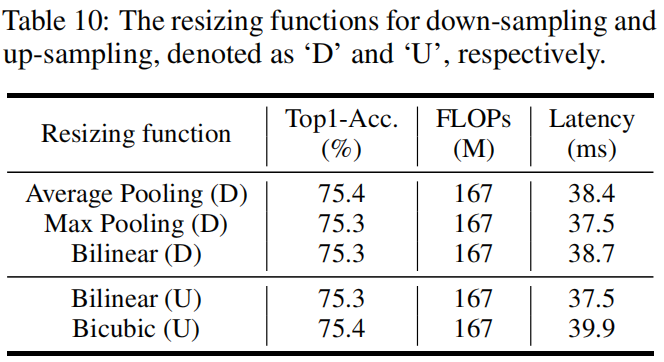
什么是笛卡尔积。就是遍历所有组合的可能性。
比如第一个盒子有[1,2,3]三个号码球,第二个盒子有[4,5]两个号码球。那么从每个盒子里面分别拿一个球共有3*2两种可能性,其集合就是{[1,4],[2,4],[3,4],[1,5],[2,5],[3,5]},这个就是笛卡尔积。
三个盒子也是一样,比如第三个盒子有[6,7,8]个球,那么共有3*2*3,18种可能性。这些可能性的集合就是笛卡尔积。
先举一个pandas里面的例子,两个数据框,每行每行组合:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({"a":[1,2],"b":[3,4]})
df2 = pd.DataFrame({"c":[11,22],"d":[33,44],"e":[55,66]})
df1['value']=1
df2['value']=1
df3 = df1.merge(df2,how='left',on='value')
del df3['value']
df3
相当于df1和df2每行都进行两两组合:df1的第一行配上df2 的第一行,df1的第一行配上df2 的第二行,df1的第二行配上df2 的第一行,df1的第二行配上df2 的第二行。
所以其笛卡尔积df3就是四行。
学生课程案例
那上面这个笛卡尔积有什么用?
举个例子,比如我有两个表:
df_student
上面这个是学生信息表,还有一个课程表:
df_course
我想准备生成一个新的数据框,包括所有学生的 所有课程的 成绩。
那么就应该有12(学生数量)*10(课程数量)条数据。
可以用下面这个方法实现:(其实是新增了temp一列当做临时键,合并完再删掉)
#笛卡尔积
df_stu_cour=pd.merge(df_student[['# ID','name']].assign(temp=1),df_course.assign(temp=1),on='temp',how='left').drop(columns=['temp'])
df_stu_cour
这样就生成了笛卡尔积的表,120条没问题,ID_x是学生的ID,ID_y是课程的ID。
此时每个学生考每门课的成绩填到后面就行。
如果我已经有他们对应的每个学生每门课的成绩分数表,但是不是名字和课程名字,而是学生ID和课程ID,那我需要和刚刚做出来的表进行合并怎么办呢?
先查看我的分数表:
df_score
合并,安装学生ID和课程ID两个关键词合并:
df_stu_cour.merge(df_score,left_on=['# ID_x','# ID_y'],right_on=['# s_id','c_id'],how='outer').tail(30)
我采用的是并集合并,所以一定有120条,如果分数表里面没有的学生的课程分数,就会是NAN空值。