前言:
在上一篇博客中,我们已经详解学习了堆的基本知识,今天带大家进入的是二叉树的另外一种存储方式----“链式二叉树”的学习,主要用到的就是“递归思想”!!
本文目录
- 1.链式二叉树的实现
- 1.1前置说明
- 1.2结构体以及声明
- 2.遍历二叉树
- 2.1算法描述
- 2.2先序遍历
- 2.3中序遍历
- 2.4后序遍历
- 2.5层序遍历
- 2.6算法分析
- 3.接口功能的实现
- 3.1二叉树节点个数
- 3.2二叉树叶子节点个数
- 3.3二叉树第k层节点个数
- 3.4二叉树查找值为x的节点
- 3.5二叉树的高度
- 3.6二叉树的销毁
- 3.7判断是否为完全二叉树
- 4.选择题练习
- 5.OJ题练习
- 5.1 单值二叉树(LeetCode 965题)
- 5.2检查两颗树是否相同(LeetCode 100题)
- 5.3 对称二叉树(LeetCode 101题)
- 5.4另一颗树的子树(LeetCode 572题)
- 5.5二叉树的前序遍历(LeetCode 144题)
- 5.6 二叉树中序遍历(LeetCode 94题)
- 5.7二叉树的后序遍历(LeetCode 145题)
- 6.总结
前情回顾:
再看二叉树基本操作前,再回顾下二叉树的概念,二叉树是:
- 空树
- 非空:根节点,根节点的左子树、根节点的右子树组成的。

1.链式二叉树的实现
1.1前置说明
在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二叉树结构掌握还不够深入,为了降低大家学习成本,此处手动快速创建一棵简单的二叉树,快速进入二叉树操作学习,等二叉树结构了解的差不多时,我们反过头再来研究二叉树真正的创建方式,代码如下:
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType _data;
struct BinaryTreeNode* _left;
struct BinaryTreeNode* _right;
}BTNode;
BTNode* CreatBinaryTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->_left = node2;
node1->_right = node4;
node2->_left = node3;
node4->_left = node5;
node4->_right = node6;
return node1;
}
注意:
上述代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解。
1.2结构体以及声明
跟我们之前学习的数据结构一样,我们为了方便存储各种数据类型,我们会先对堆存储的数据类型进行重定义,具体如下:
typedef int BTDataType;
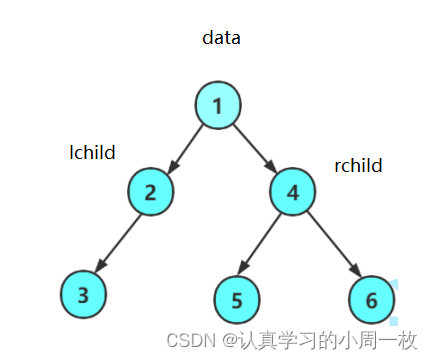
在这里我们实现的是二叉树链式存储的存储结构。还是跟之前一样,结构体中有三个成员,一个指向当前结点的值,还有两个是指向当前结点左孩子结点的指针以及指向右孩子结点的指针,具体如下:
typedef struct BinaryTreeNode
{
BTDataType data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
具体如下图:
2.遍历二叉树
2.1算法描述
遍历二叉树( traversing binary tree )是指按某条搜索路径巡访树中每个结点,使得每个结点均被访问一次,而且仅被访问一次。
访问的含义很广,可以是对结点做各种处理,包括输出结点的信息,对结点进行运算和修改等。遍历二叉树是二叉树最基本的操作,也是二叉树其他各种操作的基础,遍历的实质是对二叉树进行线性化的过程,即遍历的结果是将非线性结构的树中结点排成一个线性序列。由于二叉树的每个结点都可能有两棵子树,因而需要寻找一种规律,以便使二叉树的结点能排列在一个线性队列上,从而便于遍历
回顾二叉树的递归定义可知,二叉树是由3个基本单元组成:根结点、左子树和右子树。依次遍历这三部分,便是遍历了整个二叉树。假如从 L 、 D 、 R 分别表示遍历左子树和遍历右子树,则可有 DLR 、 LDR 、 LRD 、 DRL 、 RDL 、 RLD 这6种遍历二叉树的方左后右,则只有前3种情况,分别称之为先(根)序遍历、中(根)序遍历和后(根)遍历。基于二叉树的递归定义,可得下述遍历二叉树的递归算法定义,我们一个一个认识。
2.2先序遍历
定义:
前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。
思想:
若二叉树为空,则空操作;否则
(1)访问根结点
(2)先序遍历左子树
(3)先序遍历右子树
即考察到一个节点后,即刻输出该节点的值,并继续遍历其左右子树。(根左右)
举例:
因为这是第一次认识,我们举个具体的例子来带大家深入理解,我们以下图为例来具体分析先序遍历的步奏:
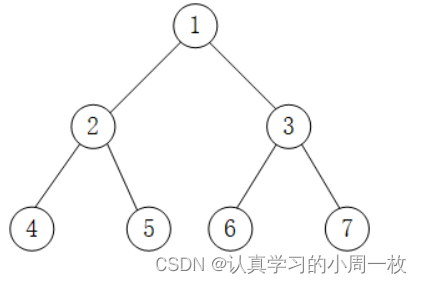
如图所示,采用先序遍历访问这颗二叉树的详细过程为:
1.访问该二叉树的根节点,找到 1;
2.访问节点 1 的左子树,找到节点 2;
3.访问节点 2 的左子树,找到节点 4;
4.由于访问节点 4 左子树失败,且也没有右子树,因此以节点 4 为根节点的子树遍历完成。但节点 2 还没有遍历其右子树,因此现在开始遍历,即访问节点 5;
5.由于节点 5 无左右子树,因此节点 5 遍历完成,并且由此以节点 2 为根节点的子树也遍历完成。现在回到节点 1 ,并开始遍历该节点的右子树,即访问节点 3;
6.访问节点 3 左子树,找到节点 6;
7.由于节点 6 无左右子树,因此节点 6 遍历完成,回到节点 3 并遍历其右子树,找到节点 7;
8.节点 7 无左右子树,因此以节点 3 为根节点的子树遍历完成,同时回归节点 1。由于节点 1 的左右子树全部遍历完成,因此整个二叉树遍历完成;
因此,图 中二叉树采用先序遍历得到的序列为:1 2 4 5 3 6 7
我们在通过另外一个例子图解解递归算法:

代码如下:
void PrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%d ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}
2.3中序遍历
定义:
中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)
思想:
若二叉树为空,则空操作;否则
(1)中序遍历左子树
(2)访问根结点
(3)中序遍历右子树
即考察到一个节点后,将其暂存,遍历完左子树后,再输出该节点的值,然后遍历右子树。(左根右)
举例:
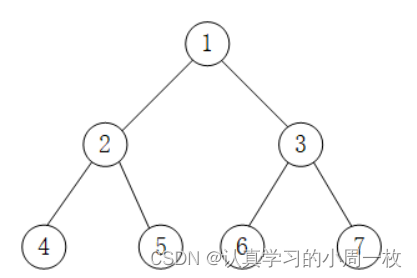
以上图为例,采用中序遍历的思想遍历该二叉树的过程为:
1.访问该二叉树的根节点,找到 1;
2.遍历节点 1 的左子树,找到节点 2;
3.遍历节点 2 的左子树,找到节点 4;
4.由于节点 4 无左孩子,因此找到节点 4,并遍历节点 4 的右子树;
5.由于节点 4 无右子树,因此节点 2 的左子树遍历完成,访问节点 2;
6.遍历节点 2 的右子树,找到节点 5;
7.由于节点 5 无左子树,因此访问节点 5 ,又因为节点 5 没有右子树,因此节点 1 的左子树遍历完成,访问节点 1 ,并遍历节点 1 的右子树,找到节点 3;
8.遍历节点 3 的左子树,找到节点 6;
9.由于节点 6 无左子树,因此访问节点 6,又因为该节点无右子树,因此节点 3 的左子树遍历完成,开始访问节点 3 ,并遍历节点 3 的右子树,找到节点 7;
10.由于节点 7 无左子树,因此访问节点 7,又因为该节点无右子树,因此节点 1 的右子树遍历完成,即整棵树遍历完成;
因此,上图中二叉树采用中序遍历得到的序列为:4 2 5 1 6 3 7
代码如下:
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
}
2.4后序遍历
定义:
后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
思想:
若二叉树为空,则空操作;否则
(1)后序遍历左子树
(2)后序遍历右子树
(3)访问根结点
即考察到一个节点后,将其暂存,遍历完左右子树后,再输出该节点的值。(左右根)
举例:
我们还是以之前的图为例:
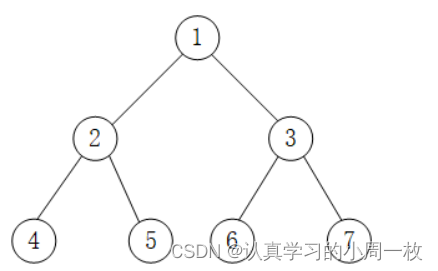
如上图中,对此二叉树进行后序遍历的操作过程为:
从根节点 1 开始,遍历该节点的左子树(以节点 2 为根节点);
1.遍历节点 2 的左子树(以节点 4 为根节点);
2.由于节点 4 既没有左子树,也没有右子树,此时访问该节点中的元素 4,并回退到节点 2 ,遍历节点 2 的右子树(以 5 为根节点);
3.由于节点 5 无左右子树,因此可以访问节点 5 ,并且此时节点 2 的左右子树也遍历完成,因此也可以访问节点 2;
4.此时回退到节点 1 ,开始遍历节点 1 的右子树(以节点 3 为根节点);
5.遍历节点 3 的左子树(以节点 6 为根节点);
6.由于节点 6 无左右子树,因此访问节点 6,并回退到节点 3,开始遍历节点 3 的右子树(以节点 7 为根节点);
7.由于节点 7 无左右子树,因此访问节点 7,并且节点 3 的左右子树也遍历完成,可以访问节点 3;节点 1 的左右子树也遍历完成,可以访问节点 1;
由此,对上图 中二叉树进行后序遍历的结果为:4 5 2 6 7 3 1
代码如下:
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%d ", root->data);
}
2.5层序遍历
定义:
层序遍历:除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
举例:
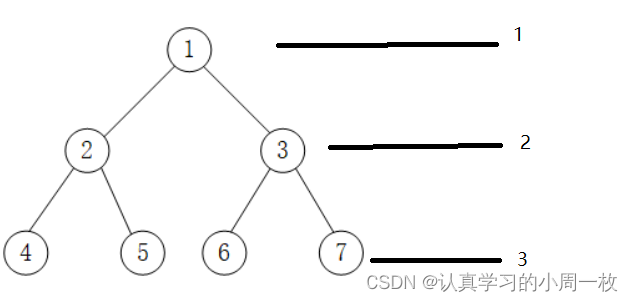
解析:
层次遍历如上图中的二叉树:
1.根结点 1 入队;
2.根结点 1 出队,出队的同时,将左孩子 2 和右孩子 3 分别入队;
3.队头结点 2 出队,出队的同时,将结点 2 的左孩子 4 和右孩子 5 依次入队;
4.队头结点 3 出队,出队的同时,将结点 3 的左孩子 6 和右孩子 7 依次入队;
5.不断地循环,直至队列内为空。
由此,对上图 中二叉树进行层序遍历的结果为:1 2 3 4 5 6 7
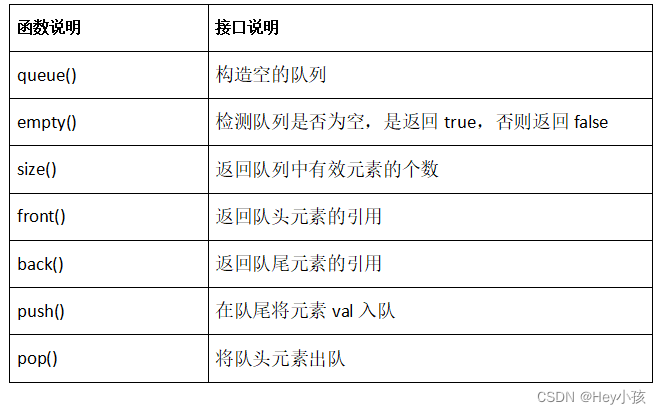
层序遍历不是一个递归过程,层序遍历的实现可以借助队列这种数据结构来进行实现,具体如下:
void LevelOrder(BTNode* root)
{
Queue q;
QueueInit(&q);
if (root)
QueuePush(&q, root);
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
printf("%d ", front->data);
QueuePop(&q);
if (front->left)
{
QueuePush(&q, front->left);
}
if (front->right)
{
QueuePush(&q, front->right);
}
}
printf("\n");
QueueDestroy(&q);
}
2.6算法分析
无论是递归还是非递归遍历二叉树,因为每个结点被访问一次,则不论按哪一种次序进行遍历,对于含有n个结点的二叉树,其时间复杂度均为O(n)。所需辅助空间为遍历过程中队列的最大容量,即树的深度,最坏情况下为n,则空间复杂度为O(n).
3.接口功能的实现
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
//二叉树的高度
int TreeHeight(BTNode* root)
3.1二叉树节点个数
思想:
这里需要用到递归的思想去进行解决,进行一个分块求解然后再加起来就可以了。单次逻辑是只要求出左子树结点个数,再加上右子树节点个数,最后再加1就得到二叉树的总结点个数了。
int TreeSize2(BTNode* root)
{
return root == NULL ? 0 :
TreeSize2(root->left) + TreeSize2(root->right) + 1;
}
3.2二叉树叶子节点个数
思想:
整体思想就是不断向下递归找叶子结点,然后把左右子树的叶子结点总个数加起来,然后在递归进行展开。
程序的结束条件有两个:
1.一个是遇到了叶子结点;
2.另一个是遇到NULL结点,需要返回0.
代码如下 :
// 叶子节点
int TreeLeafSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL
&& root->right == NULL)
{
return 1;
}
return TreeLeafSize(root->left)
+ TreeLeafSize(root->right);
}
3.3二叉树第k层节点个数
思想:
整体思路还是很简单:
首先判断一个传进来的根结点是否为空
当k > 1 时,第k层的结点个数为其左孩子的第k - 1层 + 其右孩子的第k - 1层结点个数
当k ==1时,return 1
代码如下:
// 求第k层的节点个数 k >= 1
int TreeKLevelSize(BTNode* root, int k)
{
if (root == NULL)
return 0;
if (k == 1)
return 1;
// k > 1 子树的k-1
return TreeKLevelSize(root->left, k - 1)
+ TreeKLevelSize(root->right, k - 1);
}
3.4二叉树查找值为x的节点
思想:
整体思路比较明显,要么遍历根节点,如果是则表示找到我们想要的值;要么就是遍历完整个二叉树都没有找到该结点,至此递归便结束。具体实现就是根节点data和x比较看是否相等,相等我们立马返回;不相等就拿左子树根节点的data和x比较,如果还不相等,我们就拿右子树根节点的data和x进行比较,如果最后还是没有找到,则返回NULL
代码如下:
BTNode* TreeFind(BTNode* root, BTDataType x)
{
if (root == NULL)
return NULL;
if (root->data == x)
return root;
struct BinaryTreeNode* ret1 = TreeFind(root->left, x);
if (ret1)
return ret1;
struct BinaryTreeNode* ret2 = TreeFind(root->right, x);
if (ret2)
return ret2;
return NULL;
}
3.5二叉树的高度
思想:
整体思想就是先比较出左子树和右子树中高度高的那个,最后在加上根节点的高度【1】即可!
代码如下:
int TreeHeight(BTNode* root)
{
if (root == NULL)
{
return 0;
}
int leftHeight = TreeHeight(root->left);
int rightHeight = TreeHeight(root->right);
return leftHeight > rightHeight ? leftHeight + 1 : rightHeight + 1;
}
3.6二叉树的销毁
思想:
如果开始时从根节点开始往下销毁,现将根节点销毁了之后,那左右子树不是找不到了,不符合我们所需要的。因此我们应该先从左右子树开始,但是这样又会遇到一个问题,对于左子树来说它又可以作为一个根结点,依旧是需要先去销毁其左右子树,右子树也是一样,因此这就又成了一个递归的问题。跟我们后序遍历的思想就不谋而合了!!!
代码如下:
void DestroyTree(BTNode* root)
{
if (root == NULL) //if(!root)
return;
DestroyTree(root->lchild);
DestroyTree(root->rchild);
free(root);
}
3.7判断是否为完全二叉树
思想:
通过前面的学习,我们已经对完全的基本概念有了一定的了解。因此,这里在进行判断是我们可以考虑使用层序遍历的思想去进行解决。
具体:
首先二叉树元素全部入队,如果队列中的元素有空结点,并且空结点后面有不为空的元素那就说明此二叉树不是完全二叉树;
如果后面的元素都是空结点,那就说明这个二叉树是完全二叉树
具体代码如下:
```c
bool TreeComplete(BTNode* root)
{
Queue q;
QueueInit(&q);
if (root)
QueuePush(&q, root);
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)//遇到NULL,就可以开始判断是否为完全二叉树了
{
break;
}
else
{
QueuePush(&q, front->left);
QueuePush(&q, front->right);
}
}
//出到NULL以后,如果后面全是空,则是完全二叉树,如果有非空结点,那就不是完全二叉树
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front != NULL)
{
QueueDestroy(&q);//防止内存泄露
return false;
}
}
QueueDestroy(&q);
return true;
}
4.选择题练习
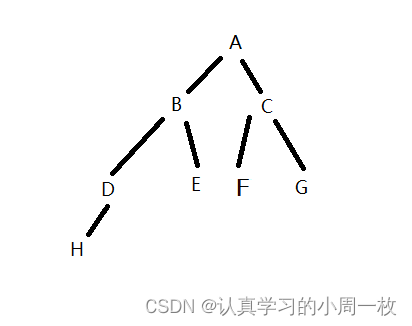
1.某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为( )
A ABDHECFG
B ABCDEFGH
C HDBEAFCG
D HDEBFGCA
解答:
标记文本选A,根据层序遍历的特点以及完全二叉树的概念,我们可以改二叉树为下图:
2.二叉树的先序遍历和中序遍历如下:先序遍历: EFHIGJK ;中序遍历: HFIEJKG 该二又树根的右子树的根是()
A E
B F
C G
D H
解答:
选C。考察的是先序(根左右),中序(左根右)来推断二叉树的结构。
根据题干中的先序和中序可以确定二叉树的结构。先序:确定E为二叉树的根节点,中序:HFI为E的左子树节点,JKG为E右子树节点。
先序:GJK 中序:JKG 根据先序得出G为右子树的根节点
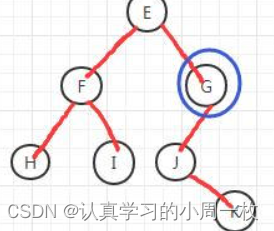
3.设一棵二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树先序遍历序列为( )。
A FEDCBA
B CBAFED
C DEFCBA
D ABCDEF
解答:选A
前序遍历:根结点 —> 左子树 —> 右子树
中序遍历:左子树—> 根结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 根结点
既然后序遍历和中序遍历结果一样,那就说明整棵二叉树都没有右子树,所以整棵树看起来就像是普通的链式结构一样,如下图:

5.OJ题练习
5.1 单值二叉树(LeetCode 965题)
链接:单值二叉树
题目:
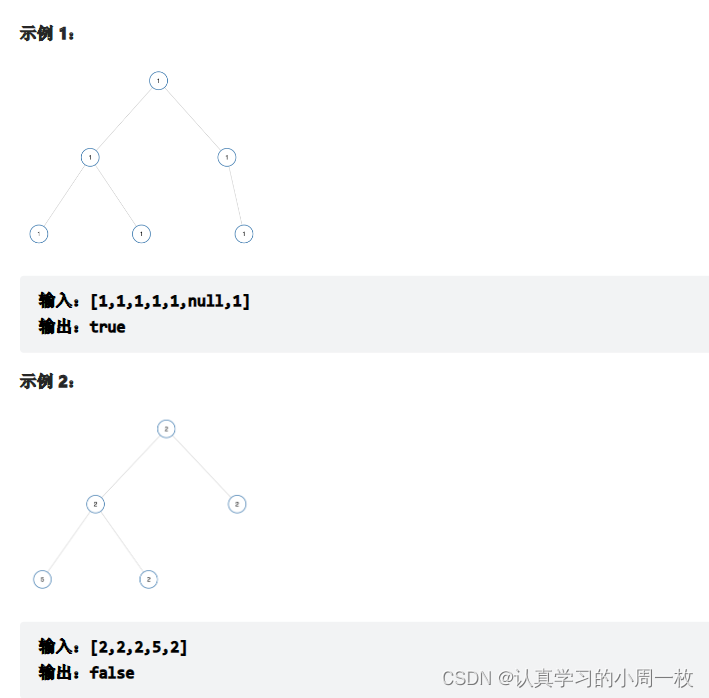
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
思路:
我们判断一棵树的所有节点都有相同的值,当且仅当对于树的孩子结点都相等时才满足相应的条件(这样根据传递性,所有节点都有相同的值)。 因此每次比较其根节点和其左右结点是否相等,若是发现不相等,立马返回false,若是相等,则递归其左右子树继续比较,直到访问最后的结点为NULL时,则得出此树为单值二叉树
代码如下:
bool isUnivalTree(struct TreeNode* root){
if (!root) {
return true;
}
if (root->left) {
if (root->val != root->left->val || !isUnivalTree(root->left)) {
return false;
}
}
if (root->right) {
if (root->val != root->right->val || !isUnivalTree(root->right)) {
return false;
}
}
return true;
}
5.2检查两颗树是否相同(LeetCode 100题)
链接:相同的树
题目:
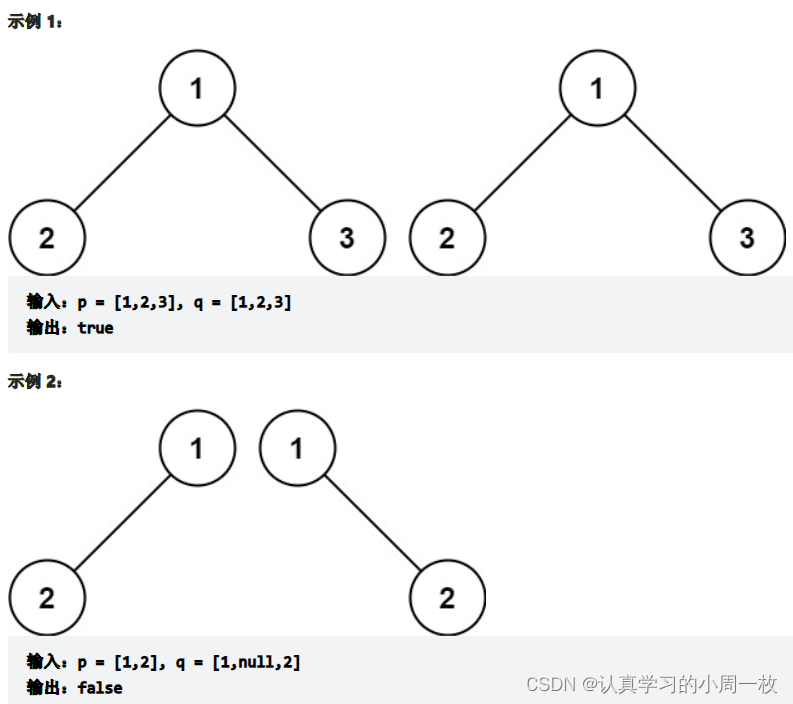
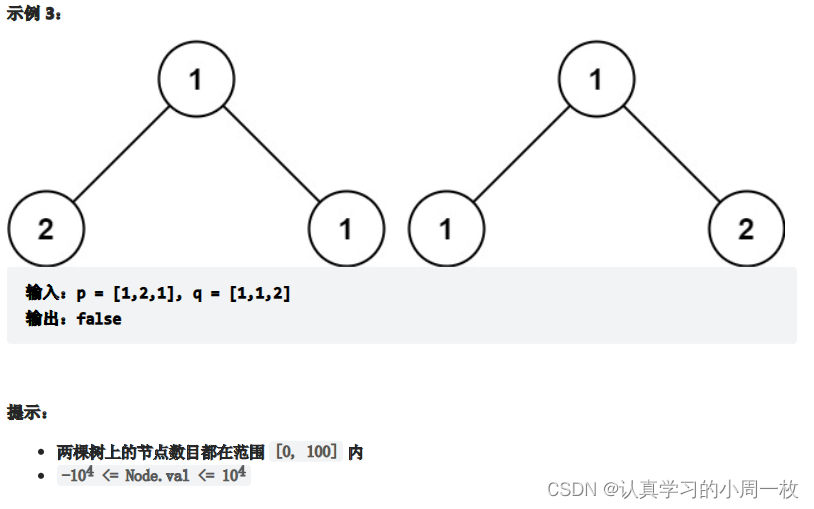
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
思路:
总体思想就是要比较两个二叉树相同,当且仅当两个二叉树的结构完全相同,且所有对应节点的值相同。如果满足上述条件则判断两颗树完全相同。
具体过程:
1.如果两个二叉树都为空,则两个二叉树相同。如果两个二叉树中有且只有一个为空,则两个二叉树一定不相同;
2.如果两个二叉树都不为空,那么首先判断它们的根节点的值是否相同,若不相同则两个二叉树一定不同;
3.若相同,再递归的去分别判断两个二叉树的左子树和右子树是否相同
代码如下:
bool isSameTree(struct TreeNode* p, struct TreeNode* q){
if(p == NULL && q == NULL)//若是两棵均为空树,则表示相同
return true;
if(p == NULL || q == NULL)
return false;
if(p->val != q->val) //比较值是否相等
return false;
//递归左右子树
return isSameTree(p->left,q->left) && isSameTree(p->right,q->right);
}
5.3 对称二叉树(LeetCode 101题)
链接:对称二叉树
题目:
给你一个二叉树的根节点 root , 检查它是否轴对称。
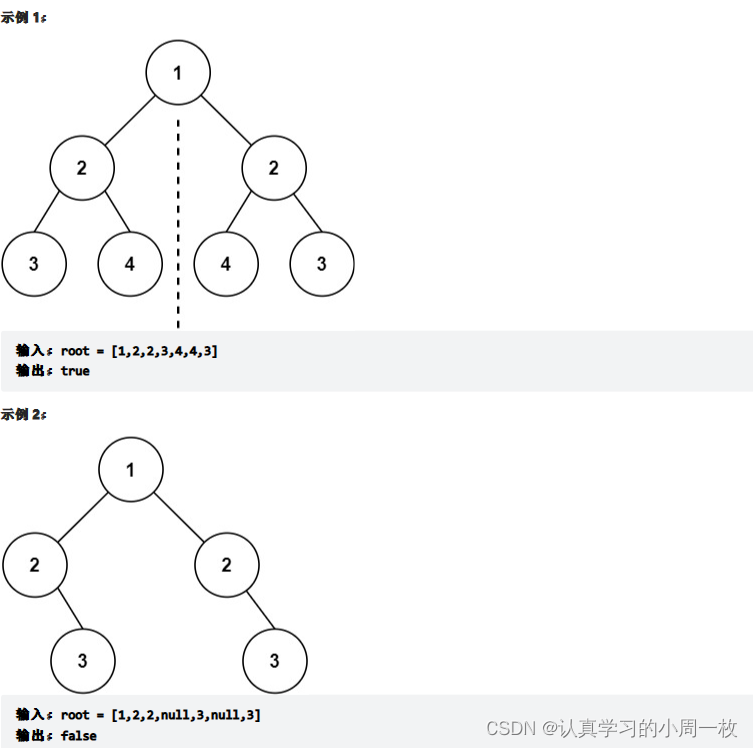
思路:
对称二叉树也称为【镜像二叉树】两个树在什么情况下互为镜像?
1.它们的两个根结点具有相同的值
2.每个树的右子树都与另一个树的左子树镜像对称
基本思想就是以根结点为对称轴,递归进行左子树和右子树中的元素的比较,如果都相同,则判断是对称二叉树
代码如下(我们这里复用了上述相同的树的代码思想):
bool isSameTree(struct TreeNode* LeftTree, struct TreeNode* RightTree)
{
if(LeftTree == NULL && RightTree == NULL)
return true;
if(LeftTree == NULL || RightTree == NULL)
return false;
if(LeftTree->val != RightTree->val)
return false;
return isSameTree(LeftTree->left,RightTree->right)
&& isSameTree (LeftTree->right,RightTree->left);
}
bool isSymmetric(struct TreeNode* root){
if(root == NULL)
return true;
return isSameTree(root->left,root->right);
}
5.4另一颗树的子树(LeetCode 572题)
链接:另一颗树的子树
题目:
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
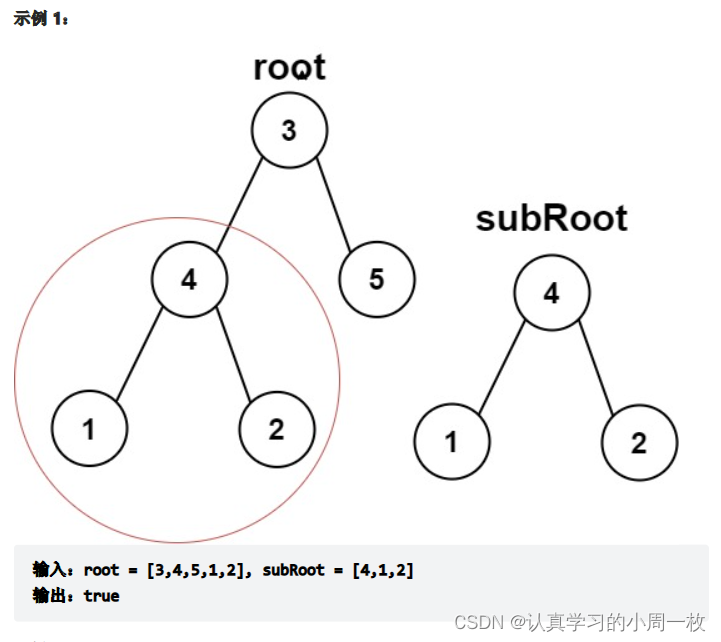
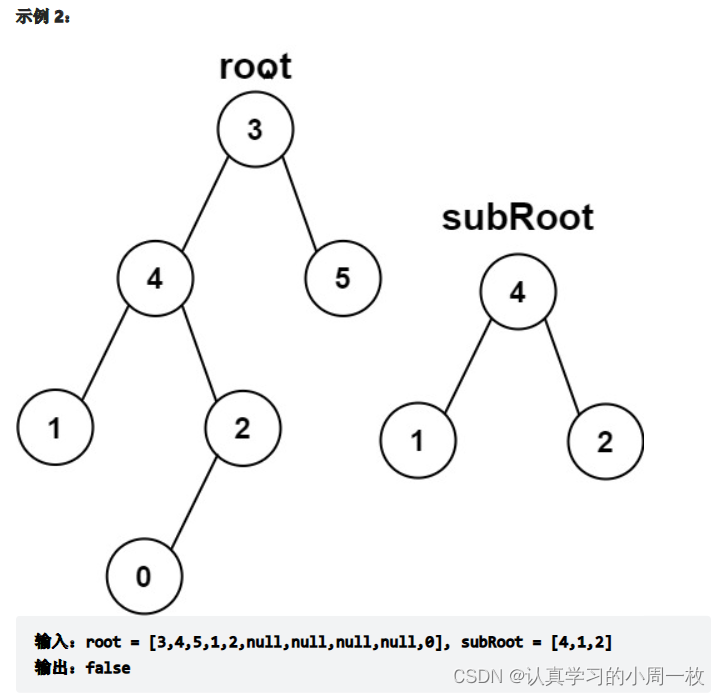
思路:
这道题直接暴力挺简单的,首先判断一个树是否是另一棵树的子树,很明显想到可以用递归:
1.先用跟节点去比较
2.不成功,递归用左孩子去比较
3.不成功,递归用右孩子去比较
代码如下:
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {
if (p == NULL && q == NULL)
return true;
if (p == NULL || q == NULL)
return false;
if (p->val != q->val)
return false;
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot){
if(root==NULL)
return false;
if(isSameTree(root,subRoot))
return true;
return isSubtree(root->left,subRoot) ||
isSubtree(root->right,subRoot);
}
大家可以发现,有了上述【相同的树】之后,做这两道题就很简单!!!
5.5二叉树的前序遍历(LeetCode 144题)
链接:二叉树的前序遍历
题目:
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。

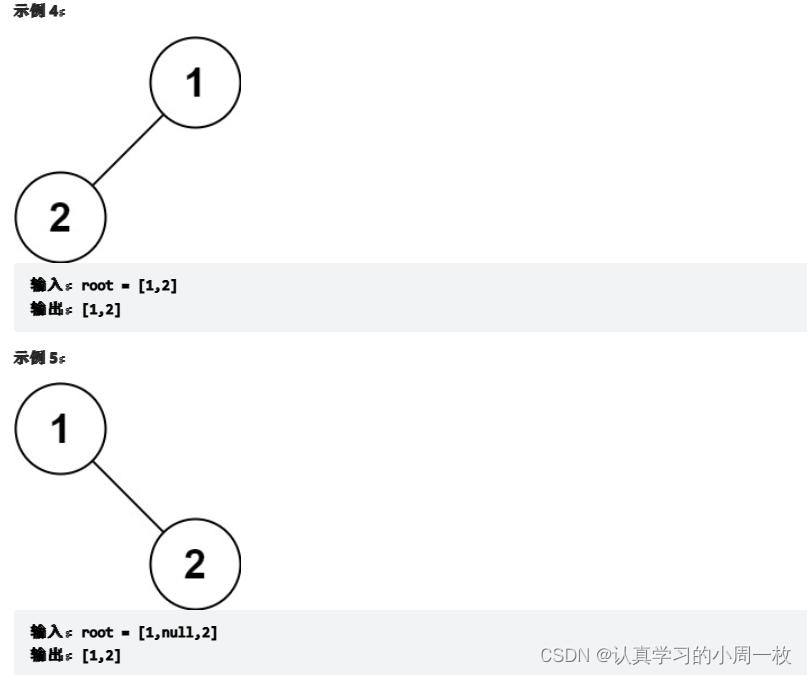
思路:
按照访问根节点——左子树——右子树的方式遍历这棵树,而在访问左子树或者右子树的时候,我们按照同样的方式遍历,直到遍历完整棵树。
此题要保存节点,所以需要先获取节点个数,然后进行前序遍历,保存每一个节点值。
代码如下:
void preorder(struct TreeNode* root,int* index,int* ret)
// index 当做数组的下标 ret是数组名称
{
if(NULL == root)
return;
else
{
ret[(*index)++] = root->val;
preorder(root->left,index,ret);
preorder(root->right,index,ret);
}
}
int* preorderTraversal(struct TreeNode* root, int* returnSize)
{
int* ret =(int*)malloc(100* sizeof(int));
*returnSize = 0;
preorder(root,returnSize,ret);
return ret;
}
5.6 二叉树中序遍历(LeetCode 94题)
链接:二叉树中序遍历
思路:
当我们了解先序遍历,中序遍历在这里就直接给出代码:
void inorder(struct TreeNode* root,int* index,int* ret)// index 当做数组的下标 ret是数组名称
{
if(NULL == root)
return;
else
{
inorder(root->left,index,ret);
ret[(*index)++] = root->val;
inorder(root->right,index,ret);
}
}
int* inorderTraversal(struct TreeNode* root, int* returnSize){
int* ret =(int*)malloc(100* sizeof(int));
*returnSize = 0;
inorder(root,returnSize,ret);
return ret;
}
5.7二叉树的后序遍历(LeetCode 145题)
链接:二叉树的后序遍历
思路:
后序遍历也是一样的,我们直接给出代码:
void postorder(struct TreeNode* root,int* index,int* ret)// index 当做数组的下标 ret是数组名称
{
if(NULL == root)
return;
else
{
postorder(root->left,index,ret);
postorder(root->right,index,ret);
ret[(*index)++] = root->val;
}
}
int* postorderTraversal(struct TreeNode* root, int* returnSize){
int* ret =(int*)malloc(100* sizeof(int));
*returnSize = 0;
postorder(root,returnSize,ret);
return ret;
}
6.总结
在这里最重要的就是要我们掌握递归的基本思想。其实不管是哪种遍历方式,我们最终的目的就是访问所有的树(子树)的根节点,左孩子,右孩子(我们以左孩子节点为基准,先序遍历是在访问左孩子节点之前打印节点,中序遍历是在左孩子节点压栈之后打印节点,后序遍历是在访问完左右孩子节点之后打印节点)。当大家不懂时多画图理解(会有意想不到的效果哟!!!)
好了,本期博文就到这里了。如果觉得有用的话记得三连支持哟!!