数据如果在多个表里面,需要进行连接查询。
一般在pandas里面merge合并会用到一个索引,按这个索引的规则进行合并叫做有规则的等值连接。若不按规则连接,遍历两两组合的所有可能性,叫做笛卡尔积。
笛卡尔积连接
通常人们都会设置连接规则,但无条件连接所得到的笛卡尔积有时也非常有用。例如下面的例子。
使用student表和course表的笛卡尔积,生成一个必修课成绩表(bxk_score)的内容,要求是每个学生都应该选择所有的必修课。
CREATE TABLE bxk_score AS
SELECT student.ID as 学号, student.name AS 姓名, course.ID AS 课号, course.course AS 课名
FROM student, course WHERE course.type='必修'
ORDER BY 学号, 课号;运行上面的查询语句后,会生成bxk_Score表,对其执行查询语句如下。
SELECT * FROM bxk_score;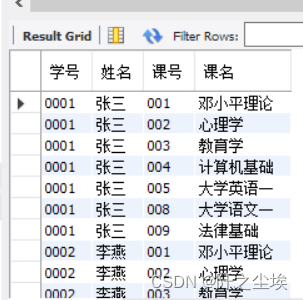
本例使用笛卡尔积,自动生成了bxk_Score表的大部分内容。当然,该表还应该有一个“成绩”字段。该字段的添加可以在后期通过修改表结构的方法解决。
(1)创建一个临时表bbb,该表只有一个数值字段“成绩”。创建表的SQL语句如下所示。
(2)向bbb表插入记录,插入语句如下所示。
(3)修改SELECT语句如下所示。
CREATE TABLE bbb(score int);
INSERT INTO bbb(score) VALUES (0);
CREATE TABLE bxk_score AS
SELECT student.ID as 学号, student.name AS 姓名, course.ID AS 课号, course.course AS 课名,bbb.score
FROM student, course ,bbb WHERE course.type='必修'
ORDER BY 学号,课号;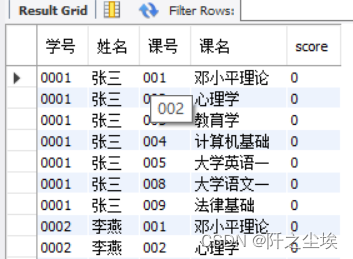
使用两表连接查询数据
数据库操作中,比起使用笛卡尔积,使用有连接规则的连接查询会更频繁一些。下面通过一个例子介绍两表连接查询的具体使用方法。
查询名叫“张三”的学生的所有课程的平时成绩和考试成绩。
分析:student表中有学生姓名,但没有成绩,而存储成绩的score表中有成绩,但没有姓名,不过这两个表都有一个共同字段——学号,所以可以将这两个表连接起来进行查询,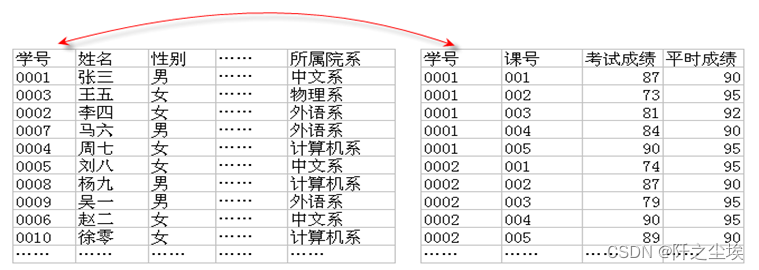
SELECT student.ID AS 学号, student.name AS 姓名, score.c_id AS 课号,score.result2 AS 平时成绩, score.result1 AS 考试成绩
FROM student, score WHERE student.name = '张三' AND student.ID=score.s_id
ORDER BY score.result1 DESC,score.result2 DESC;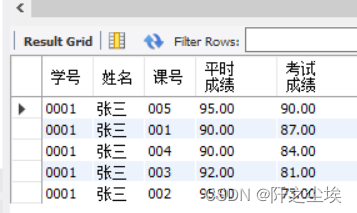
多表连接查询
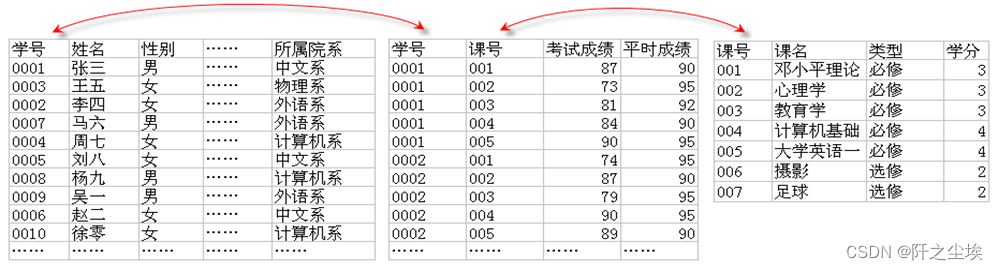
继续上一节的话题,因为用户更希望看到课名,而不是课号,所以必须将存有课名的Course表也连接到Student和Score表上。
查询名叫“张三”的学生的所有课程的平时成绩和考试成绩。
分析:在上一节中,已经知道了Student和Score表可以用共同拥有的学号字段进行连接。接下来的问题是将Course表连接到上述两个表上。由于Student表和Course表没有共同字段所以不能连接,但是Score表和Course表有共同字段——课号,因此Score表和Course表可以连接,如此以来,经过Score表的搭桥,上述三个表就可以连接了,请参考下图所示。
SELECT student.ID AS 学号, student.name AS 姓名, course.course AS 课名, score.result2 AS 平时成绩, score.result1 AS 考试成绩
FROM student, score, course
WHERE student.name = '张三' AND student.ID=score.s_id AND score.c_id=course.id
ORDER BY score.result1 DESC,score.result2 DESC; 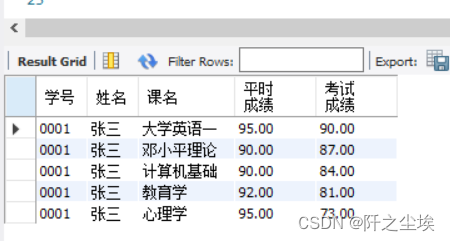
成功把课程代码换成课程名称了。
使用表别名简化语句
在前面曾经介绍过给字段起别名的方法,其实给表起别名与其非常类似。在FROM子句中,在表名的后面加上关键字“AS”和别名即可。例如,下面的查询语句使用表别名简化了上一小节例的查询语句。
SELECT a.ID AS 学号, a.name AS 姓名, c.course AS 课名, b.result2 AS 平时成绩, b.result1 AS 考试成绩
FROM student AS a,score AS b,course AS c
WHERE a.name = '张三' AND a.ID=b.s_id AND b.c_id=c.ID
ORDER BY b.result1 DESC,b.result2 DESC;
例 查询“计算机基础” 课程,考试成绩大于等于90分的学生的学号、姓名、系别和考试成绩,并按考试成绩降序排序。
分析:课程名称在course表中,成绩在score表中,而姓名、系别在student表中,因此想要得到本例要求的结果,则必须对course、score和student三个表进行连接查询。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result1 AS 考试成绩
FROM score AS s,course AS c,student AS st
WHERE c.course='计算机基础' AND s.result1>=90 AND s.c_id=c.ID AND st.ID= s.s_id
ORDER BY s.result1 DESC;
使用INNER JOIN连接查询
因此在ANSI SQL规范中建议使用INNER JOIN进行多表连接。如此以来,WHERE子句中就不用再放置连接规则,而只放置查询条件就可以了。使用INNER JOIN连接n个表的语法格式如下所示。
SELECT *(或字段列表) FROM 表名1
INNER JOIN 表名2
ON 接规则
INNER JOIN 表名3
ON 连接规则
……
INNER JOIN 表名n
ON 连接规则其中,关键字“ON”之后是连接表的规则。
下面通过一个具体例题介绍INNER JOIN的用法。
例 查询所有考过“心理学” 课程的学生的学号、姓名、系别、“心理学”的平时成绩和考试成绩。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result2 AS 平时成绩, s.result1 AS 考试成绩
FROM score AS s
INNER JOIN course AS c ON s.c_id=c.ID
INNER JOIN student AS st ON st.ID= s.s_id
WHERE c.course='心理学' ORDER BY s.result1 DESC;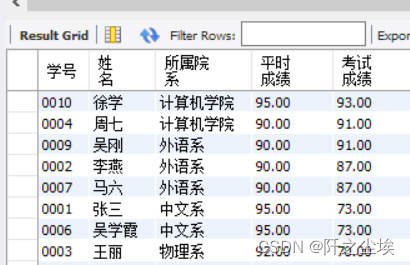
对应的WHERE语句:运行结果和上面相同。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result2 AS 平时成绩, s.result1 AS 考试成绩
FROM score AS s, course AS c, student AS st
WHERE c.course='心理学' AND s.c_id=c.ID AND st.ID=s.s_id
ORDER BY s.result1 DESC;
高级连接查询
自连接查询存
首先通过一个例题说明自连接查询存在的价值,其次介绍自连接查询的使用方法。
从student表中,查询“张三”所在院系的所有学生的信息。
分析:按照以前所学的知识,完成本例的查询任务需要两次查询,首先查询“张三”所在的院系是哪个院系,其次才能查询属于该院系的所有学生的信息。
(1)查询“张三”所在的院系名称。
SELECT institute AS 所属院系
FROM student
WHERE name='张三‘(2)根据上面查询,知道“张三”在中文系学习,下面查询“中文系”所有学生信息。
SELECT * FROM student
WHERE institute='中文系‘上面两条语句可以一句话自连接查询完成,因为自连接查询可以用一条SELECT语句完成本例的查询任务。具体查询语句如下所示。
SELECT st1.* FROM student AS st1, student AS st2
WHERE st1.institute= st2.institute
AND st2.name='张三';
为了强调连接规则的设置,下面再看一个例题。
例 从student表中查询与“吴刚”来源地相同的所有学生学号、姓名和所属院系。
SELECT st1.ID AS 学号, st1.name AS 姓名, st1.institute AS 所属院系
FROM student AS st1, student AS st2
WHERE st2.name='吴刚'
AND st1.origin=st2.origin;
内连接查询存
有规则的连接都属于内连接。内连接包括等值连接、自然连接、和不等值连接。
一、等值连接
前面几节的内容中,连接规则由等于号(=)组合而成,例如,st1.institute= st2.institute,并且列出两个表中所有字段的连接,即SELECT子句中使用星号(*)通配符的连接就属于等值连接。关于等值连接,由于前面的例子已经足够,因此不再具体举例说明。
二、自然连接
在等值连接的基础上稍加改动即可得到自然连接,等值连接将两个表中的所有字段全部列出,而自然连接则不将相同的字段显示两次,即在SELECT子句中列出需要显示的字段列表。
三、不等值连接
不等值连接的连接规则由等于号以外的运算符组成,例如,由>、>=、<、<=、<>或BETWEEN等。下面通过一个例题介绍不等值连接的使用方法。首先创建一个将要使用的年代对照表(nddzb),其创建语句和插入记录的语句分别如下所示。
例 从student表中,查询所有学生的出生年代。
分析:要完成此查询任务,需要将student表和nddzb连接起来,但是这两个表没有共同字段,所以没办法使用等值连接,而根据题意可以使用不等值连接。连接规则是如果student表的出生日期在nddzb的起始年份和终止年份之间就可以连接。
SELECT st.name AS 姓名,st.birthday AS 出生日期, n.年代
FROM student AS st,nddzb AS n
WHERE st.birthday BETWEEN n.起始年份 AND n.终止年份;
外连接查询存
在多表连接查询时,有时希望表的所有记录都被包含进去,即使没能匹配的记录也被查询结果集包含在内。这时,内连接查询已经满足不了需求了,所以应该采用另外一种连接查询方法——外连接查询,例如下图所示。外连接有左外连接、右外连接和全外连接三种。
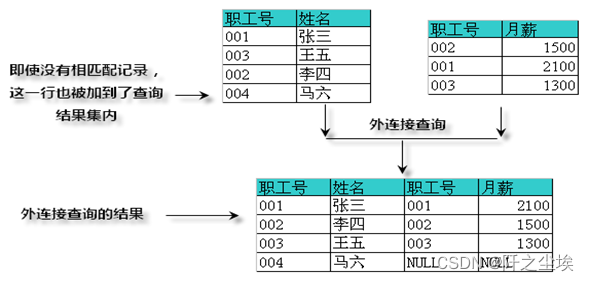
左外连接
这种连接的规则是将左外连接符号(LEFT OUTER JOIN或LEFT JOIN)左边的表的所有记录都包含到结果集中,而只将右边表中有匹配的记录包含进结果集,例如,如图10.22所示。实现图中左外连接的查询语句如下所示。

对应代码
SELECT * FROM t1
LEFT OUTER JOIN t2
ON t1.职工号=t2.职工号通过上图还可以知道,左外连接时,会将左边表的所有记录都会包含到查询结果中,这时,那些没有匹配的左边表的记录会与全部是NULL值的记录连接。
右外连接
这种连接的规则是将右外连接符号(RIGHT OUTER JOIN或RIGHT JOIN)右边的表的所有记录都包含到结果集中,而只将左边表中有匹配的记录才包含进结果集,例如,如图10.23所示。实现图中右外连接的查询语句如下所示。

SELECT * FROM t1
RIGHT OUTER JOIN t2
ON t1.职工号=t2.职工号全外连接
这种连接的规则是将两个表的所有记录都包含到结果集中,而且,这种连接只有一种FULL OUTER JOIN连接符。例如下图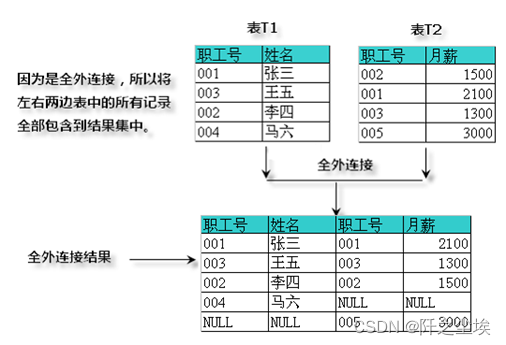
在MySQL中不支持全外连接,要实现全外连接的效果,可以采用关键字UNION来联合左、右连接,具体查询语句如下:
SELECT * FROM t1
LEFT JOIN t2
ON t1.职工号=t2.职工号
UNION
SELECT * FROM t1
RIGHT JOIN t2
ON t1.职工号=t2.职工号
交叉连接查询
交叉连接类似笛卡尔积,无规则连接,例如将学生表和课程表连在一起。会生成120条数据。12(学生数量)*10(课程数量)
下面两种方法是相同的结果。
SELECT * FROM student,course;SELECT * FROM student CROSS JOIN course;
连接查询中使用聚合函数
统计没有考过任何考试的学生人数
SELECT COUNT(*) AS 没有考任何考试的人数 FROM student AS st
LEFT OUTER JOIN score AS s ON st.ID=s.s_id
WHERE s.s_id IS NULL;
组合查询
有时,需要将多个查询语句的结果放到一起,以一个查询结果集的形式将其显示出来。这时就可以使用组合查询,组合查询是使用UNION关键字将多个SELECT查询语句组合起来查询的一种查询方法,其语法格式如下例子所示。
例 从student表中,查询来源地为“北京市”或者所属院系为“计科系”或者年龄大于25岁的学生的信息。运行环境为MySQL。
SELECT * FROM student WHERE origin='北京市'
UNION SELECT * FROM student WHERE institute='计科系'
UNION SELECT * FROM student WHERE TIMESTAMPDIFF(YEAR, birthday, CURDATE())>25;
例 从student表中,查询来源地为“北京市”或 “江苏省”或“内蒙古自治区”的学生的所属院系信息。
(1)下面的语句使用UNION完成查询任务。
SELECT institute AS 所属院系 FROM student WHERE origin='北京市'
UNION SELECT institute AS 所属院系 FROM student WHERE origin='江苏省'
UNION SELECT institute AS 所属院系 FROM student WHERE origin='内蒙古自治区';
(2)下面的语句使用OR完成查询任务。
SELECT institute AS 所属院系 FROM student
WHERE origin='北京市' OR origin='江苏省' OR origin='内蒙古自治区';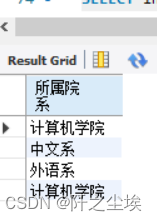
使用UNION时,如果希望不删除重复值,则可以在UNION后加上ALL关键字。
使用UNION的规则
1、每个查询语句应当有相同数量的字段。
在使用UNION组合查询语句时,一定要注意每个单独的SELECT子句内的字段个数一定要相同。如果不同则会出现错误
2、每个查询语句中相应的字段的类型必须相互兼容
在每个查询语句字段个数相等的前提下,相应的字段的类型应当互相兼容。
技巧:当独立查询语句的字段个数不同时,可以在字段个数不够的地方使用常量补位。例如,在上面的第一个SELECT子句中补上一个NULL值,就可以避免错误,具体语句如下所示。
SELECT ID, name, null
FROM student
WHERE origin='北京市'
UNION
SELECT ID, name, birthday
FROM student
WHERE institute='计科系'使用UNION解决不支持全外连接的问题。
如上面的左连接和右连接合并就是全连接了。
使用UNION得到复杂的统计汇总样式
联合UNION、GROUP BY和聚合函数三者会得到具有很棒的统计汇总样式的查询结果,这也是OR所不能替代的。例如,下面的语句会得到一个具有复杂统计汇总样式的查询结果集。
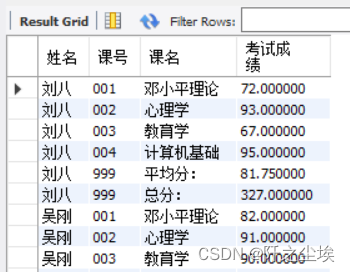
SELECT s_id AS 学号, c_id AS 课号, result1 AS 考试成绩 FROM score
UNION SELECT s_id AS 学号, '总分:', SUM(result1) FROM score GROUP BY s_id
UNION SELECT s_id, '平均分:', AVG(result1) FROM score
GROUP BY s_id ORDER BY 学号, 课号;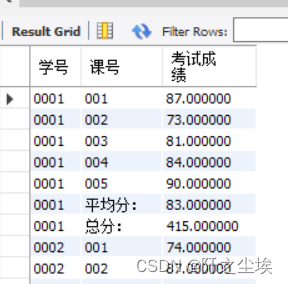
排序组合查询的结果
虽然组合查询中可以有多个单独的SELECT语句,而且每个独立的SELECT语句又都可以拥有自己的WHERE子句、GROUP BY子句和HAVING子句,但是,整个语句中却只能出现一个ORDER BY子句,而且它的位置必须在整个语句的末尾,就是说只能对组合查询最后的结果进行排序,而并不能只对某个单独的SELECT语句的结果进行排序。
SELECT st.name AS 姓名,c.ID AS 课号, c.course AS 课名, s.result1 AS 考试成绩
FROM score AS s, student AS st, course AS c
WHERE s.s_id=st.ID AND s.c_id=c.ID
UNION
SELECT st.name AS 姓名,'999', '总分:',SUM(s.result1) AS 考试成绩
FROM score AS s, student AS st
WHERE s.s_id=st.ID
GROUP BY s.s_id,st.name
UNION
SELECT st.name AS 姓名, '999', '平均分:', AVG(s.result1) AS 考试成绩
FROM score AS s, student AS st
WHERE s.s_id=st.ID
GROUP BY s.s_id,st.name
ORDER BY 姓名, 课号