爬虫笔记之——selenium安装与使用(1)
- 一、安装环境
- 1、下载Chrome浏览器驱动
- (1)查看Chrome版本
- (2)下载相匹配的Chrome驱动程序
- 地址:https://chromedriver.storage.googleapis.com/index.html
- 2、学习使用selenium
- (1)安装selenium,用pip install selenium -i 源镜像
- (2)开始编程
- 3、页面元素定位
- (1)通过ID值定位
- driver.find_element(By.ID,"kw")
- (2)通过CLASS值定位
- driver.find_element(By.CLASS_NAME,"s_ipt")
- (3)通过NAME定位
- driver.find_element(By.NAME,"wd")
- (4)通过TAG_NAME定位
- driver.find_element(By.TAG_NAME,"div")
- (5)通过XPATH语法定位
- driver.find_element(By.XPATH,"//*[@id="su"]").click()
- (6)通过CSS语法定位
- driver.find_element(By.CSS_SELECTOR,"#su").click()
- (7)通过文本定位--精确定位
- driver.find_element(By.LINKE_TEXT,"在希望的田野上")
- (8)通过部分文本定位--模糊定位
- driver.find_element(By.PRATIAL_LINK_TEXT,"希望")
- 4、操作表单元素及其他操作
- (1)输入内容、清除内容、鼠标单击
- (2)行为链
- (3)动作链
- (4)点击操作(继续学习行为链)
- 注意:鼠标滑动、拖拽是动作链,一连串的点击是行为链。
- 5、行为链中的等待(Explicit Waits)
- 认识selenium
- Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7—11),Firefox,Safari,Google,Chrome,Opera,Edge等。
一、安装环境
1、下载Chrome浏览器驱动
(1)查看Chrome版本
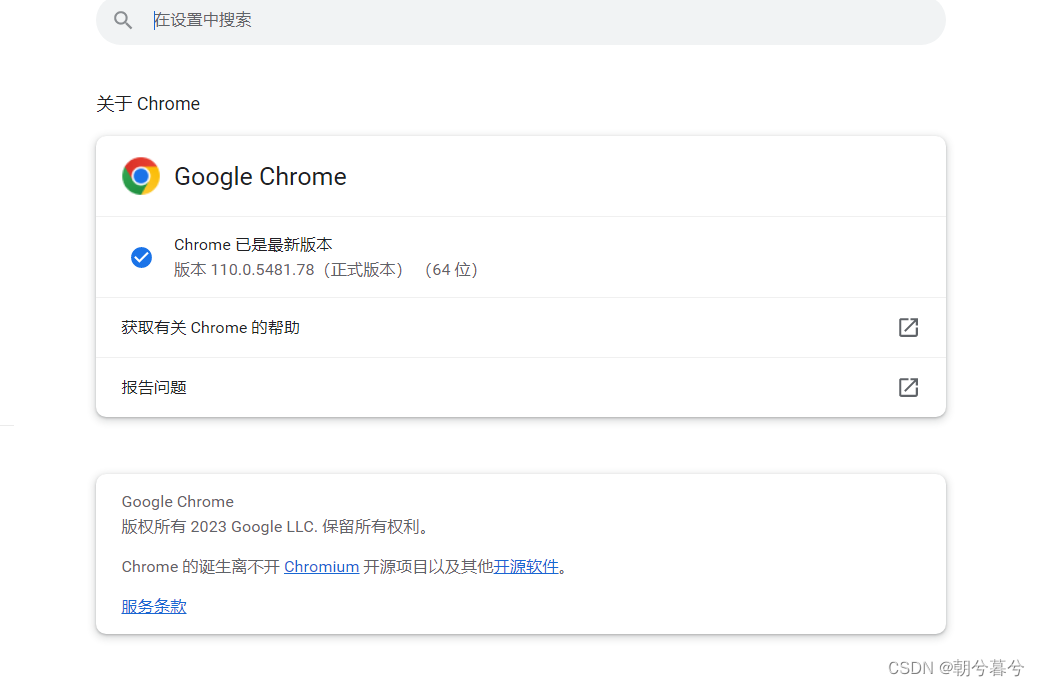
(2)下载相匹配的Chrome驱动程序
-
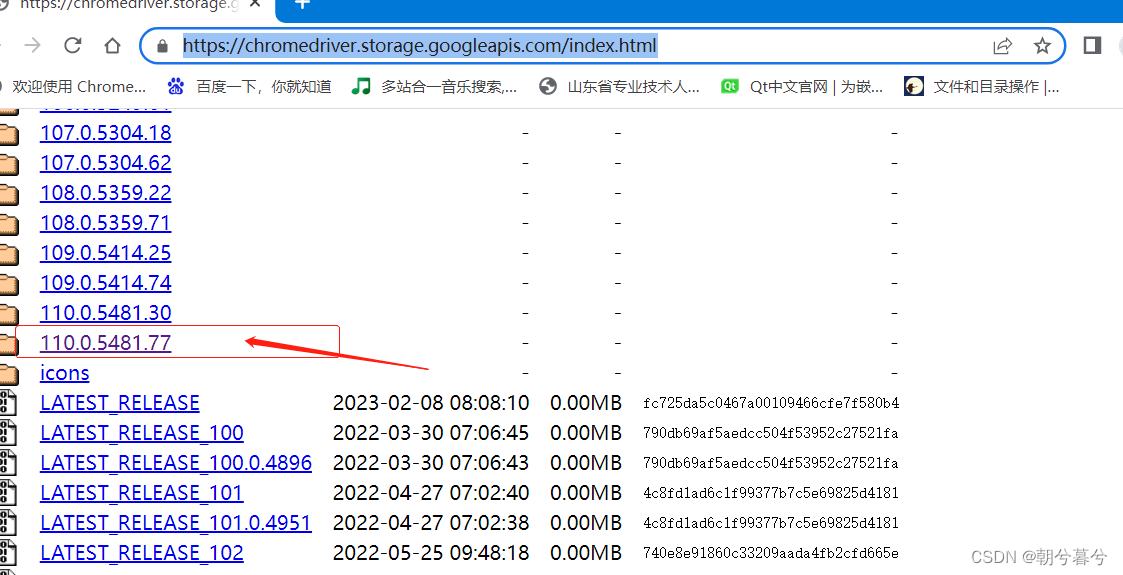
地址:https://chromedriver.storage.googleapis.com/index.html
- 打开之后,找上面查到的最新地址,如图
- 然后,把下载的压缩包解压,得到chromedriver.exe文件,复制到Python安装目录下,双击安装。
- 打开cmd命令提示符,输入Chromedriver,之后显示如下图样,就代表安装成功了。
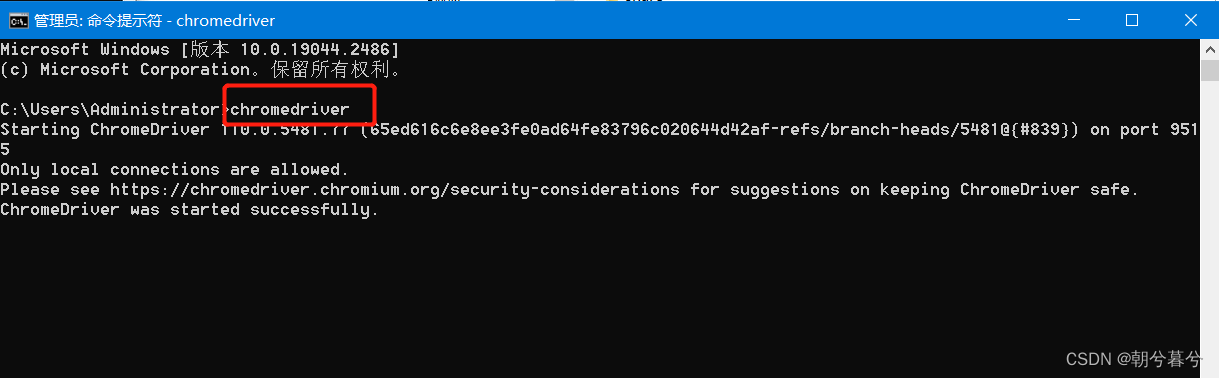
- 以上是Chrome浏览器的驱动安装,其他浏览器可以对应下载。
2、学习使用selenium
(1)安装selenium,用pip install selenium -i 源镜像
(2)开始编程
-
下面是VSCode里面录入的代码,其中定义浏览器的时候,会自动弹出各种浏览器模式
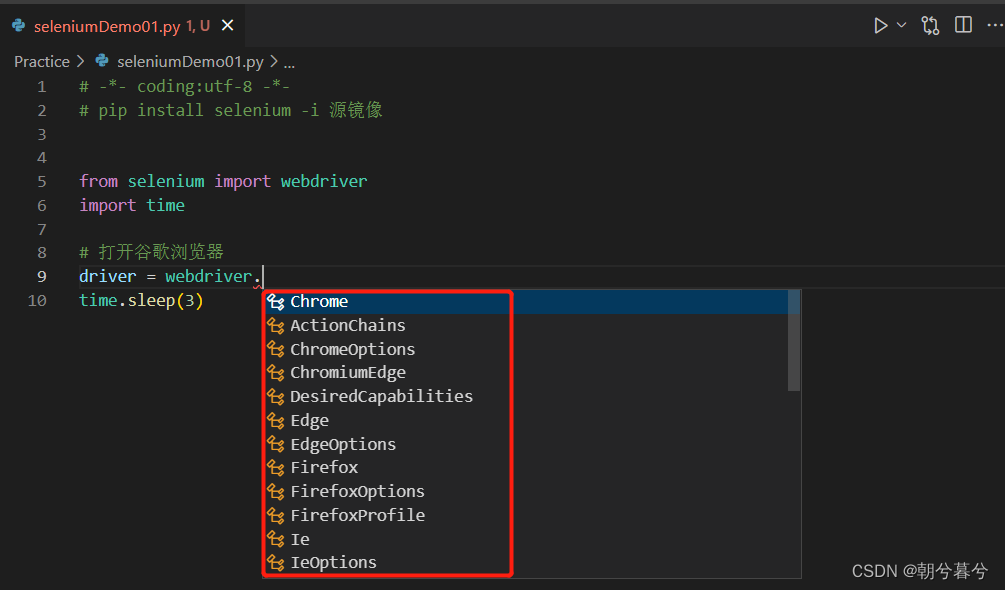
-
运行此时的程序,会弹出浏览器界面3秒钟。此时,并没有打开任何的页面
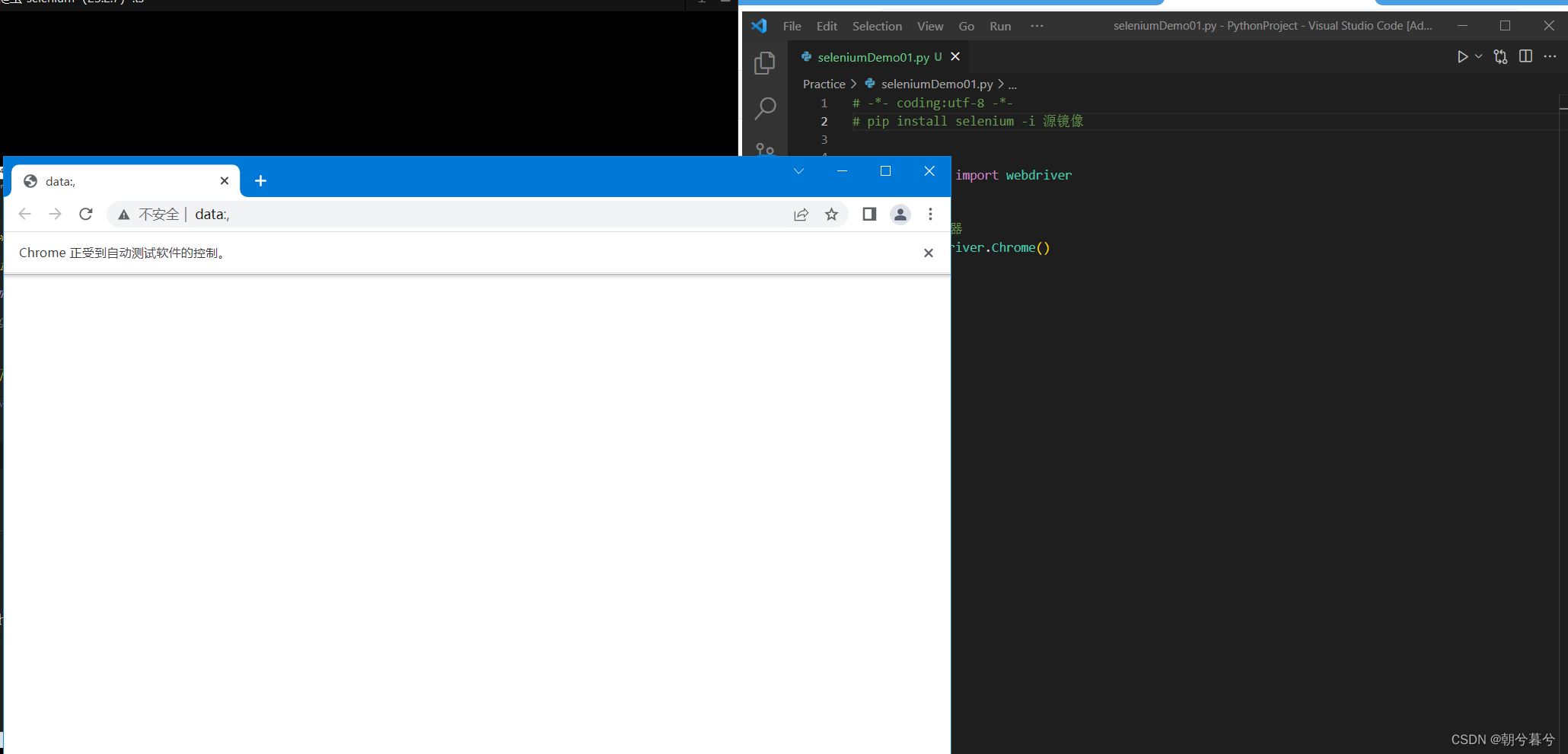
-
继续编写代码,并点击运行,打开一个百度页面,如下图。
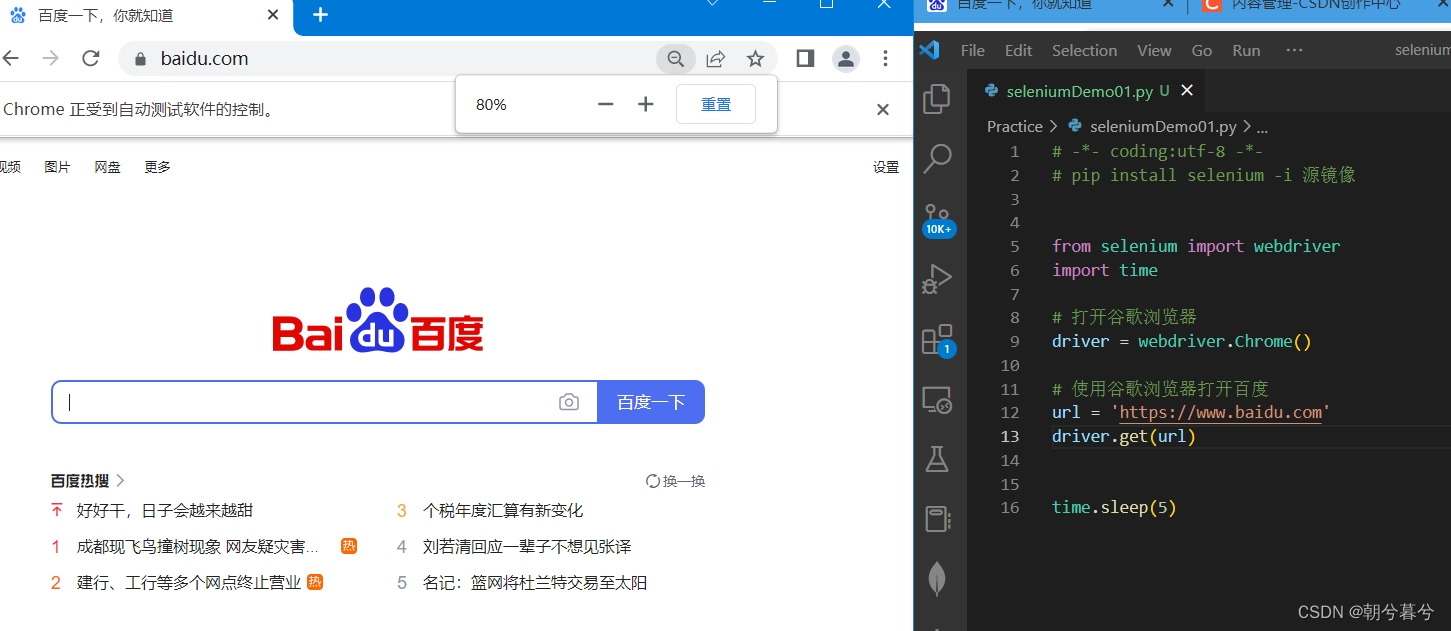
-
再获取百度首页的源代码,如下图。
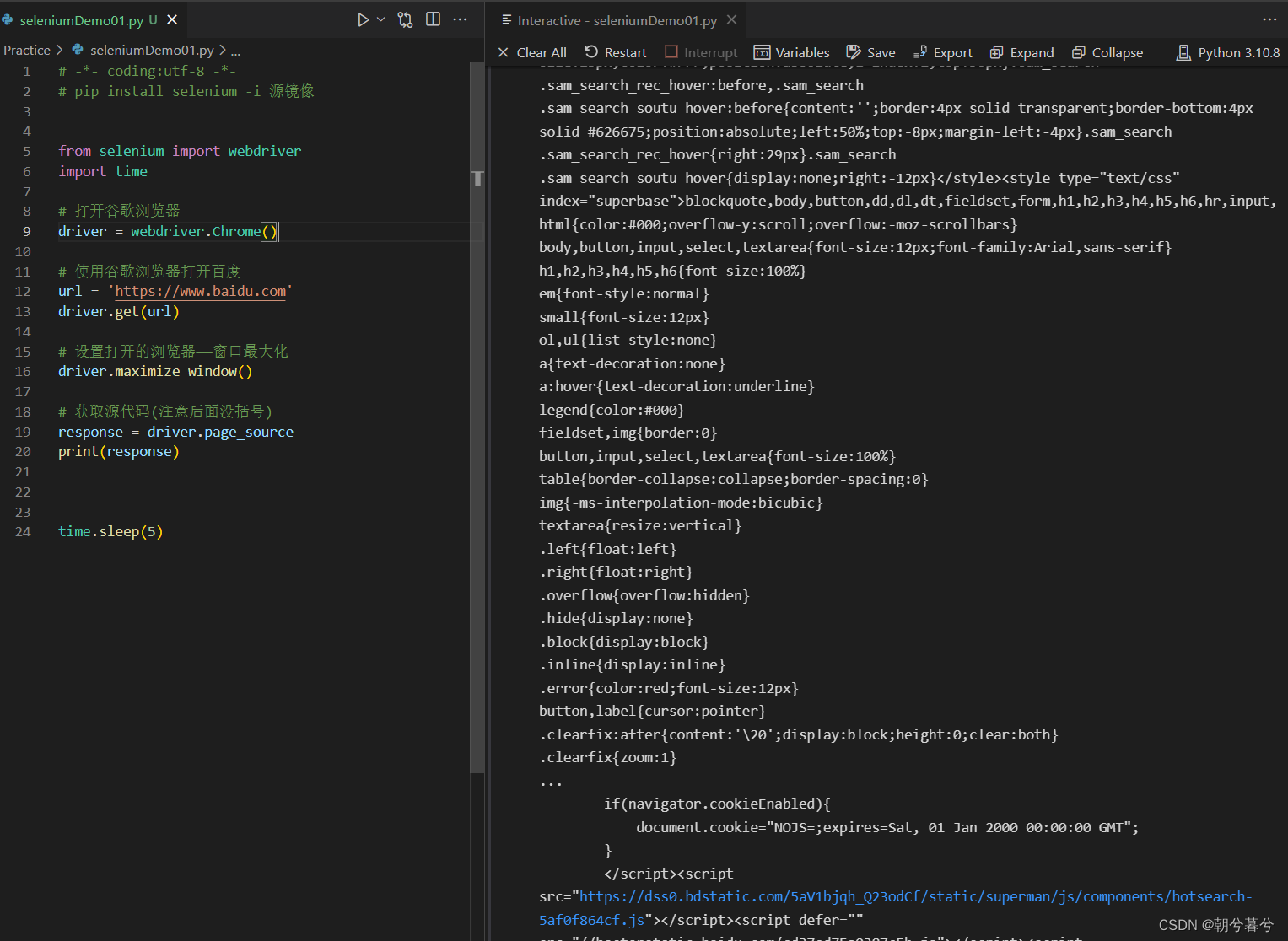
-
上面完整代码如下,最后关闭。
# -*- coding:utf-8 -*- # pip install selenium -i 源镜像 from selenium import webdriver import time # 打开谷歌浏览器 driver = webdriver.Chrome() # 使用谷歌浏览器打开百度 url = 'https://www.baidu.com' driver.get(url) # 设置打开的浏览器——窗口最大化 driver.maximize_window() # 获取源代码(注意后面没括号) response = driver.page_source print(response) time.sleep(5) driver.close()
3、页面元素定位
(1)通过ID值定位
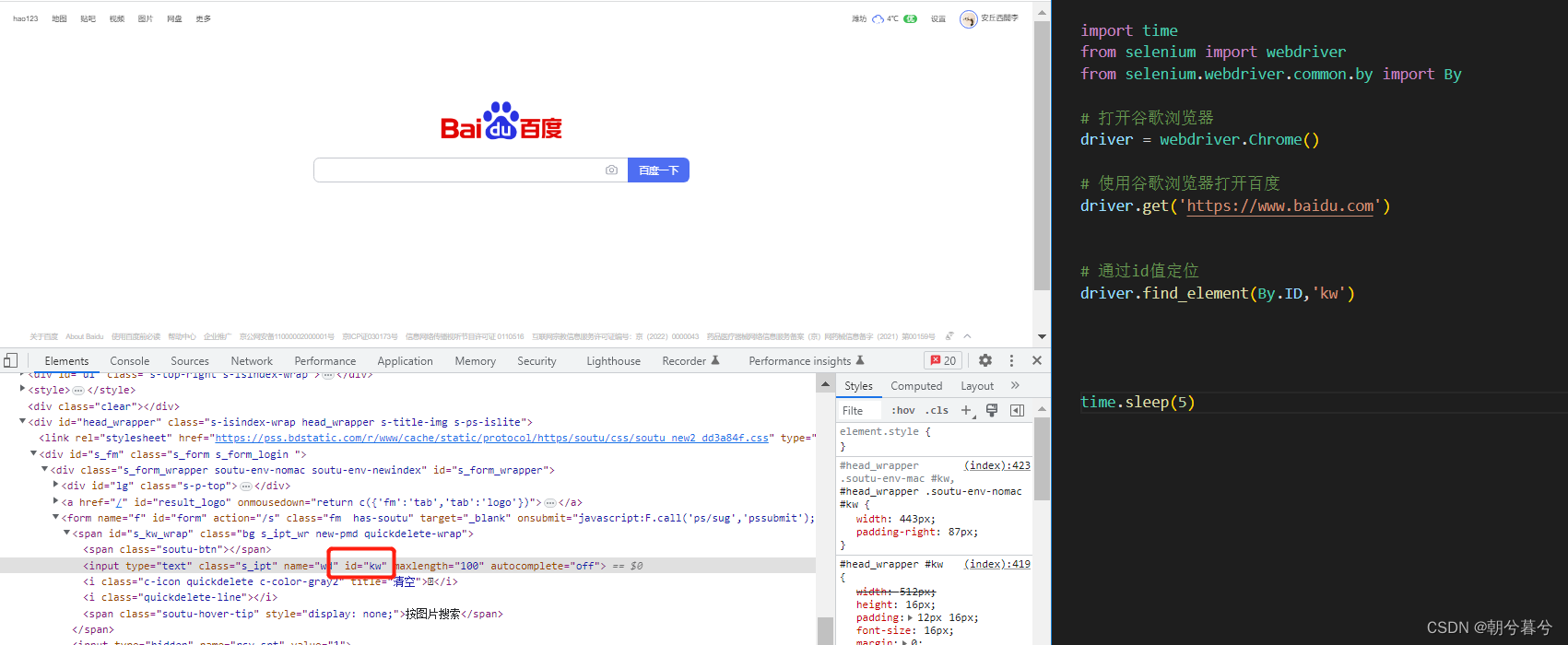
(2)通过CLASS值定位
(3)通过NAME定位
(4)通过TAG_NAME定位
(5)通过XPATH语法定位
-
driver.find_element(By.XPATH,“//*[@id=“su”]”).click()
- 通过复制得到“//*[@id=“su”]”,然后粘贴到上面代码中
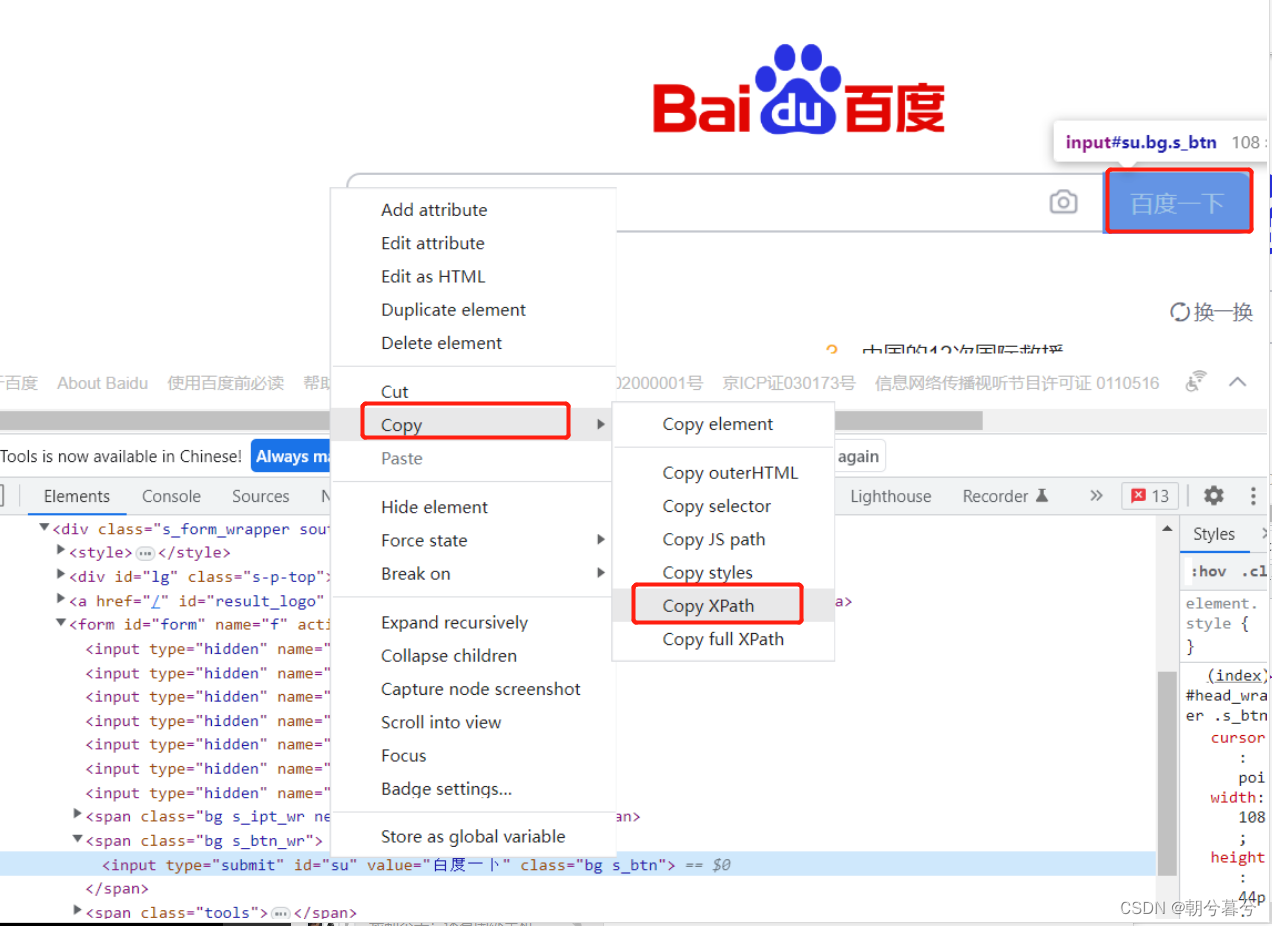
- 代码如下:
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By # 打开谷歌浏览器 driver = webdriver.Chrome() # 使用谷歌浏览器打开百度 driver.get('https://www.baidu.com') # 通过CLASS值定位,此处的class值是“s_ipt” driver.find_element(By.CLASS_NAME,'s_ipt').send_keys("大家好") # 通过XPATH语法定位“百度一下”按钮,并点击 driver.find_element(By.XPATH,'//*[@id="su"]').click() time.sleep(5)- 运行后,自动实现搜索,效果如下。
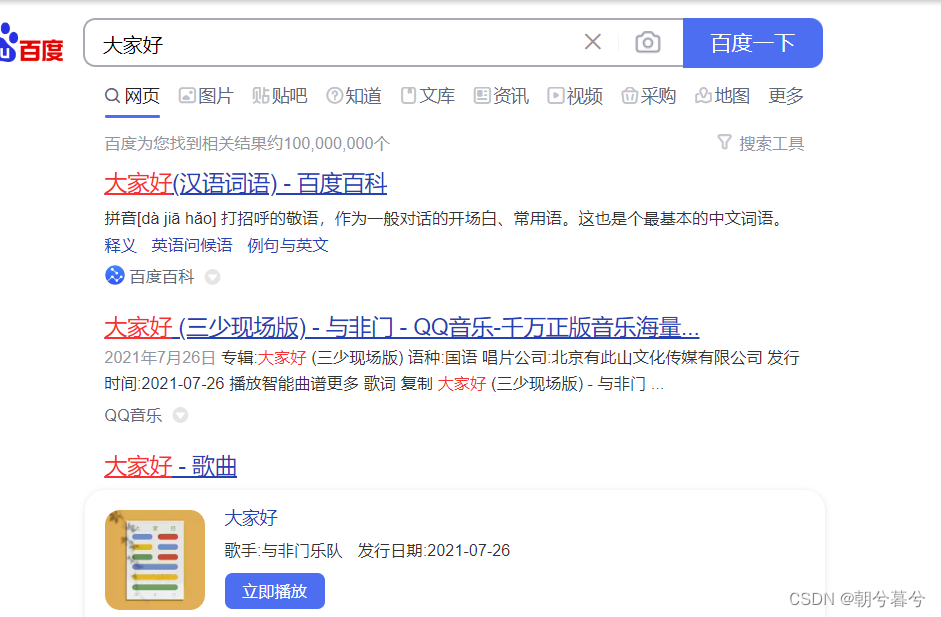
- 运行后,自动实现搜索,效果如下。
(6)通过CSS语法定位
(7)通过文本定位–精确定位
(8)通过部分文本定位–模糊定位
4、操作表单元素及其他操作
(1)输入内容、清除内容、鼠标单击
# 输入内容
send_keys('python')
# 清除输入框内容
clear()
# 鼠标单击
click()
(2)行为链
- 在用selenium操作页面时,有时要分为很多步骤,那么这个时候可以用鼠标行为链类ActionChains来完成。
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains # 打开谷歌浏览器 driver = webdriver.Chrome() # 使用谷歌浏览器打开百度 driver.get('https://www.baidu.com') # 定位搜索框 inputtag = driver.find_element(By.ID,"kw") # 百度一下按钮 submittag = driver.find_element(By.ID,"su") # 建立行为链 actions = ActionChains(driver) # 给搜索框发送数据 actions.move_to_element(inputtag) actions.send_keys_to_element(inputtag,'python') # 选中提交按钮并提交 actions.move_to_element(submittag) actions.click(submittag) # 统一执行 actions.perform() time.sleep(5)
(3)动作链
- ActionChains方法列表
click(on_element=None)——单击鼠标左键 click_and_hold(on_element=None) ——点击鼠标左键,不松开 context_click(on_element=None) ——点击鼠标右键 double_click(on_element=None)——双击鼠标左键 drag_and_drop(source, tanget)——拖拽到某个元素然后松开 key_down(value, element=None)——按下某个键盘上的键 key_up(value, element=None)——松开某个键 move_to_element(to_element)——鼠标移动到某个元素 perform() ——执行链中的所有动作 release(on_element=None) ——在某个元素位界松开鼠标左键 send_keys(*keys_to_send) ——发送某个键到当前焦点的元素 send_keys_to_element(element,*keys_to_send)——发送某个键到指定元素 - 举例说明鼠标移动。
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Chrome() driver.get('http://sahitest.com/demo/mouseover.htm') # 定位到显示文本框,还是用xpath方法 display = driver.find_element(By.XPATH,'//input[@value="Write on hover"]') # 定位到隐藏文本框 hide = driver.find_element(By.XPATH,'//input[@value="Blank on hover"]') action = ActionChains(driver) time.sleep(3) action.move_to_element(display).perform() time.sleep(3) action.move_to_element(hide).perform() time.sleep(3) - 效果如图。
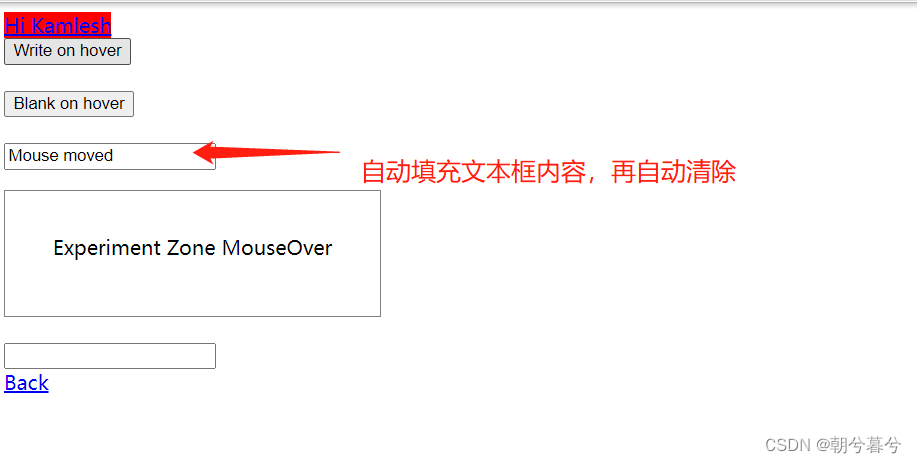
- 举例说明鼠标拖拽的几种情况。
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Chrome() driver.get("http://sahitest.com/demo/dragDropMooTools.htm") dragger = driver.find_element(By.XPATH, '//div[@id="dragger"]') item1 = driver.find_element(By.XPATH,'//html/body/div[2]') item2 = driver.find_element(By.XPATH,'//html/body/div[3]') item3 = driver.find_element(By.XPATH,'//html/body/div[4]') item4 = driver.find_element(By.XPATH,'//html/body/div[5]') action = ActionChains(driver) # 下面是直接拖拽的动作 action.drag_and_drop(dragger, item1).perform() time.sleep(3) # 下面是先点击目标不松开,再定位item2位置松开 action.click_and_hold(dragger).release(item2).perform() time.sleep(3) # 下面是先点击目标不松开,然后滑动到item3位置松开 action.click_and_hold(dragger).move_to_element(item3).release().perform() time.sleep(3) action.drag_and_drop(dragger, item4).perform() time.sleep(3) driver.quit() - 结果就是每过1秒,拖拽一个蓝色的方框,到目的地。如图。

(4)点击操作(继续学习行为链)
- 示例网站:http://sahitest.com/demo/clicks.htm
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Chrome() driver.get("http://sahitest.com/demo/clicks.htm") # 单击按钮 click_one = driver.find_element(By.XPATH, '//input[@value="click me"]') # 双击按钮 click_dbl = driver.find_element(By.XPATH, '//input[@value="dbl click me"]') # 右击按钮 click_rgt = driver.find_element(By.XPATH, '//input[@value="right click me"]') # 定义下面的一个行为链,完成单击,双击,右击 ActionChains(driver).click(click_one).double_click(click_dbl).context_click(click_rgt).perform() time.sleep(5) - 效果如图。
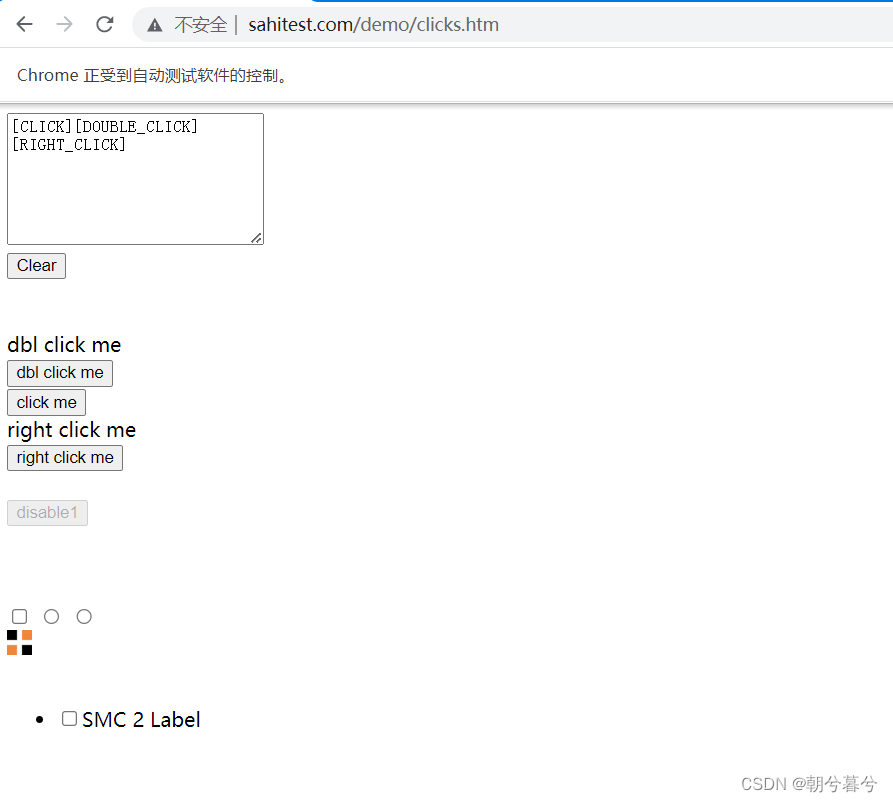
-
注意:鼠标滑动、拖拽是动作链,一连串的点击是行为链。
5、行为链中的等待(Explicit Waits)
- 示例代码。
# -*- coding:utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.common import TimeoutException from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get("https://www.baidu.com") # 定义一个递归函数 def search(): try: input = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "kw"))) input.send_keys("大家好") time.sleep(10) except TimeoutException: # 重复进入函数尝试完成 return search() if __name__ =='__main__': search()