参数的,也就是带有“?”的,那么还有另一种情况是不带有“?”的,Spring 中使用的是另一种处理方式。例如:
List<user> 1ist = jdbcTemplate.query ("selectfrom user", new UserRowMapper() );
追踪进入:
@Override
public <T> List<T> query(String sql, RowMapper<T> rowMapper) throws DataAccessException {
return result(query(sql, new RowMapperResultSetExtractor<>(rowMapper)));
}
核心源码:
/**
* 功能描述:与之前的 query 方法最大的不同是少了参数及参数类型的传递,自然也少了 PreparedStatementSetter 类型的封装。
*
* @param sql the SQL query to execute
* @param rse a callback that will extract all rows of results
*/
@Override
@Nullable
public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException {
Assert.notNull(sql, "SQL must not be null");
Assert.notNull(rse, "ResultSetExtractor must not be null");
if (logger.isDebugEnabled()) {
logger.debug("Executing SQL query [" + sql + "]");
}
/**
* Callback to execute the query.
*/
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
@Override
@Nullable
public T doInStatement(Statement stmt) throws SQLException {
ResultSet rs = null;
try {
rs = stmt.executeQuery(sql);
return rse.extractData(rs);
}
finally {
JdbcUtils.closeResultSet(rs);
}
}
@Override
public String getSql() {
return sql;
}
}
// 既然少了 PreparedStatementSetter 类型的传入,调用的 execute 方法自然也会有所改变了。
return execute(new QueryStatementCallback(), true);
}
execute方法:
/**
* 功能描述:这个 exexute 与之前的 execute 并无太大差别,都是做一些常规的处理,诸如获取连接、释连接等。
* 但是,有一个地方是不一样的,就是 statement 的创建。这里直接使用connection 创建,而带有参数的 SQL 使用的是 PreparedStatementCreator 类来创建的。一个是普通的 Statement,另一个是 PreparedStatement。
*
* @param <T>
* @throws DataAccessException
*/
@Nullable
private <T> T execute(StatementCallback<T> action, boolean closeResources) throws DataAccessException {
Assert.notNull(action, "Callback object must not be null");
Connection con = DataSourceUtils.getConnection(obtainDataSource());
Statement stmt = null;
try {
stmt = con.createStatement();
applyStatementSettings(stmt);
T result = action.doInStatement(stmt);
handleWarnings(stmt);
return result;
}
catch (SQLException ex) {
// Release Connection early, to avoid potential connection pool deadlock
// in the case when the exception translator hasn't been initialized yet.
String sql = getSql(action);
JdbcUtils.closeStatement(stmt);
stmt = null;
DataSourceUtils.releaseConnection(con, getDataSource());
con = null;
throw translateException("StatementCallback", sql, ex);
}
finally {
if (closeResources) {
JdbcUtils.closeStatement(stmt);
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
}
PreparedStatement 接口继承 Statement,并与之在两方面有所不同:
- PreparedStatement 实例包含已编译的 SQL 语句.这就是使语向“准备好”。包含于PreparedStatement 对象中的 SQL 语句可具有一个或多个IN 参数。IN 参数的值在 SQL语句创建时未被指定。相反的,该语句为每个 IN 参数保留一个问号(“2”)作为占位符。每个问号的值必须在该语句执行之前,通过适当的 setXXX 方法来提供。
- 由于 PreparedStatement 对象已预编译过,所以其执行速度要快于 Statement 对象。因此,多次执行的 SQL 语句经常创建为 PreparedStatement 对象,以提高效率。
3.queryForObject
Spring 中不仅仅为我们提供了 query 方法,还在此基础上做了封装,提供了不同类型的 query方法。此处源码分析略。
总结
待补充。