文章目录
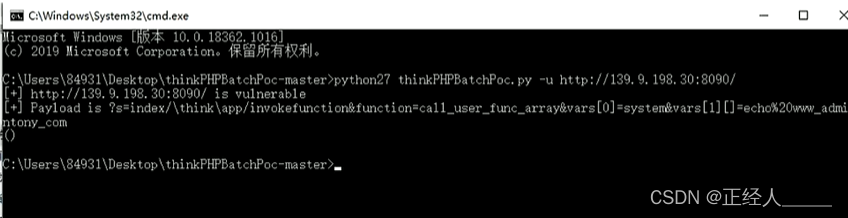
- 1.概述
- 2.练习:字符串中字符统计
- 3.Map与HashMap的比较
- 4.HashMap扩容
1.概述
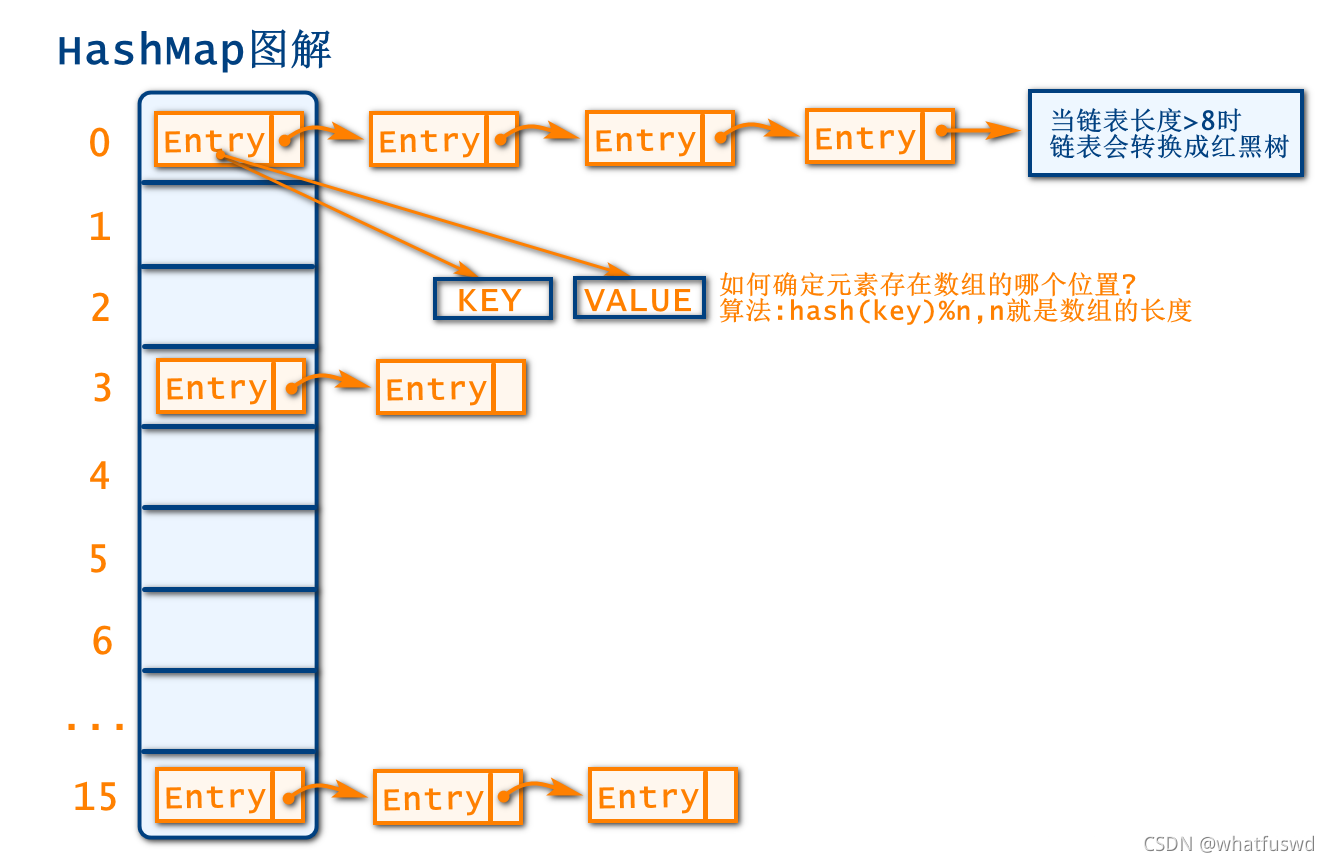
HashMap底层是一个Entry[ ]数组,长度为16,当存放数据时,会根据hash算法来计算数据的存放位置
算法:hash(key)%n , n就是数组的长度,其实也就是集合的容量
当计算的位置没有数据的时候,会直接存放数据
当计算的位置,有数据时,会发生hash冲突/hash碰撞,解决的办法就是采用链表的结构,在数组中指定位置处已有元素之后插入新的元素,也就是说数组中的元素都是最早加入的节点
- HashMap的结构是数组+链表 或者 数组+红黑树的形式
- HashMap底层的Entry[ ]数组,初始容量为16,加载因子是0.75f,扩容按约为2倍扩容
- 当存放数据时,会根据hash(key)%n算法来计算数据的存放位置,n就是数组的长度,其实也就是集合的容量
- 当计算到的位置之前没有存过数据的时候,会直接存放数据
- 当计算的位置,有数据时,会发生hash冲突/hash碰撞
解决的办法就是采用链表的结构,在数组中指定位置处以后元素之后插入新的元素
也就是说数组中的元素都是最早加入的节点 - 如果链表的长度>8时,链表会转为红黑树,当链表的长度<6时,会重新恢复成链表
2.练习:字符串中字符统计
package partThree;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
/**
* 本类用来完成Map集合相关练习
* 需求:提示并接收用户输入的一串字符,并且统计出每个字符出现的次数
* */
public class TestMap2 {
public static void main(String[] args) {
//1.提示用户输入要统计的字符串
System.out.println("请输入您要统计的字符串");
//2.接收用户输入的要统计的字符串
String input = new Scanner(System.in).nextLine();
//3.获取到用户输入的每个字符,String底层维护的是char[]
//创建map集合存放数据,格式:{b=2,d=4,g=3}
/**统计的是每个字符出现的次数,所以字符是char类型,次数是int,但是不可以使用基本类型,需要使用包装类型*/
Map<Character,Integer> map = new HashMap();
//开始位置:0 - 数组的第一个元素
//结束位置:<input.length() 或者 <=input,length()-1
//如何变化:++
for (int i = 0; i < input.length(); i++) {
char key = input.charAt(i);//获取一串字符中指定位置上的字符
System.out.println("获取到的第"+(i+1)+"个字符:"+key);
//4.统计每个字符出现的个数,存起来,存到map
Integer value = map.get(key);//要先拿着key到map中找是不是有value
if(value == null) {//如果判断为null,说明之前没有存过这个字符
map.put(key, 1);//把当前的字符作为key存入,次数存1
}else {
map.put(key,value+1);//如果存过值,给之前的次数+1
}
}
System.out.println("各个字符出现的频率为:");
System.out.println(map);
}
}
3.Map与HashMap的比较
-
Map是一个接口,HashMap是一个Map的实现类(HashMap继承了AbstractMap类,实现了Map接口);
-
它们都是以键值对的双列储存,一个键对应一个值,键不可重复,值可以重复。而且他们的存储是无序的和放入的前后顺序无关;
-
他们都是只能有一个键为null的数据,但是可以有多个记录的值为null如下:
[null:adc,a:null,b:null] -
HashMap是项目中最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。
-
HashMap不支持线程的同步,是非线程安全的,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要同步,可以用 Collections和synchronizedMap方法使HashMap具有同步能力,或者使用ConcurrentHashMap。
-
项目中大多使用的格式为:
Map map = new HashMap<>();
4.HashMap扩容
成长因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
前面的讲述已经发现,当你空间只有仅仅为10的时候是很容易造成2个对象的hashcode 所对应的地址是一个位置的情况。这样就造成 2个 对象会形成散列桶(链表)。这时就有一个加载因子的参数,值默认为0.75 ,如果你hashmap的 空间有 100那么当你插入了75个元素的时候 hashmap就需要扩容了,不然的话会形成很长的散列桶结构,对于查询和插入都会增加时间,因为它要一个一个的equals比较。但又不能让加载因子很小,如0.01,这样显然是不合适的,频繁扩容会大大消耗你的内存。这时就存在着一个平衡,jdk中默认是0.75,当然负载因子可以根据自己的实际情况进行调整。