文章目录
- 一、NumPy 简介
- 1. 为什么要使用 NumPy
- 2. NumPy 数据类型
- 3. NumPy 数组属性
- 4. NumPy 的 ndarray 对象
- 二、numpy.array() 创建数组
- 1. 基础理论
- 2. 基础操作演示
- 3. numpy.array() 参数详解
- 三、numpy.arange() 生成区间数组
- 四、numpy.linspace() 创建等差数列
- 五、numpy.logspace() 创建等比数列
- 六、numpy.zeros() 创建全零数列
- 七、np.ones() 创建一数列
一、NumPy 简介
- NumPy(Numerical Python)是 Python 的一种开源的数值计算扩展。
- 这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- 使用 NumPy 可以方便的使用数据、矩阵进行计算,包含线性代数、傅里叶变化、随机数生成等大量函数。
1. 为什么要使用 NumPy
- Numpy 是 Python 各种数据科学类库的基础库,比如:Scipy,Scikit-Learn、TensorFlow、pandas等。
- 对于同样的数值计算任务,使用 NumPy 比直接使用 Python 代码实现有如下优点:
- (1) 代码更简洁:NumPy 直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而 python 需要用 for 循环从底层实现;
- (2) 性能更高效:NumPy 的数组存储效率和输入输出计算性能,比 Python 使用 List 或者嵌套 List 好很多。
- 这里有两点需要注意需要注意是,其一,Numpy 的数据存储和 Python 原生的 List 是不一样的。
- 其二,NumPy 的大部分代码都是 C 语言实现的,这是 Numpy 比纯 Python 代码高效的原因。
2. NumPy 数据类型
- NumPy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。
- 下表列举了常用 NumPy 基本类型:
| 名称 | 描述 |
|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
- NumPy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
3. NumPy 数组属性
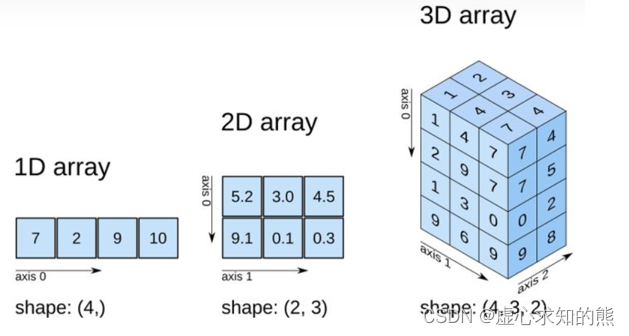
- NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
- 在 NumPy 中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
- 比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
- 很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
- NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray 元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
4. NumPy 的 ndarray 对象
- NumPy 定义了一个 n 维数组对象,简称 ndarray 对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
- ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
二、numpy.array() 创建数组
1. 基础理论
- 基本的 ndarray 是使用 NumPy 中的数组函数创建的,如下所示:
numpy.array
- 它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个 ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 序号 | 参数 | 描述 |
|---|
| 1 | object | 表示一个数组序列。 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型。 |
| 3 | copy | 可选参数,当数据源是ndarray时表示数组能否被复制,默认是 True。 |
| 4 | order | 可选参数,以哪种内存布局创建数组,有 3 个可选值,分别是 C(行序列)、F(列序列)、A(默认)。 |
| 5 | subok | 可选参数,类型为bool值,默认 False。为 True,使用object的内部数据类型;False:使用object数组的数据类型。 |
| 6 | ndmin | 可选参数,用于指定数组的维度。 |
2. 基础操作演示
import numpy as np
- NumPy 引入完成后,实现 array 创建数组。
- 在 array() 函数当中,括号内可以是列表、元组、数组、迭代对象,生成器等。
- 其中,列表和元组的整体相同,但是列表属于可变序列,它的元素可以随时修改或删除,元组是不可变序列,其中元素不可修改,只能整体替换。
- (1) 列表:
np.array([1,2,3,4,5])
np.array((1,2,3,4,5))
a = np.array([1,2,3,4,5])
np.array(a)
np.array(range(10))
np.array([i**2 for i in range(10)])
- 当数组内的元素数据类型不相同时,那么数组内哪种数据类型存储的结果最大,就按哪种数据类型进行存储。
- 如下例子,在数组当中,包含整型,浮点型和字符串,其中字符串的数据类型存储结果最大,因此,数组内的所有元素均按字符串进行存储。
np.array([1,1.5,3,4.5,'5'])
ar1 = np.array(range(10))
ar1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- (2) 浮点型(浮点型的数据存储大于整型的数据存储,因此全部转换为浮点型):
ar2 = np.array([1,2,3.14,4,5])
ar2
ar3 = np.array([
[1,2,3],
('a','b','c')
])
ar3
ar4 = np.array([[1,2,3],('a','b','c','d')])
ar4
- 上述例子的秩是 1,可以通过 ar4.ndim 进行查看。
3. numpy.array() 参数详解
a = np.array([1,2,3,4,5])
print(a)
has_dtype_a = np.array([1,2,3,4,5],dtype='float')
has_dtype_a
- 如果将浮点型的数据,设置为整形,那么,数组内元素会自动舍弃尾数,转换为整型数据,具体输出如下所示。
np.array([1.1,2.5,3.8,4,5],dtype='int')
- (2) 设置 copy 参数,默认为 True。
- 我们设置 a 数组,然后,通过 a 数组复制得出 b 数组,此时,a 数组和 b 数组的地址不相同,创建了新的对象。
- 那么,对 a 数组和 b 数组的任意修改都不会影响另一个数组的元素。
a = np.array([1,2,3,4,5])
b = np.array(a)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print(a)
- 当我们修改 b 数组的元素时,a 数组不会发生变化。
b[0] = 10
print('a:', a,' b:', b)
- 当设置 copy 参数为 Fasle 时,不会创建副本,两个变量会指向相同的内容地址,没有创建新的对象。
- 此时,由于 a 数组和 b 数组指向的是相同的内存地址,因此当修改 b 数组的元素时,a 数组对应的元素会发生变化。
a = np.array([1,2,3,4,5])
b = np.array(a, copy=False)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print('a:',a,' b:',b)
- (3) ndmin 用于指定数组的维度。
- 将一维数组转换为二维数组。
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3], ndmin=2)
a
- (4) subok 参数,类型为 bool 值,默认 False。为 True 时,使用 object 的内部数据类型;False:使用 object 数组的数据类型。
- 首先,创建一个 a 矩阵,然后输出 a 矩阵的数据类型,便于后面的比较。
- 其次,通过 a 矩阵生成 at 和 af 两个数组,at 数组的 subok 参数设置为 True,at 数组的 subok 参数不设置,即默认为 False。
- 最后,输出 at 数组和 af 数组的数据类型,用于比较观察。
a = np.mat([1,2,3,4])
print(type(a))
at = np.array(a,subok=True)
af = np.array(a)
print('at,subok为True:',type(at))
print('af,subok为False:',type(af))
print(id(at),id(a))
a = np.array([2,4,3,1])
- 在定义 b 数组时,如果想复制 a 数组,有如下几种方案:
- (1) 使用 np.array()。
- (2) 使用数组的 copy() 方法。
b = np.array(a)
print('b = np.array(a):',id(b),id(a))
c = a.copy()
print('c = a.copy():',id(c),id(a))
- 注意不能直接使用 = 号复制,直接使用 = 号,会使 2 个变量指向相同的内存地址。
三、numpy.arange() 生成区间数组
- 根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
numpy.arange(start, stop, step, dtype)
| 序号 | 参数 | 描述说明 |
|---|
| 1 | start | 起始值,默认为 0 |
| 2 | stop | 终止值(不包含) |
| 3 | step | 步长,默认为 1 |
| 4 | dtype | 返回 ndarray 的数据类型,如果没有提供,则会使用输入数据的类型。 |
- 如果只有一个参数,那么起始值就是 0,终止值就是那个参数,步长就是 1。
- 如果有两个参数,那么,第一个参数就是起始值,第二个参数就是终止值。
np.arange(10)
np.arange(3.1)
x = np.arange(5, dtype = float)
x
- 设置了起始值、终止值及步长:
- (1) 起始值是 10,终止值是 20,步长是 2。
np.arange(10,20,2)
- (1) 起始值是 0,终止值是 20,步长是 3。
ar2 = np.arange(0,20,3)
print(ar2)
ar3 = np.arange(20,step=3)
ar3
- 如果数组太大而无法打印,NumPy 会自动跳过数组的中心部分,并只打印边角。
np.arange(10000)
四、numpy.linspace() 创建等差数列
- 返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等差数列构成。
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
| 序号 | 参数 | 描述说明 |
|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果 endpoint 为 True,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 True 时,数列中包含 stop 值,反之不包含,默认是 True。 |
| 5 | retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| 6 | dtype | ndarray 的数据类型 |
- 以下例子用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
a = np.linspace(1,10,10)
a
- 如果,我们将 endpoint 设置为 False,就不会包含 10,此时,默认步长是 50。
a = np.linspace(1,10,endpoint=False)
a
- 以下实例用到三个参数,设置起始位置为 2.0,终点为 3.0,数列个数为 5。
ar1 = np.linspace(2.0, 3.0, num=5)
ar1
- 将参数 endpoint 设置为 False 时,不包含终止值,
ar1 = np.linspace(2.0, 3.0, num=5, endpoint=False)
ar1
ar1 = np.linspace(2.0,3.0,num=5, retstep=True)
print(ar1)
type(ar1)
- 将 endpoint 设置为 False,不包含终止值,再设置 retstep 显示计算后的步长。
ar1 = np.linspace(2.0,3.0,num=5,endpoint=False,retstep=True)
ar1
- 等差数列在线性回归经常作为样本集,例如:生成 x_data,值为 [0, 100] 之间 500 个等差数列数据集合作为样本特征,根据目标线性方程
y
=
3
×
x
+
2
y=3×x+2
y=3×x+2,生成相应的标签集合 y_data。
x_data = np.linspace(0,100,500)
x_data
五、numpy.logspace() 创建等比数列
- 返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等比数列构成。
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
| 序号 | 参数 | 描述说明 |
|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| 5 | base | 对数 log 的底数 |
| 6 | dtype | ndarray 的数据类型 |
a = np.logspace(0,9,10,base=2)
a
- 上述代码可以理解为
2
0
2^{0}
20 到
2
9
2^{9}
29。
- np.logspace(A,B,C,base=D) 中的参数分别是如下含义:
- A:生成数组的起始值为 D 的 A 次方。
- B:生成数组的结束值为 D 的 B 次方。
- C:总共生成 C 个数。
- D:指数型数组的底数为 D,当省略 base=D 时,默认底数为 10。
- 我们先使用前 3 个参数,将 [1,5] 均匀分成 3 个数,得到 {1,3,5},然后利用第 4 个参数 base=2(默认是 10)使用指数函数可以得到最终输出结果 {
2
1
2^{1}
21,
2
3
2^{3}
23,
2
5
2^{5}
25}。
np.logspace(1,5,3,base=2)
np.logspace(1.0,2.0,num=10)
- 上述实际上是
1
0
1
10^{1}
101 到
1
0
2
10^{2}
102。
六、numpy.zeros() 创建全零数列
numpy.zeros(shape, dtype = float, order = 'C')
| 序号 | 参数 | 描述说明 |
|---|
| 1 | shape | 数组形状 |
| 2 | dtype | 数据类型,可选 |
np.zeros(5)
np.zeros((5,), dtype = 'int')
array([0, 0, 0, 0, 0])
np.zeros((2,2))
- 使用 zeros_like 可以返回具有与给定数组相同的形状和类型的零数组。
ar1 = np.array([[1,2,3],[4,5,6]])
np.zeros_like(ar1)
七、np.ones() 创建一数列
ar5 = np.ones(9)
ar6 = np.ones((2,3,4))
ar7 = np.ones_like(ar3)
print('ar5:',ar5)
print('ar6:',ar6)
print('ar7:',ar7)