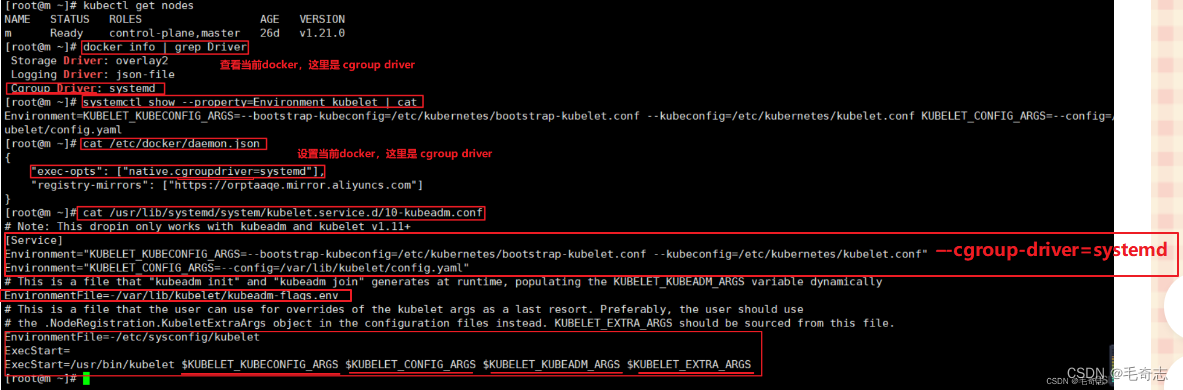
文章目录
- 一:CycleGAN
- (1)概述
- (2)双判别器
- (3)损失函数
- 二:StyleGAN
- (1)解耦表征学习
- (2)概述
- 三:DCGAN
一:CycleGAN
(1)概述
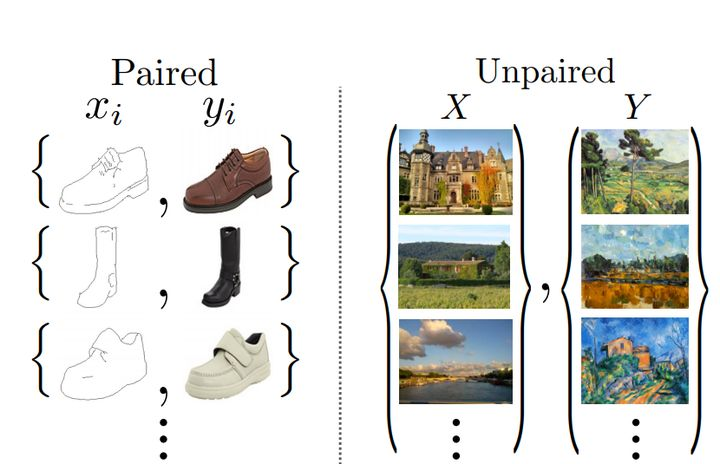
CycleGAN:它是一种实现图像风格转换功能的GAN网络。其实早在CycleGAN出现之前,就存在着Pix2Pix这样的模型进行图像风格转换,但是它的局限性很大,因为要求所输入的图片必须是成对的(paired),但在现实中这种图像很难收集。而CycleGAN不要求图像成对(unpaired),所以非常实用
例如下图输入 X X X的图片,可以是任意的,甚至是自己画的,然后 Y Y Y的图片是梵高风格的画像,CycleGAN训练之后就会把任何输入的图像转化为梵高风格的画像
其实不止是图像风格化,CycleGAN还可以运用在语音处理方面,例如声音的变声,可以把任意声音声音和郭德纲声音去训练,这样你说出的话就会被转换成郭德纲声音
(2)双判别器
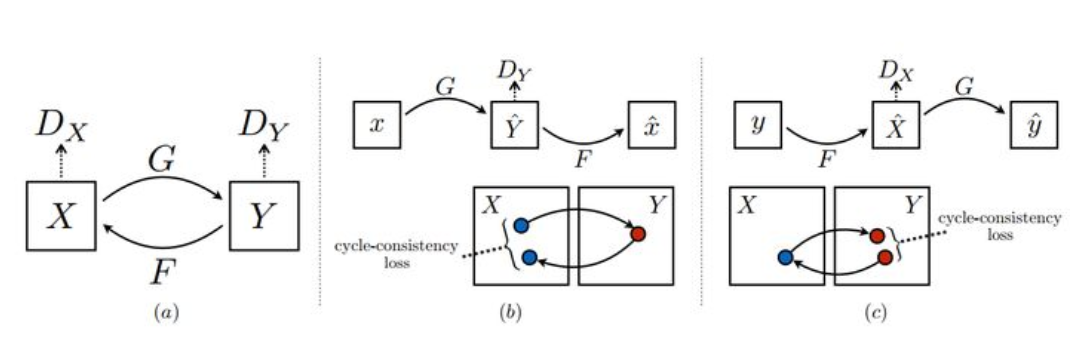
CycleGAN的核心在于其双判别器结构,如下图
- G G G:从X到Y的生成器
- F F F:从Y到X的生成器
- D X D_{X} DX:鉴别是否为 X X X的鉴别器
- D Y D_{Y} DY:鉴别是否为 Y Y Y的鉴别器
训练时包含两个过程
- 由 x x x经过 G G G生成 Y ︿ \mathop{Y}\limits^{︿} Y︿,然后将 Y ︿ \mathop{Y}\limits^{︿} Y︿送入 D Y D_{Y} DY进行鉴别,再把 Y ︿ \mathop{Y}\limits^{︿} Y︿送入F中生成 x ︿ \mathop{x}\limits^{︿} x︿
- 由 y y y经过 F F F生成 X ︿ \mathop{X}\limits^{︿} X︿,然后将 X ︿ \mathop{X}\limits^{︿} X︿送入 D X D_{X} DX进行鉴别,再把 X ︿ \mathop{X}\limits^{︿} X︿送入G中生成 y ︿ \mathop{y}\limits^{︿} y︿
(3)损失函数
损失函数:由对抗损失和Cycle Consistency损失构成
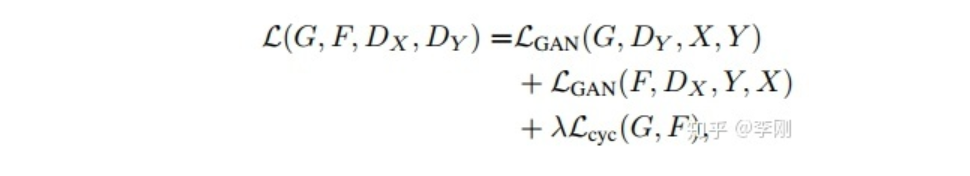
由 X X X生成 Y Y Y和由 Y Y Y生成 X X X这两部分损失函数和最初的GAN是一样的
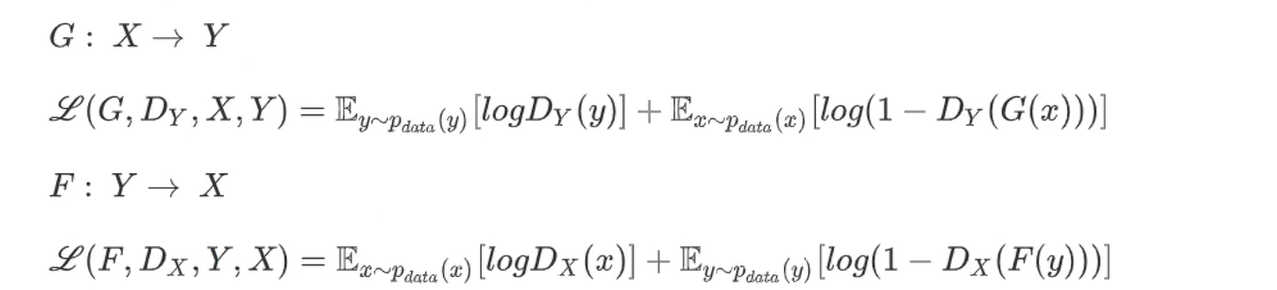
单独对抗损失不能保证可以映射单个输入,举个例子: G G G和 F F F可能合伙偷懒骗人,给 G G G一个图, G G G偷偷把小狗变成梵高自画像, F F F再把梵高自画像变成输入。引入Cycle Consistency可以制止这种行为,他用梵高其他画作测试FG,用另外真实图片测试GF,看看是否可以变回原来的样子,这样做就保证了GF在整个X、Y分布区间的普适性
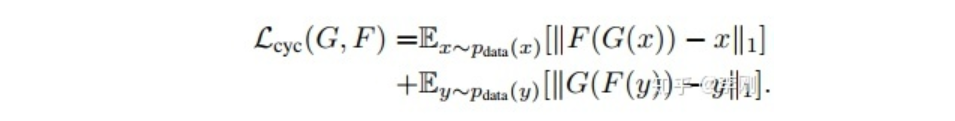
二:StyleGAN
(1)解耦表征学习
人工神经网络其本质就是在进行表征学习,但是他是一种黑盒算法,不具备可解释性,往往是通过大量数据训练出的结果,所以其泛化能力不是很高。这是因为,人工神经网络所学习到的特征是纠缠在一起的,或者说是耦合的,例如下图是一只狸花猫,人工神经网络可以轻易学习到这种猫的特征,但是如果换一种猫,甚至说只是换一个颜色,那可能效果就不尽如人意了,可以看到其颜色、形状、姿势等特征是耦合在一起的
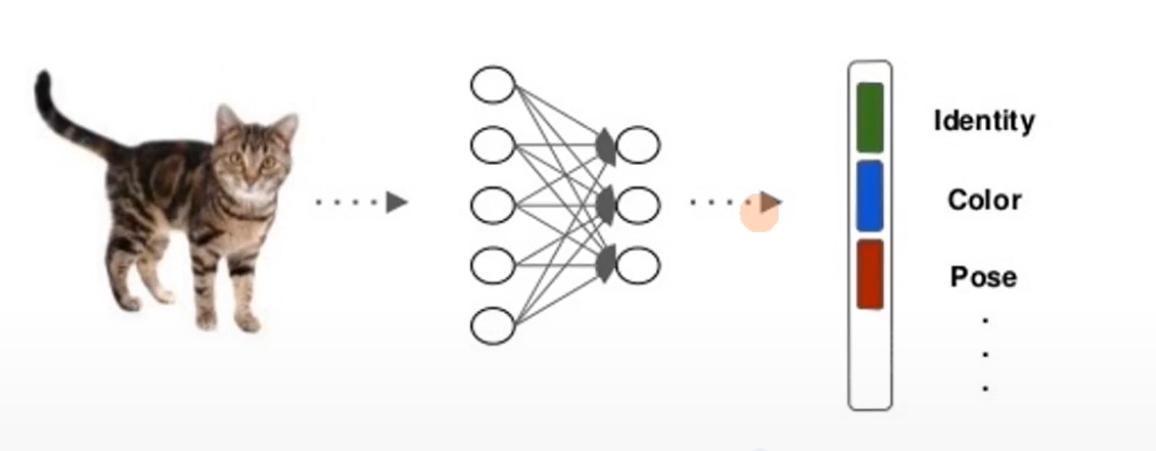
而人类对于物体的学习天然就是解耦的,面对颜色各异的杯子,我们在学习到杯子的基本特征后,不会因为只是颜色不同就无法识别出来

后面会说到的styleGAN所做的就是解耦表征学习,这也是近几年十分火热的话题。下图是styleGAN通过控制发色、眼睛、皮肤等单因素或特征生成人脸图像

解耦表征学习非常重要,因为一旦它可以做到
- 使神经网络的输出可解释,神经网络不再是一个黑盒算法。其为什么能和为什么不能都可以得到解答
- 使GAN输出可控
- 进行少样本、零样本学习:其目的是在于模拟人类的认知,人类可以从极少的样本甚至是没有样本中进行学习
(2)概述
- StyleGAN 架构解读(重读StyleGAN)精【1】
三:DCGAN
DCGAN:全名叫做Deep Convolutional Genrative Adversarial Networks,将GAN与CNN结合在一起,这篇文章于2016年发表,在这之前CNN主要应用在监督学习中,而这篇文章将CNN应用在了无监督学习中,效果也是很好
最原始的GAN所使用的生成器和判别器模型只是简单的全连接层的堆叠,而DCGAN将这些全连接层更换为了卷积结构。DCGAN主要特点

生成器模型
生成器模型从效果上看与传统的卷积结构是相反的,因为在CNN中特征图的尺寸是越来越小的,是一个下采样的过程,但是这个结构的特征图却变得越来越大,反而是上采样。你可以将其理解为反卷积,虽然这个叫法是错误的,但比较直观,准确来讲应该叫做转置卷积
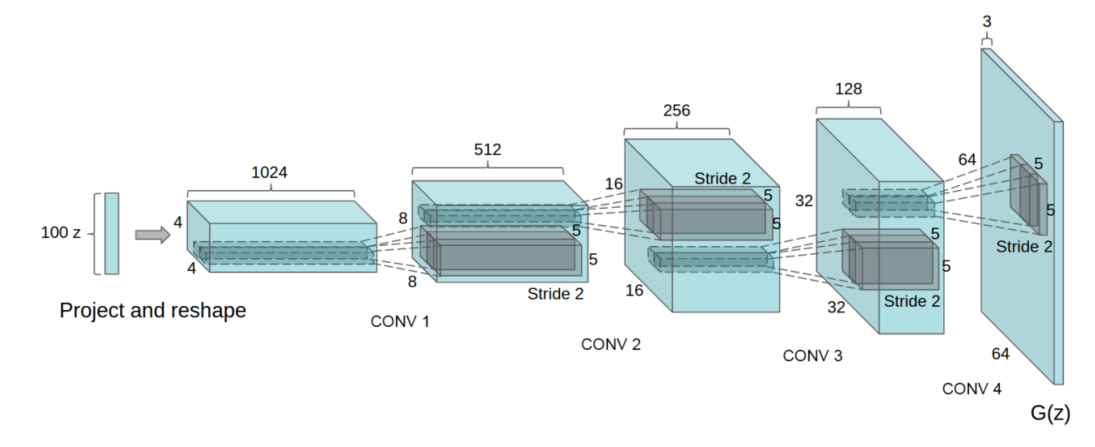
判别器模型
判别器没有什么好说的,就是传统的卷积结构