引子
前两天刷抖音,看见了这样一个问题。
问题:容器化不做虚拟内核,会有什么弊端?Java很多方法会跟CPU的核数有关,这个时候调用系统函数,读到的是宿主机信息,而不是我们限制资源的大小。
思考:在我们.NET中是否也会出现这种问题呢?
环境准备
1. 准备程序
在我们.NET中,并行编程(Parallel)或者线程池(ThreedPool)中,默认会根据CPU数量对我们进行线程分配。
于是我就从Parallel中,找到TaskReplicator类(该类主要用于同时在一个或多个Task中运行委托)下的GenerateCooperativeMultitaskingTaskTimeout方法。
privatestaticintGenerateCooperativeMultitaskingTaskTimeout()
{
// This logic ensures that we have a diversity of timeouts across worker tasks (100, 150, 200, 250, 100, etc)// Otherwise all worker will try to timeout at precisely the same point, which is bad if the work is just about to finish.int period = Environment.ProcessorCount;
int pseudoRnd = Environment.TickCount;
return CooperativeMultitaskingTaskTimeout_Min + (pseudoRnd % period) * CooperativeMultitaskingTaskTimeout_Increment;
}抽取获取处理器数量方法Environment.ProcessorCount,放到控制台中。
internalclassProgram
{
staticvoidMain(string[] args)
{
Console.WriteLine("获取宿主机器处理器数量:"+Environment.ProcessorCount);
Console.ReadLine();
}
}2. 环境准备
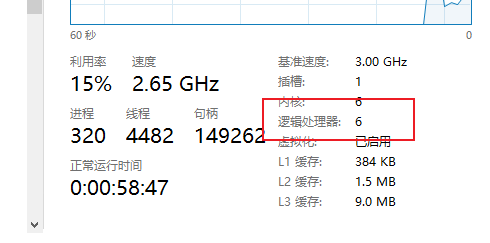
本机CPU--6个
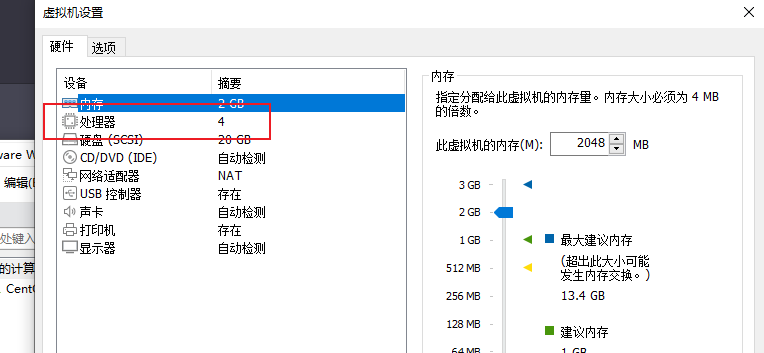
虚拟机分配CPU--4个
Docker分配CPU--1个
测试结果
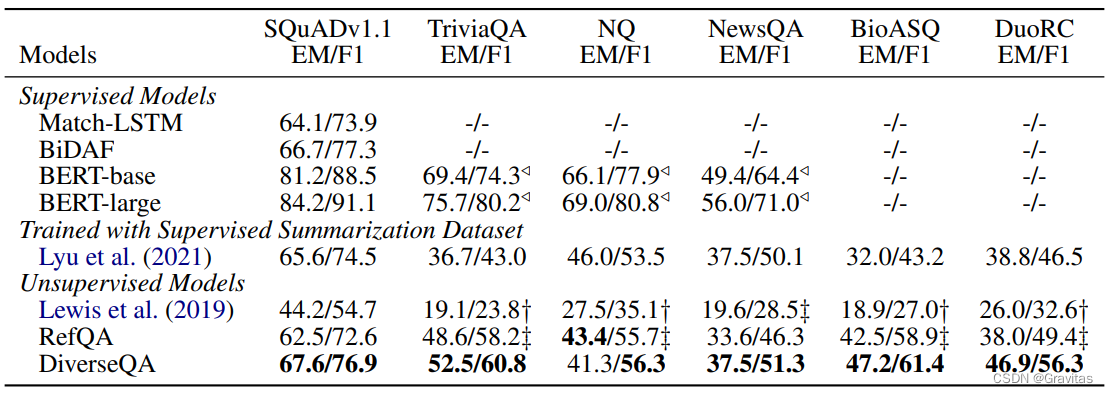
程序最终获取CPU数量是虚拟机的数量
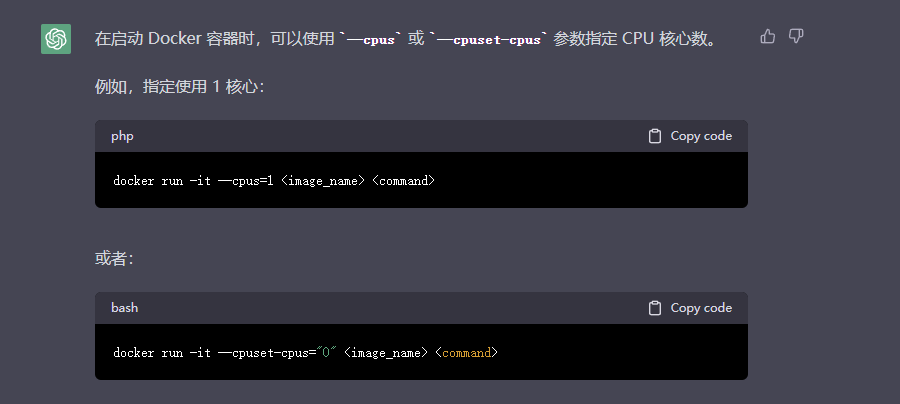
采用cpus结果:

采用–cpuset-cpus命令结果:

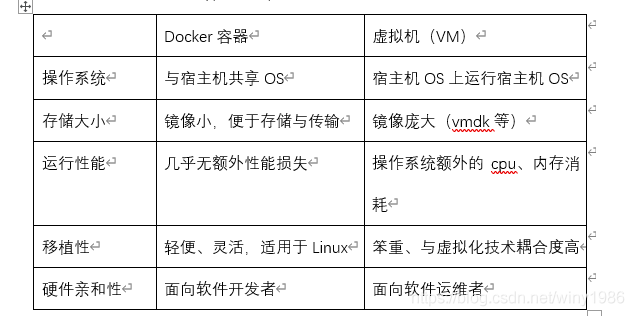
Docker和虚拟机的区别:
2.分析需求
put数据时:
key值hash后的索引处没有元素,需要创建链表头节点,放到该位置的数组空间里。
key值hash后的索引处有元素,说明产生Hash碰撞,需要在链表中结尾处挂载节点,如果在遍历链表的过程中,发现了同key的数据,则执行覆盖即可,不再继续往下遍历去挂载新节点。
假设数组使用的空间超过了总长度的75%,那么对数组进行扩容。先创建新数组,把旧数据写到新数组中(此时需要重新根据key计算Hash,因为数据长度变化了,影响计算结果了),在用新数据替换掉原来的旧数组。
get数据时:
key值hash后的索引下标处的元素为空的话,则不存在数据。
key值hash后的索引下标处存在链表的话,需要遍历链表,找到key相对应的value值。
3.代码实现
Node类实现
package com.zaevn.hashmap;
/**
* @author: zae
* @date: 2023/1/30
* @time: 11:25
*/publicclassNode {
String key;
String value;
Node next;
publicNode(String key, String value, Node nextNode) {
this.key = key;
this.value = value;
this.next = nextNode;
}
}
LinkNode类实现
package com.zaevn.hashmap;
/**
* @author: zae
* @date: 2023/1/30
* @time: 11:27
*/publicclassListNode {
// 头节点
Node head;
/**
* 添加数据,挂载链表的节点
* @param key
* @param value
*/publicvoidaddNode(String key,String value){
// 如果头节点是空,则结束if(head == null ){return;}
// 如果头节点不为空,则往下挂载节点Nodenode=newNode(key,value,null);
Nodetemp= head;
while(true){
// 遇到相同的key,覆盖数据if(key.equals(temp.key)){
temp.value = value;
return;
}
if(temp.next == null){
break;
}
temp = temp.next;
}
// 循环结束后则挂上数据
temp.next = node;
}
/**
* 获取数据
* @param key
* @return
*/public String getNode(String key){
if(head == null ){returnnull;}
Nodetemp= head;
while(true){
if(key.equals(temp.key)){
return temp.value;
}
if(temp.next == null){
break;
}
temp = temp.next;
}
returnnull;
}
}
MyHashMap类实现
package com.zaevn.hashmap;
/**
* @author: zae
* @date: 2023/1/30
* @time: 11:27
*/publicclassMyHashMap {
// 数组初始化:2的n次方
ListNode[] map = newListNode[8];
// ListNode的个数int size;
// 由于扩容时是先创建一个新数组,因此先声明出来
ListNode[] mapNew;
int sizeNew;
/**
* put方法
* @param key
* @param value
*/publicvoidput(String key,String value){
if(size>map.length * 0.75){
System.out.println("开始进行扩容,当前size="+size+",数组长度为:"+map.length);
doExtendMap();
System.out.println("扩容结束,当前size="+size+",数组长度为:"+map.length);
}
// 1.对key进行hash算法然后取模intindex= Math.abs(key.hashCode())%map.length;
ListNodelistNode= map[index];
// 如果索引位置的元素为空,则新加一个元素(创建头节点)if(listNode == null){
ListNodelistNodeNew=newListNode();
Nodenode=newNode(key,value,null);
listNodeNew.head = node;
map[index] = listNodeNew;
size ++;
}else{
// 如果索引位置的元素不为空,则往链表中挂载数据
listNode.addNode(key,value);
}
}
public String get(String key){
// 1.对key进行hash算法然后取模intindex= Math.abs(key.hashCode())%map.length;
if(map[index] == null){
returnnull;
}else{
return map[index].getNode(key);
}
}
/**
* 达到阈值后开始进行扩容
*/publicvoiddoExtendMap(){
sizeNew = 0;
// 1.先创建一个新的数组,长度为原来的二倍
mapNew = newListNode[map.length * 2];
// 2.将旧数据映射到新的数组上(因为数组长度变化,因此hash规则变化,所有的值需要重新计算hash值)for(inti=0;i<map.length;i++){
ListNodelistNode= map[i];
if(listNode == null){
continue;
}
Nodetemp= listNode.head;
while (true){
doPutData(mapNew,temp.key,temp.value);
if(temp.next == null){
break;
}
temp = temp.next;
}
}
// 3.将新的数组替换旧的数组
map = mapNew;
this.size = sizeNew;
}
privatevoiddoPutData(ListNode[] mapParam,String key,String value){
intindex= Math.abs(key.hashCode())%mapParam.length;
ListNodelistNode= mapParam[index];
if(listNode == null){
ListNodelistNodeNew=newListNode();
Nodenode=newNode(key,value,null);
listNodeNew.head = node;
mapParam[index] = listNodeNew;
sizeNew ++;
}else{
listNode.addNode(key,value);
}
}
publicstaticvoidmain(String[] args) {
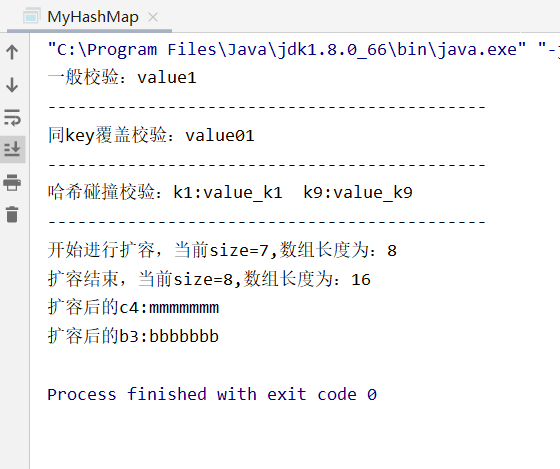
// 1、一般校验
MyHashMap hashMap0=newMyHashMap();
hashMap0.put("key1","value1");
System.out.println("一般校验:"+hashMap0.get("key1"));
System.out.println("--------------------------------------------");
// 2、同key覆盖校验
MyHashMap hashMap1=newMyHashMap();
hashMap1.put("key2","value00");
hashMap1.put("key2","value01");
System.out.println("同key覆盖校验:"+hashMap1.get("key2"));
System.out.println("--------------------------------------------");
// 3、哈希碰撞校验(k1和k9的经过哈希计算后得到的索引都是6)
MyHashMap hashMap2=newMyHashMap();
hashMap2.put("k1","value_k1");
hashMap2.put("k9","value_k9");
System.out.println("哈希碰撞校验:k1:"+hashMap2.get("k1")+" k9:"+hashMap2.get("k9"));
System.out.println("--------------------------------------------");
// 4、扩容校验
MyHashMap hashMap3=newMyHashMap();
hashMap3.put("m3","cccccc");
hashMap3.put("c1","kkkkkk");
hashMap3.put("c2","mmmmmmm");
hashMap3.put("b1","bbbbbbb");
hashMap3.put("m1","cccccc");
hashMap3.put("c3","kkkkkk");
hashMap3.put("c4","mmmmmmm");
hashMap3.put("b2","bbbbbbb");
hashMap3.put("m2","cccccc");
hashMap3.put("c5","kkkkkk");
hashMap3.put("c6","mmmmmmm");
hashMap3.put("b3","bbbbbbb");
System.out.println("扩容后的c4:"+hashMap3.get("c4"));
System.out.println("扩容后的b3:"+hashMap3.get("b3"));
}
}
3.运行结果